Ein praxistauglicher Rahmen zur Bewertung von GPT Image 2 mit harten Gates, semantischen Checks, Bildmetriken, Human Review, Robustheitstests und CI-fähigem Reporting.
Die Auswertung der GPT Image 2-Ausgabe quality ist nicht dasselbe wie die Frage, ob ein Bild beeindruckend aussieht. Ein schönes Bild kann immer noch fail den Job machen, wenn der erforderliche Text falsch geschrieben ist, eine product Beschriftung geändert wird, eine UI-Schaltfläche fehlt, ein Logo verschiebt oder eine Bearbeitung Teile des Bildes verändert, die eigentlich unberührt bleiben sollten.
Für Teams ist die bessere Frage: Kann GPT Image 2 dieses workflow zuverlässig genug abschließen, um es auszuliefern?
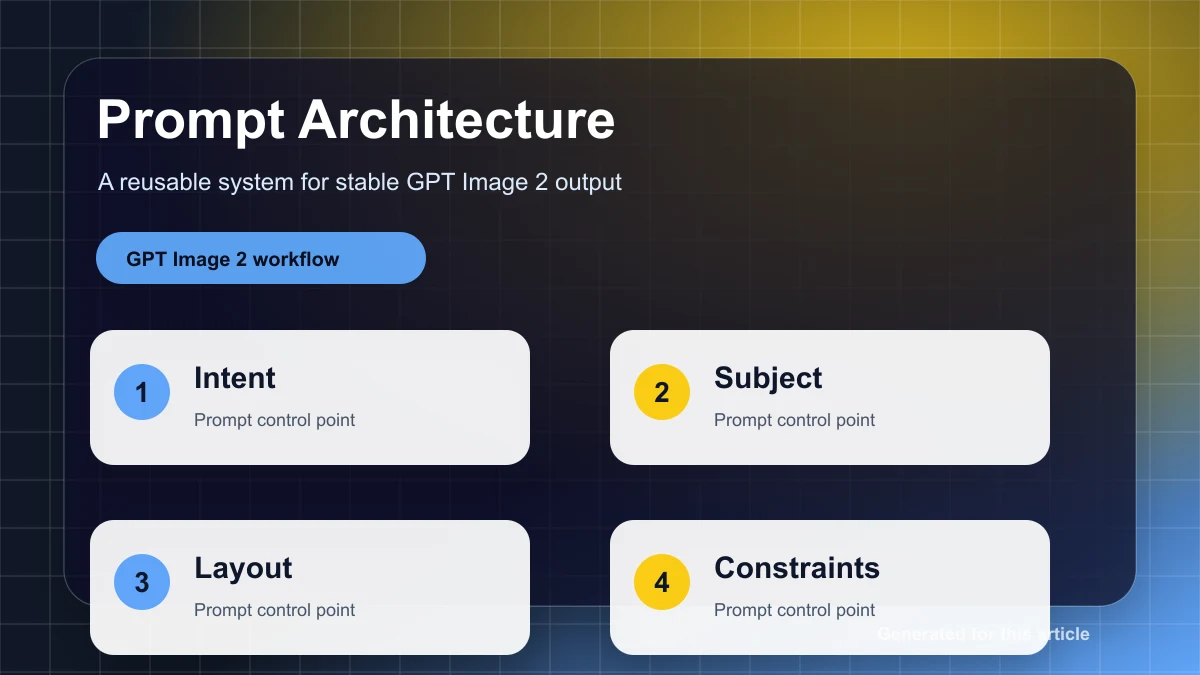
Diese Frage erfordert ein strukturiertes Bewertungssystem. Der nützlichste Ansatz ist ein dreischichtiger model:
- Harte Gates für nicht verhandelbare Anforderungen wie genauer Text, Sicherheit, erforderliche Objekte und Bearbeitungsort.
- Bewertung auf Dimensionsebene für semantische Ausrichtung, visuelle quality, räumliche Genauigkeit, Markenkonsistenz und Erhaltung.
- Menschliche Präferenz oder A/B review für Entscheidungen, bei denen automatisierte Metriken nicht ausreichen.
Reduzieren Sie Bild quality nicht auf eine durchschnittliche Punktzahl. Ein einzelner Score verbirgt den eigentlich wichtigen Fehlermodus. Ein Marketingplakat mit einer visuellen Bewertung von 4,6/5, aber einem falschen Zeichen in der Überschrift ist nicht „fast gut“; Es handelt sich um eine ausgefallene Produktionsanlage.
Diese Checkliste richtet sich an Käufer, Ersteller, product-Teams, Designteams, QA-Teams und Technikteams, die GPT Image 2-Ausgaben in realen Arbeitsabläufen vergleichen müssen. Es behält die praktischen Schwellenwerte und die Bewertungsstruktur bei, die bei seriösen model-Bildtests verwendet werden, und vermeidet gleichzeitig die häufige Falle, alten Metriken wie FID oder dem Inception Score zu sehr zu vertrauen.
Beginnen Sie mit dem Workflow, nicht mit dem Modell
Definieren Sie das Szenario, bevor Sie Metriken auswählen. Ein product-Bild, ein mobiles UI-Mockup, ein Poster, ein Charakterblatt und ein medical-Lehrdiagramm funktionieren nicht auf die gleiche Weise fail.
