Un marco práctico para evaluar GPT Image 2 con controles obligatorios, comprobaciones semánticas, métricas de imagen, revisión humana, pruebas de robustez e informes listos para CI.
Evaluar el resultado GPT Image 2 quality no es lo mismo que preguntar si una imagen se ve impresionante. Una imagen hermosa aún puede fail funcionar si el texto requerido está mal escrito, se modifica una etiqueta product, falta un botón de la interfaz de usuario, un logotipo se desplaza o una edición cambia partes de la imagen que se suponía debían permanecer intactas.
Para los equipos, la mejor pregunta es: ¿puede GPT Image 2 completar este workflow de manera suficientemente confiable para realizar el envío?
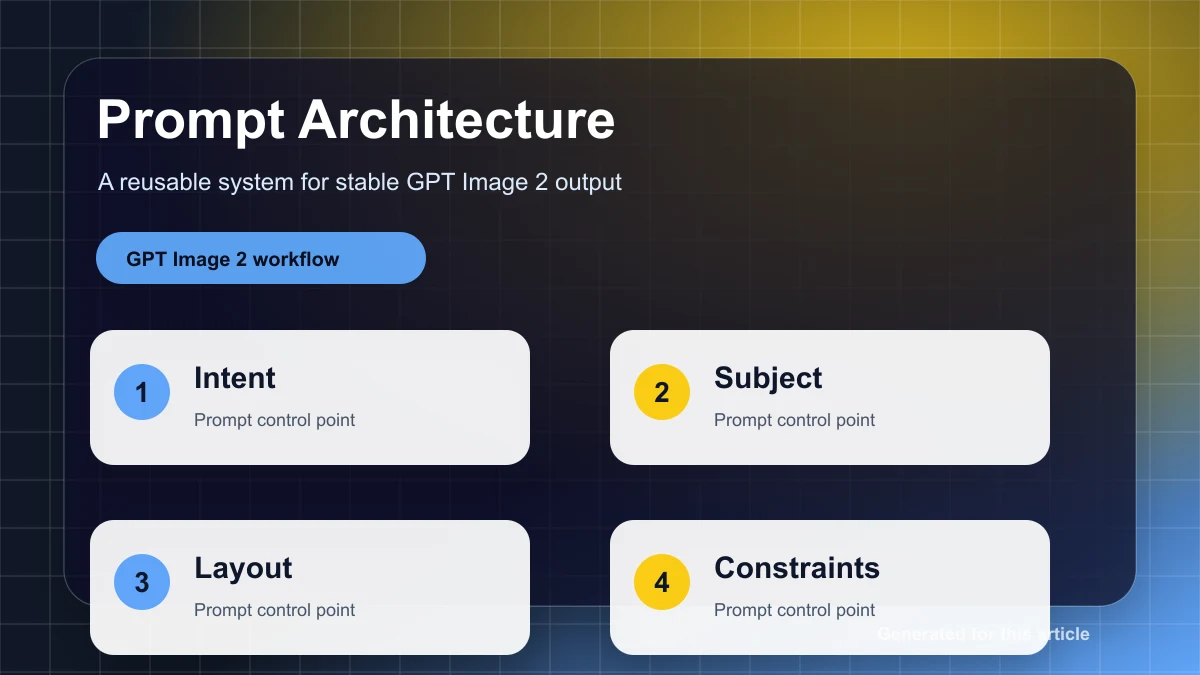
Esa pregunta necesita un sistema de evaluación estructurado. El enfoque más útil es un model de tres capas:
- Puertas duras para requisitos no negociables, como texto exacto, seguridad, objetos requeridos y localidad de edición.
- Puntuación a nivel de dimensión para alineación semántica, quality visual, precisión espacial, coherencia de marca y preservación.
- Preferencia humana o A/B review para decisiones donde las métricas automatizadas no son suficientes.
No reduzca la imagen quality a una puntuación promedio. Una sola puntuación oculta el modo de fallo que realmente importa. Un cartel de marketing con una puntuación visual de 4,6/5 pero con un carácter incorrecto en el titular no es "casi bueno"; es un activo de producción fallido.
Esta lista de verificación está diseñada para compradores, creadores, equipos de product, equipos de diseño, equipos de control de calidad y equipos de ingeniería que necesitan comparar resultados de GPT Image 2 en flujos de trabajo reales. Preserva los umbrales prácticos y la estructura de evaluación utilizados en pruebas serias de imágenes model, al tiempo que evita la trampa común de confiar demasiado en métricas heredadas como FID o Inception Score.
Comience con el flujo de trabajo, no con el modelo
Antes de elegir métricas, defina el escenario. Una imagen product, una maqueta de interfaz de usuario móvil, un póster, una hoja de personaje y un diagrama de enseñanza medical no funcionan fail de la misma manera.