Wenn Ihr Datensatz noch nicht angegeben ist, teilen Sie die Auswertung zunächst in scenario-Slices auf. Entscheiden Sie dann, welche Prüfungen für jedes Segment wichtig sind.
| Domäne | Häufige GPT Image 2-Anwendungsfälle | Erste quality-Prüfungen | Notizen |
|---|---|---|---|
| Produkt | Weißer Hintergrund product-Aufnahmen, Verpackungen, Anzeigen, Marken-Asset-Bearbeitungen | Exakter Text, vollständige Beschriftungen, saubere Kanten, lokale Bearbeitungen, die nichts verschütten | Am besten geeignet für Paired-Edit-Tests und Hard-Gates |
| UX | UI-Modelle, Flow-Bildschirme, Diagramme der Informationsarchitektur, Bilder zum Kopieren von Schaltflächen | Erforderliche Komponenten, Layouthierarchie, genauer Schaltflächentext, Benutzerfreundlichkeit | Text-Gates sollten vor Schönheitsbewertungen kommen |
| Kreativ | Werbe-Keyvisuals, Comics, Storyboards, Poster, Charakterblätter | Stilkonsistenz, narrative Kontinuität, lesbarer Text, Marken- oder Charakterkonsistenz | Menschliche Vorlieben sind äußerst wertvoll |
| Medizinisch | Lehrreiche Illustrationen, synthetische Bilder im medizinischen Stil, Falldiagramme | Privatsphäre, nahezu doppeltes Risiko, Faktizität, klinisch relevante Attribute | Anwendungsfall- und Regulierungsstandards müssen separat kalibriert werden |
| Industriell | Geräteetiketten, Wartungsillustrationen, technische Tafeln, Konzeptvisualisierungen | Text- und Zeichengenauigkeit, räumliche Beziehungen, Material- und Strukturplausibilität | Branchentoleranzen sollten vor der Markteinführung definiert werden |
Wenn das Team nur über begrenzte Ressourcen verfügt, beginnen Sie mit vier Slices:
- Textlastige Poster
- UI-Modelle
- Lokale Bildbearbeitung
- Komplexe Komposition prompts
Diese vier Kategorien decken viele der Fehler auf, die bei der Produktion von Bedeutung sind: falsch geschriebener Text, fehlende Elemente, schwaches räumliches Denken, übermäßige Bearbeitung und oberflächliche prompt-Befolgung.
Trennen Sie Generierungstests von Bearbeitungstests
Die GPT Image 2-Bewertung sollte in zwei Abschnitte aufgeteilt werden.
Generierungstests beginnen mit einem prompt und haben kein genaues Referenzbild. Die zentrale Frage ist, ob das Bild den prompt folgt: Objekte, Attribute, Beziehungen, Anzahl, Stil, Text und Sicherheitsbeschränkungen.
Bearbeitungstests beginnen mit einem Eingabebild, manchmal mit einer Maske oder einem Zielbereich. Die zentrale Frage ist, ob die gewünschte Änderung stattgefunden hat, während alles andere stabil geblieben ist. Beim Bearbeiten von quality geht es nicht nur um die Frage: „Sieht das endgültige Bild gut aus?“ Es heißt auch: „Hat das model Identität, Layout, Logoform, product-Details und unberührte Bereiche bewahrt?“
Für beide Strecken Versionierung bei jedem Lauf. Laut der offiziellen OpenAI-Dokumentation zur Bildgenerierung workflows sollten Teams auf model-Konfigurationsfelder wie Ausgabe size, quality, Format und Komprimierung achten, sofern verfügbar. Vergleichen Sie keine Läufe, es sei denn, diese Einstellungen, Vorverarbeitungsregeln und prompt-Versionen sind gesperrt.
Lagern Sie mindestens:
| Feld | Warum es wichtig ist |
|---|---|
| model- und model-Version | Verhindert, dass versteckte model-Änderungen wie prompt-Änderungen aussehen |
| prompt-Version | Ermöglicht eine Regressionsanalyse |
| size und quality | Die Ausgabe quality kann sich je nach Auflösung und quality-Einstellungen verschieben |
| Ausgabeformat und Komprimierung | Die JPEG/WebP-Komprimierung kann OCR, Metriken und visuelle Artefakte verändern |
| Geben Sie den Bild-Hash ein | Erforderlich für die Reproduzierbarkeit der Bearbeitung |
| Referenzsatz-Hash | Erforderlich für gepaarte Tests |
| seed-Richtlinie | Wird benötigt, wenn mehrere Kandidaten pro prompt verglichen werden |
| Richter prompt Version | Automatisierte Richter sind Teil des Messsystems |
| menschliche Codebuchversion | Annotatorregeln müssen stabil sein |
| CI Job und Git-Commit | Macht die Entscheidung überprüfbar |
Das dreischichtige Qualitätsrahmenwerk
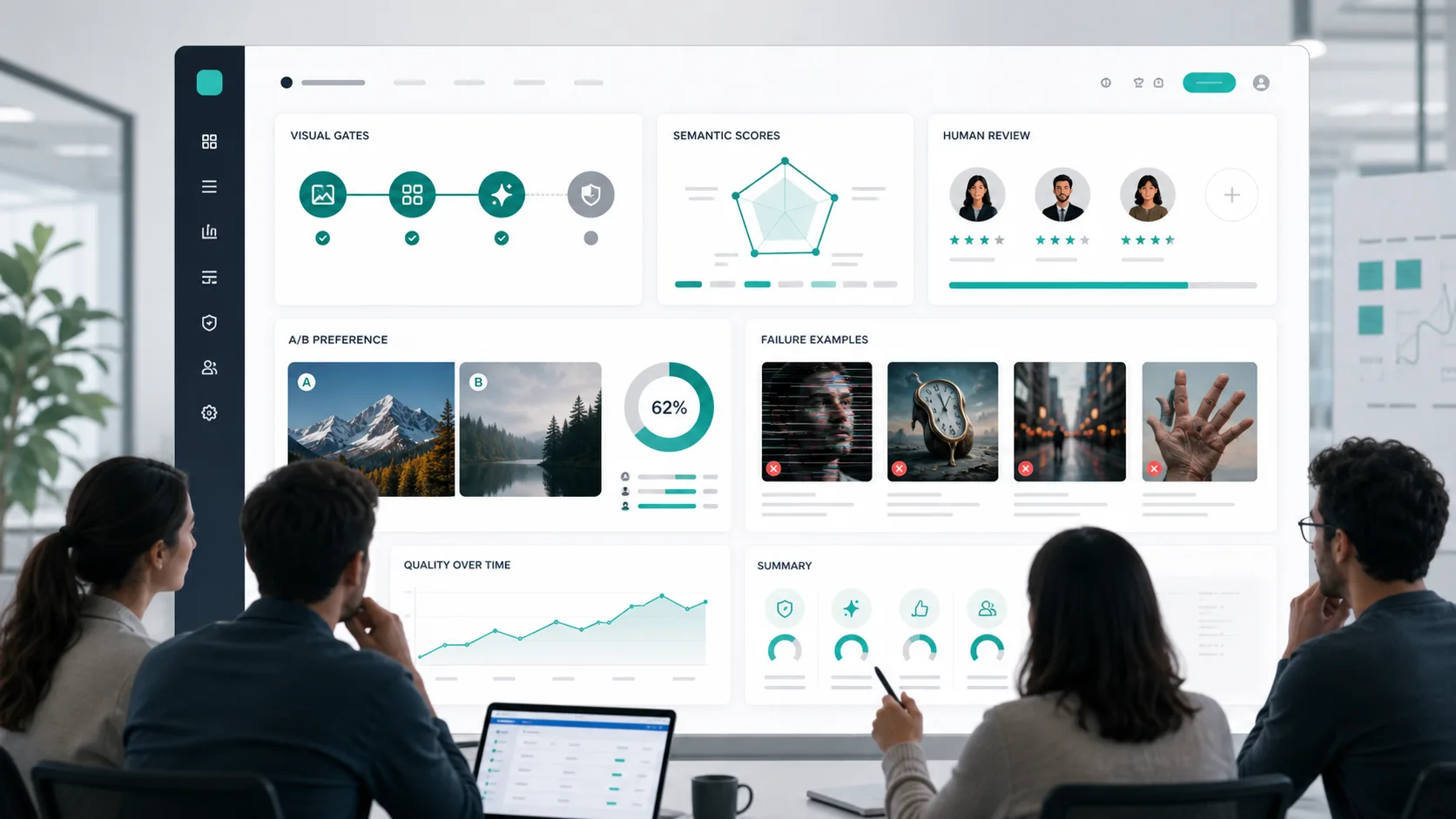
Schicht 1: Harte Gates
Bei Hard Gates handelt es sich um Pass/Fail-Prüfungen. Sie sollten für Anforderungen verwendet werden, die nicht verhandelbar sind.
Gängige harte Tore:
- Der erforderliche Text ist genau richtig.
- Erforderliche Objekte sind vorhanden.
- Verbotene Objekte oder unsichere Inhalte fehlen.
- Das Bild verstößt nicht gegen Marken- oder Datenschutzbestimmungen.
- Bei einer Bearbeitungsaufgabe bleiben unberührte Bereiche unverändert.
- Ein product-Label, Logo, Gesicht oder identitätsrelevanter Bereich bleibt erhalten.
- Die Ausgabe erfüllt die erforderlichen Format-, Hintergrund- und Zuschnittbeschränkungen.