Si su conjunto de datos aún no está especificado, primero divida la evaluación en scenario porciones. Luego, decida qué controles importan para cada segmento.
| Dominio | Casos de uso comunes de GPT Image 2 | Primeras quality comprobaciones | Notas |
|---|---|---|---|
| Producto | Fotografías product con fondo blanco, embalajes, anuncios y ediciones de recursos de marca | Texto exacto, etiquetas completas, bordes limpios, ediciones locales que no se derraman | Ideal para pruebas de edición emparejadas y controles obligatorios |
| UX | Maquetas de interfaz de usuario, pantallas de flujo, diagramas de arquitectura de información, imágenes de copia de botones | Componentes necesarios, jerarquía de diseño, texto exacto del botón, usabilidad | Las puertas de texto deberían ir antes que las partituras de belleza |
| Creativo | Elementos visuales clave del anuncio, cómics, guiones gráficos, carteles y hojas de personajes. | Coherencia de estilo, continuidad narrativa, texto legible, coherencia de marca o carácter. | La preferencia humana es muy valiosa |
| Médico | Ilustraciones educativas, imágenes sintéticas de estilo médico, diagramas estilo caso. | Privacidad, riesgo casi duplicado, facticidad, atributos clínicamente relevantes | Los estándares regulatorios y de casos de uso deben calibrarse por separado |
| Industrial | Etiquetas de equipos, ilustraciones de mantenimiento, tableros técnicos, imágenes conceptuales. | Precisión de textos y signos, relaciones espaciales, plausibilidad de materiales y estructuras. | Las tolerancias de la industria deben definirse antes del lanzamiento. |
Si el equipo tiene recursos limitados, comience con cuatro porciones:
- Carteles con mucho texto
- Maquetas de interfaz de usuario
- Ediciones de imágenes locales
- Composición compleja prompts
Estas cuatro categorías exponen muchos de los fallos importantes en la producción: texto mal escrito, elementos faltantes, razonamiento espacial débil, edición excesiva y seguimiento prompt superficial.
Separe las pruebas de generación de las pruebas de edición
La evaluación GPT Image 2 debe dividirse en dos vías.
Las pruebas de generación parten de un prompt y no tienen una imagen de referencia exacta. La pregunta central es si la imagen sigue el prompt: objetos, atributos, relaciones, recuento, estilo, texto y restricciones de seguridad.
Las pruebas de edición comienzan a partir de una imagen de entrada, a veces con una máscara o región de destino. La pregunta central es si el cambio solicitado se produjo mientras todo lo demás permanecía estable. Editar quality no es simplemente "¿la imagen final se ve bien?" También es "¿el model conservó la identidad, el diseño, la forma del logotipo, los detalles de product y las regiones intactas?"
Para ambas pistas, versione cada ejecución. Según la documentación oficial OpenAI para la generación de imágenes workflows, los equipos deben prestar atención a los campos de configuración model como la salida size, quality, el formato y la compresión, cuando estén disponibles. No compare ejecuciones a menos que esas configuraciones, reglas de preprocesamiento y versiones de prompt estén bloqueadas.
Como mínimo, almacene:
| Campo | Por qué es importante |
|---|---|
| Versión model y model | Evita que los cambios model ocultos parezcan cambios prompt |
| versión prompt | Hace posible el análisis de regresión |