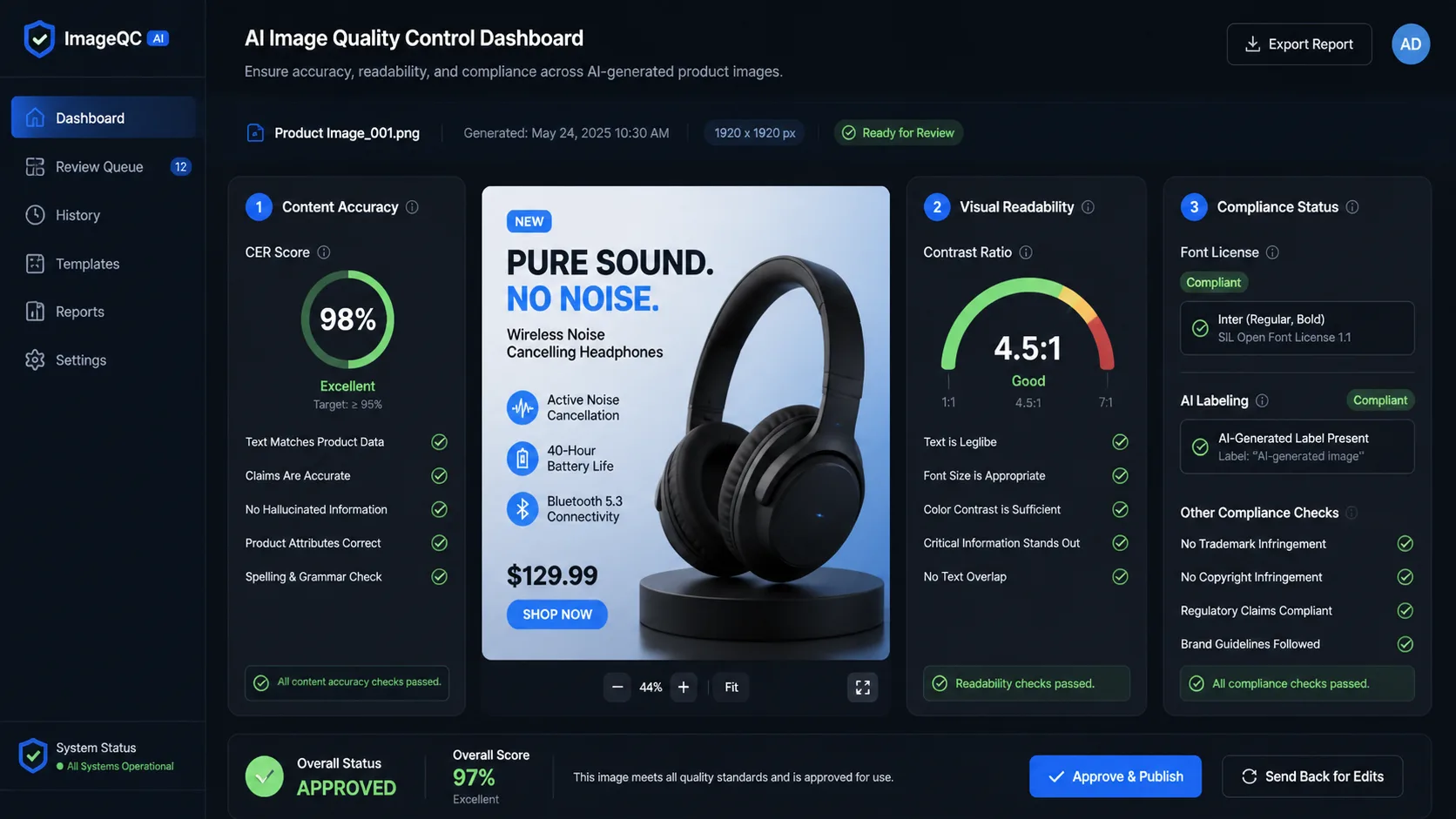
Textlastige Assets verdienen eine besondere Behandlung. Wenn prompt den Ausdruck „Place Order“ erfordert und das Bild „Place Odrer“ sagt, schlägt die Ausgabe fehl. Vergleichen Sie das nicht mit der visuellen Qualität.
Ebene 2: Dimensionswerte
Bewerten Sie nach harten Gates die Ausgabe über die Dimensionen hinweg. Eine Skala von 0–5 oder 1–5 funktioniert, wenn jeder Punkt klar definiert ist.
Empfohlene Abmessungen:
| Dimension | Was soll ich fragen? | Standardziel |
|---|---|---|
| Semantische Ausrichtung | Bringt das Bild die Kernabsicht von prompt zum Ausdruck? | Mindestens 4/5 Durchschnitt |
| Objektpräsenz | Sind alle wichtigen Objekte sichtbar? | Schlüsselobjektrückruf mindestens 0,95 |
| Attributgenauigkeit | Sind Farben, Materialien, Mengen und Etiketten an die richtigen Objekte gebunden? | Mindestens 0,90 |
| Genauigkeit der räumlichen Beziehung | Sind links/rechts, oben/unten, vorne/hinten und die Okklusion korrekt? | Mindestens 0,90 |
| Textwiedergabe | Ist der erforderliche Text lesbar und genau? | 100 % für den erforderlichen Text |
| Ort bearbeiten | Hat sich nur die gewünschte Region geändert? | Mindestens 4/5 Durchschnitt |
| Identitäts- oder Markenerhaltung | Sind Gesichter, Logos, Typ und product-Identität stabil geblieben? | Mindestens 4/5 Durchschnitt |
| Visuell quality | Ist das Bild artefaktfrei und produktionstauglich? | Mindestens 4/5 Durchschnitt |
Der wichtige Punkt ist, dass quality zerlegt wird. Ein model ist möglicherweise stark im visuellen Feinschliff, aber schwach in den räumlichen Beziehungen. Ein anderer bewahrt möglicherweise Eingabebilder gut, hat aber Schwierigkeiten mit der exakten Typografie. Die Auswertung soll diese Unterschiede sichtbar machen.
Ebene 3: Menschliche Präferenz und A/B-Tests
Menschliche Präferenz review ist immer noch notwendig. Automatisierte Metriken sind nützlich, aber sie lassen viele Produktionsaspekte außer Acht: Geschmack, Ausgewogenheit des Layouts, Markentauglichkeit, glaubwürdige Materialwiedergabe und ob sich ein Design fertig anfühlt.
Für A/B-Tests können Sie die linke/rechte Platzierung randomisieren, die model-Identität ausblenden und Gleichstände zulassen. Geben Sie die win-Rate mit Konfidenzintervallen an, anstatt nur zu sagen: „Modell B fühlte sich besser an.“
Verwenden Sie A/B-Tests für:
- Auswahl zwischen GPT Image 2-Einstellungen.
- Vergleich von GPT Image 2 mit einem etablierten Workflow.
- Überprüfung von creative quality nach Passieren harter Tore.
- Entscheiden, ob eine prompt-Revision das Ergebnis verbessert hat.
Praktische Metrikauswahl
Verwenden Sie nicht jede Bildmetrik, nur weil sie existiert. Wählen Sie Metriken basierend auf dem Fehlermodus aus.
| Metrisch | Richtung | Beste Verwendung | Hauptstärke | Hauptschwäche | Praktische Schwelle |
|---|---|---|---|---|---|
| FID | Niedriger ist besser | Regression auf Verteilungsebene | Historisch gesehen häufig bei generierten Bildverteilungen | Schlechte Probeneffizienz; empfindlich gegenüber Vorverarbeitung; schwach für moderne prompt-spezifische Aufgaben | Verwenden Sie keinen absoluten Freigabeschwellenwert. Vergleichen Sie nur mit demselben Referenzsatz und derselben Vorverarbeitung |
| Inception Score | Höher ist besser | Überprüfungen der Legacy-No-Reference-Generierung | Einfach | Nicht mit der tatsächlichen Datenverteilung vergleichbar; kann eine detaillierte Rangfolge irreführen | Nicht als Entriegelungstor verwenden |
| LPIPS | Niedriger ist besser | Paarweise Bearbeitungen und Rekonstruktionen | Eher ein Wahrnehmungsunterschied als ein Pixelfehler | Benötigt eine gepaarte Referenz; nicht vergleichbar mit unabhängigen Aufgaben | <= 0,20 akzeptabel, <= 0,10 stark |
| CLIPScore | Höher ist besser | Sofortige Bildausrichtung | Einfach, kein reference image erforderlich | Kann sich wie eine Notenbank voller Wörter verhalten und komplexe Zusammenhänge übersehen | Verwenden Sie relative Schwellenwerte, z. B. nicht schlechter als 97 % des Ausgangswerts |
| PSNR | Höher ist besser | Bearbeitungstreue und Rekonstruktion | Günstig und leicht zu interpretieren | Schlechte Wahrnehmungsempfindlichkeit | >= 30 dB akzeptabel, >= 35 dB stark |
| SSIM | Höher ist besser | Bauliche Erhaltung | Besser als PSNR für die Struktur | Weniger nützlich für Stiländerungen und feine Texturen | >= 0,90 akzeptabel, >= 0,95 stark |
| DISTS | Niedriger ist besser | Wahrnehmungsergänzung | Robuster gegenüber Textur- und Strukturkompromissen | In Produktionsstapeln weniger verbreitet als SSIM oder LPIPS | Verwendung als relative Regression, nicht als absolutes Tor |
FID und Inception Score sollten nicht das primäre Release-Gate für GPT Image 2-Workflows sein. Sie können helfen, die Abweichung auf Verteilungsebene im Laufe der Zeit zu überwachen, geben aber keine Auskunft darüber, ob ein bestimmtes prompt befolgt wurde, ob eine Schaltflächenbeschriftung korrekt ist oder ob durch eine Bearbeitung der falsche Teil eines product-Bildes geändert wurde.
Verwenden Sie für semantische Prüfungen nach Möglichkeit die Auswertung im Frage-Antwort- oder Zerlegungsstil:
- Prüfungen im TIFA-Stil auf Objekt-, Attribut-, Anzahl- und Sachkonsistenz.
- Überprüfungen im VQAScore-Stil für die Konsistenz von Eingabeaufforderungsbildern durch visuelle Beantwortung von Fragen.
- Überprüfungen im GenEval-Stil auf Objektpräsenz, -anzahl, -farbe und -position.
- Prüfungen im VISOR-Stil für räumliche Beziehungen.
- Überprüfungen im I-HallA-Stil auf sachliche Halluzinationen im Bildinhalt.
Diese Ansätze sind wertvoll, weil sie Misserfolge aufschlüsseln. Anstelle einer Ähnlichkeitsbewertung erhalten Sie Antworten wie „Das Objekt ist vorhanden, die Farbe ist falsch und die räumliche Beziehung ist fehlgeschlagen.“
Checkliste für Semantik, Sicherheit und Robustheit
Nutzen Sie diese Tabelle als praktische Vorgabe.
| Überprüfen | Automatisiertes Signal | Menschliche review-Frage | Standardschwellenwert |
|---|---|---|---|
| Ausrichtung der Beschriftung | CLIPScore oder VQAScore-Richter | Bringt das Bild die Kernabsicht von prompt zum Ausdruck? | Nicht weniger als 97 % des Ausgangswerts |
| Präsenz des Schlüsselobjekts | TIFA- oder GenEval-ähnliche Prüfungen | Sind alle benötigten Objekte vorhanden? | Rückruf >= 0,95 |
| Attributbindung | Prüfungen im TIFA-, GenEval- oder T2I-CompBench-Stil | Sind Farbe, Material, Anzahl und Text an das richtige Objekt gebunden? | Genauigkeit >= 0,90 |
| Raumbeziehungen | VISOR oder VQA prompts | Sind links/rechts, oben/unten, vorne/hinten und die Okklusion korrekt? | Genauigkeit >= 0,90 |
| Textwiedergabe | OCR plus genaue Übereinstimmung oder Richter review | Ist der erforderliche Text genau? | 100 % für den erforderlichen Text |
| Ort bearbeiten | Gepaartes Diff plus menschlicher Richter | Sind unberührte Regionen unverändert geblieben? | Durchschnitt >= 4/5 |
| Identität und Marke | Ähnlichkeitsprüfung plus lokaler Zuschnitt review | Sind Gesicht, Logo, Typ und product-Identität stabil geblieben? | Durchschnitt >= 4/5 |
Sicherheit und Voreingenommenheit sollten getrennt von der Bildschönheit bewertet werden.
| Risiko | So testen Sie | Ergebnistyp |
|---|---|---|
| Schädlicher Inhalt | Führen Sie prompt und Ausgabefilterung aus; Rotes Team mit hohem Risiko prompts | Bestanden/nicht bestanden |
| Datenschutz oder nahezu doppelte Ausgabe | Verwenden Sie Einbettungen, Wahrnehmungs-Hashes oder die Suche nach dem nächsten Nachbarn für interne Assets | Bestehen/Bewertung |
| Faktische Halluzination | Für sachliche Behauptungen nutzen Sie VQA-Prüfungen | 0-1 oder 0-100 |
| Gruppenvoreingenommenheit | Verwenden Sie kontrafaktische prompts, die nur Geschlecht, Alter, ethnische Zugehörigkeit oder Beruf ändern | Differenzwert |
| Marken- oder persönlicher Missbrauch | Wenden Sie strengere review für reale Personen, Marken, Ausweise und Bilder im medizinischen Stil an | Bestanden/nicht bestanden |
Ein qualitativ hochwertiges Bild ist nicht automatisch ein Bild mit geringem Risiko. Die praktische Teammethode ist das kontrafaktische Testen: Halten Sie prompt konstant und ändern Sie nur das Gruppenattribut. Überprüfen Sie dann, ob sich Beruf, Körperhaltung, Kleidung, Alter oder Hautton systematisch ändern.
Robustheitstestmatrix
Testen Sie nicht nur eine Ausgabeeinstellung. GPT Image 2 quality kann sich ändern, wenn sich Auflösung, Komprimierung, quality oder Bearbeitungskontext ändern.
Verwenden Sie eine kleine Matrix:
| Variabel | Empfohlene Werte |
|---|---|
| Auflösung | 1024 x 1024, 1536 x 1024, 2048 x 2048, 3840 x 2160, sofern unterstützt |
| Qualität | low, medium, high sofern unterstützt |
| Komprimierung | PNG, JPEG/WebP 95, 85, 70 |
| Pipeline skalieren | Original, Downsampling, Downsampling und dann Upsampling |
| Okklusion und Zuschneiden | 10 %, 25 %, 40 % zufällige Okklusion; Randkulturen; lokale Kulturen |
| Samen | Mindestens 3 Kandidaten pro prompt |
| Eingaben bearbeiten | Verschiedene Eingabebild-quality-Ebenen und Zuschneidebereiche |
Das ist keine Bürokratie. Es verhindert, dass ein Team einen model unter einer perfekten Bedingung besteht und dann einen Fehler in der Real-Asset-Pipeline entdeckt.
Protokoll zur menschlichen Bewertung
Menschliches review wird nur dann entscheidungsfähig, wenn das Protokoll stabil ist.
Verwenden Sie diese Standardeinstellung:
- Mindestens 100 prompts pro scenario.
- Mindestens 3 Samen pro prompt.
- Mindestens 3 Kommentatoren pro Bild.
- Verwenden Sie 5 Annotatoren für Hochrisikokategorien wie medical, datenschutzrelevante, rechtliche, identitätsrelevante oder markenkritische Arbeitsabläufe.
- Trennen Sie Hard-Gate-Fragen von der Likert-Bewertung.
- Verwenden Sie beim Vergleich von Versionen blinde A/B-Tests.
- Erlaube tie und unsichere Optionen.
Vermeiden Sie faule Bewertungsskalen wie „1 = schlecht, 5 = gut“. Definieren Sie jeden Punkt.
Beispiel für eine Ausrichtungsskala:
| Punktzahl | Definition |
|---|---|
| 1 | Stimmt völlig nicht mit prompt überein |
| 2 | Stimmt nur geringfügig mit prompt überein |
| 3 | Teilweise Übereinstimmungen, mit wichtigen Auslassungen oder Fehlern |
| 4 | Fast vollständig übereinstimmend, mit kleineren Problemen |
| 5 | Entspricht vollständig dem prompt |
Beispiel einer visuellen quality-Skala:
| Punktzahl | Definition |
|---|---|
| 1 | Offensichtlich kaputt oder unbrauchbar |
| 2 | Auffällig fehlerhaft |
| 3 | Akzeptabel für den Entwurfsgebrauch |
| 4 | Gut und wahrscheinlich brauchbar |
| 5 | Nahezu professionelle Produktion quality |
Der Anmerkungsleitfaden muss außerdem Folgendes definieren:
- Welche prompt-Teile sind harte Einschränkungen?
- Ob ein fehlendes erforderliches Objekt ein Fehler ist.
- Ob ein falsches Textzeichen ein Fehler ist.
- Wie man räumliche Beziehungen, Quantität und Farbbindung beurteilt.
- Ob creative-Ergänzungen zulässig sind.
- Was als unaufgeforderte Bearbeitung gilt.
- Der Unterschied zwischen ungefährer und exakter Richtigkeit.
- Wann Annotatoren möglicherweise tie wählen oder unsicher sind.
Ohne diese Regeln ist die Auswertung nicht nur verrauscht. Es ist nicht reproduzierbar.
Stichprobengröße und statistische Berichterstattung
Kleine Auswertungen können beim Debuggen hilfreich sein, sollten jedoch keine Startentscheidungen beeinflussen.
Praktische Regeln:
- Bei weniger als 100 prompts können model-Vergleiche leicht umschlagen.
- Für eine binäre pass-Rate mit einem 95-%-Konfidenzintervall um plus oder minus 5 % beträgt die konservative Stichprobe size etwa 384 Stichproben.
- Wenn die erwartete pass-Rate etwa 85 % beträgt, können etwa 196 Stichproben einen ähnlichen Fehlerbereich erreichen.
- Planen Sie für einen A/B-Präferenztest, bei dem der erwartete Vorteil etwa 60/40 beträgt, ungefähr 200 gültige Paarvergleiche ein.
- Eine stärkere 65/35-Präferenz erfordert weniger Stichproben, erfordert aber dennoch eine ausreichende Abdeckung aller Szenarien.
Melden Sie mehr als den Durchschnitt:
| Ziel | Primäre Metrik | Vorgeschlagener Test | Bericht |
|---|---|---|---|
| Tor freigeben | Text- oder Sicherheitsrate pass | Exakter Binomialintervall- oder Zwei-Proportions-Test | Erfolgsquote, 95 % CI, absolute Differenz |
| A/B-Präferenz | Gewinnquote, Unentschieden werden ignoriert | Exakter Binomialtest | Gewinnrate, 95 % CI, p-Wert |
| Gepaarte Likert-Bewertung | Ausrichtung, quality, Ort | Wilcoxon signed-rank | Mediandifferenz, p-Wert, Effekt size |
| Unabhängige Likert-Gruppen | Szenario- oder Modellfamilienvergleich | Mann-Whitney U | Verteilungsunterschied, p-Wert |
| Annotator-Vereinbarung | Krippendorff's alpha für Ordinalbezeichnungen | Zuverlässigkeitsschätzung | Alpha-Wert |
Verwenden Sie Alpha = 0,05, zweiseitig, es sei denn, Ihr Team hat einen schriftlichen Grund, etwas anderes zu tun. Wenn Sie mehrere primäre Messwerte melden, wenden Sie eine Mehrfachvergleichskorrektur an. Für die Annotator-Übereinstimmung ist Krippendorff's alpha >= 0,80 ein verlässliches Ziel; 0,667 bis 0,80 sollten als vorläufig betrachtet werden.
Automatisierung und Reproduzierbarkeit
Das Bewertungssystem sollte wie product-Code versioniert sein. Eine gute Pipeline sieht so aus:
- Definieren Sie scenario-Slices und Risikostufen.
- Erstellen Sie prompts, geben Sie Bilder, Masken und Referenzbeispiele ein.
- Generieren Sie Stapel für die Einstellungen size, quality, Format, Komprimierung und seed.
- Führen Sie harte Gates für Text, Objektpräsenz, Sicherheit und Bearbeitungsort aus.
- Führen Sie automatische Metriken wie LPIPS, SSIM, CLIPScore, Prüfungen im TIFA-Stil, Prüfungen im VQAScore-Stil, Prüfungen im GenEval-Stil und Prüfungen im VISOR-Stil aus.
- Senden Sie Grenz- und Stichprobenausgaben zur menschlichen Überprüfung.
- Führen Sie statistische Tests und Annotator-Übereinstimmungsprüfungen durch.
- Veröffentlichen Sie ein Dashboard, das Fehler nach scenario, Fehlertyp und Konfiguration anzeigt.
- Speichern Sie Fehlerfälle und nutzen Sie diese zur Verbesserung von prompts, Masken oder workflow-Regeln.
Nützliche Werkzeugkategorien:
| Werkzeugkategorie | Beispielwerkzeuge | Zweck |
|---|---|---|
| Bildmetriken | TorchMetrics, PIQ | FID, IS, LPIPS, CLIPScore, PSNR, SSIM, DISTS, NIQE |
| Semantische Bewertung | TIFA, VQAScore, GenEval, Testsätze im VISOR-Stil | Objekt-, Attribut-, Anzahl-, räumliche und Eingabetreueprüfungen |
| Versionierung | DVC, Git, Artefaktspeicher | Version prompts, Bilder, Referenzen, Metriken und Ausgaben |
| CI | GitHub Actions oder gleichwertig | Führen Sie Regressionstests durch und blockieren Sie Releases |
| Armaturenbrett | BI Dashboard oder interner Bericht | Zeigen Sie pass-Raten, Score-Verteilungen, Kosten, Latenz und Fehlerfälle an |
Das Dashboard sollte nicht nur einen globalen Durchschnitt anzeigen. Unterteilen Sie die Ergebnisse mindestens nach:
- Szenario
- Fehlertyp
- Größe
- Qualitätseinstellung
- Komprimierung
- Schnelle Familie
- Risikostufe
- Modellversion
Verfolgen Sie auch Betriebskennzahlen. Wenn hochwertige Einstellungen die Latenz oder die Kosten verdoppeln und die menschliche Präferenz nur geringfügig verbessern, ist das eine product-Entscheidung und nicht nur ein Forschungsergebnis.
Beispiel eines Bewertungsschemas
Ein einfaches CSV- oder JSON-Schema sorgt dafür, dass die Bewertung überprüfbar bleibt.
| Feld | Typ | Bedeutung |
|---|---|---|
| run_id | string | Evaluierungslauf-ID |
| prompt_id | string | Eindeutige prompt-ID |
| scenario | string | product, ux, creative, medical oder industrial |
| risk_tier | string | low, medium oder high |
| prompt_text | string | Original prompt |
| model | string | Modellname |
| model_version | string | Modellversion |
| size | string | Ausgabe size |
| quality | string | Qualitätseinstellung |
| output_format | string | png, jpeg oder webp |
| output_compression | int | Komprimierungswert |
| seed | int | Kandidaten-Richtlinien-ID seed oder seed |
| reference_id | string | Referenz für gepaarte Tests |
| gate_instruction | int | 0 oder 1 |
| gate_text_exact | int | 0 oder 1 |
| gate_safety | int | 0 oder 1 |
| object_presence | float | 0 zu 1 |
| attribute_accuracy | float | 0 zu 1 |
| spatial_accuracy | float | 0 zu 1 |
| locality_score | float | 0 bis 5 |
| visual_quality | float | 0 bis 5 |
| human_pref_win | string | win, loss oder tie |
| annotator_id | string | Menschliche Prüfer-ID |
| rationale | string | Kurzer Grund |
| latency_ms | int | Generierungslatenz |
| cost_estimate | float | Geschätzte Kosten |
| overall_verdict | string | pass, review oder fail |
Abschließende Team-Checkliste
Bevor Sie GPT Image 2 als produktionsbereit für ein workflow behandeln, bestätigen Sie, dass Sie Folgendes getan haben:
- Definierte das Release-Ziel: model-Auswahl, Regression oder Launch-Gate.
- Definierte scenario-Slices und Risikostufen.
- Es wurden harte Einschränkungen für erforderliche Objekte, erforderlichen Text, verbotene Inhalte und Bereiche ohne Bearbeitung geschrieben.
- Erstellen Sie einen prompt-Satz mit normalen Beispielen, Herausforderungsbeispielen und Sicherheits- oder Voreingenommenheitsbeispielen.
- Mindestens 3 Kandidaten pro Eingabe generiert.
- Getestet wurden mindestens zwei size-Einstellungen und zwei quality-Einstellungen, sofern unterstützt.
- Führen Sie Text-, Objekt-, Sicherheits- und Bearbeitungsort-Gates aus, bevor Sie sich die durchschnittliche Qualität ansehen.
- Gemessene semantische Ausrichtung, Objektpräsenz, Attributbindung, räumliche Beziehungen und visuelles quality separat.
- Verwendetes menschliches review für creative-Passform, Markenpassform und Grenzfälle.
- Berichtete Konfidenzintervalle, Effektgrößen, statistische Signifikanz und Annotator-Übereinstimmung.
- Versioniertes prompts, Bilder, Einstellungen, Metriken, Richter prompts, menschliche Codebücher und Skripte.
- Ein Dashboard erstellt, das zeigt, warum Ausgaben fehlgeschlagen sind, und nicht nur, dass sie fehlgeschlagen sind.
Die Kurzversion: Bewerten Sie GPT Image 2 mit workflow-Gattern, semantischer Zerlegung, menschlichem review, statistischer Disziplin und versionierter Regression. Lassen Sie nicht zu, dass ein ausgefeilter Durchschnittswert einen Produktionsfehler verbirgt.