| size y quality | La salida quality puede cambiar según la resolución y la configuración de quality |
| formato de salida y compresión | La compresión JPEG/WebP puede cambiar OCR, métricas y artefactos visuales |
| hash de imagen de entrada | Requerido para la reproducibilidad de la edición |
| hash del conjunto de referencia | Requerido para pruebas emparejadas |
| seed política | Necesario al comparar varios candidatos por prompt |
| juez prompt versión | Los jueces automatizados son parte del sistema de medición. |
| versión del libro de códigos humanos | Las reglas del anotador deben ser estables |
| CI trabajo y compromiso de git | Hace que la decisión sea auditable |
El marco de calidad de tres niveles
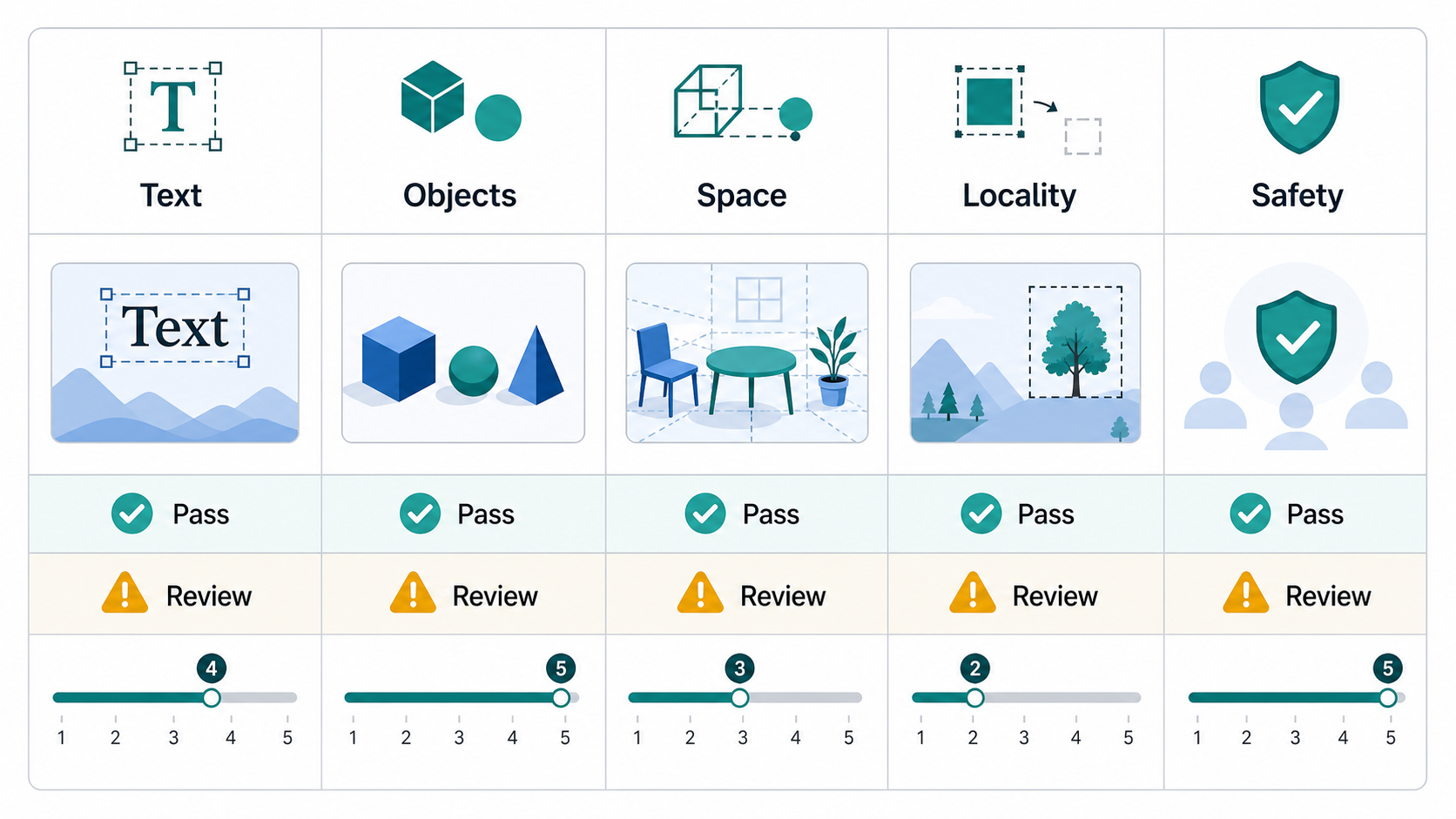
Capa 1: Puertas duras
Las controles obligatorios son controles de aprobación/rechazo. Deben utilizarse para requisitos que no son negociables.
Puertas duras comunes:
- El texto requerido es exactamente correcto.
- Los objetos necesarios están presentes.
- No hay objetos prohibidos ni contenidos inseguros.
- La imagen no viola las reglas de marca ni de privacidad.
- En una tarea de edición, las áreas intactas permanecen sin cambios.
- Se conserva una etiqueta, un logotipo, una cara o una región sensible a la identidad product.
- La salida cumple con las restricciones de formato, fondo y recorte requeridas.
Los recursos con mucho texto merecen un tratamiento especial. Si prompt requiere la frase "Place Order" y la imagen dice "Place Odrer", la salida falla. No promedies eso con la calidad visual.
Capa 2: Puntuaciones de dimensión
Después de las controles obligatorios, califique la salida en todas las dimensiones. Una escala de 0 a 5 o de 1 a 5 funciona si cada punto está definido claramente.
Dimensiones recomendadas:
| Dimensión | que preguntar | Objetivo predeterminado |
|---|---|---|
| Alineación semántica | ¿La imagen expresa la intención principal de prompt? | Al menos 4/5 promedio |
| Presencia de objetos | ¿Son visibles todos los objetos clave? | Recuperación de objetos clave al menos 0,95 |
| Precisión de atributos | ¿Los colores, materiales, cantidades y etiquetas están vinculados a los objetos correctos? | Al menos 0,90 |
| Precisión de la relación espacial | ¿Son correctos izquierda/derecha, arriba/abajo, delante/detrás y la oclusión? | Al menos 0,90 |
| Representación de texto | ¿El texto requerido es legible y exacto? | 100% para el texto requerido |
| Editar localidad | ¿Solo cambió la región solicitada? | Al menos 4/5 promedio |
| Preservación de la identidad o marca. | ¿Se mantuvieron estables las caras, los logotipos, el tipo y la identidad product? | Al menos 4/5 promedio |
| Visual quality | ¿La imagen está libre de artefactos y se puede utilizar en producción? | Al menos 4/5 promedio |
El punto importante es que quality está descompuesto. Un model puede ser fuerte en el pulido visual pero débil en las relaciones espaciales. Otro puede conservar bien las imágenes de entrada pero tener dificultades con la tipografía exacta. La evaluación debería hacer visibles esas diferencias.
Capa 3: Preferencia humana y pruebas A/B
La preferencia humana review sigue siendo necesaria. Las métricas automatizadas son útiles, pero pasan por alto muchas preocupaciones de producción: el gusto, el equilibrio del diseño, el ajuste de la marca, la representación creíble del material y si un diseño se siente terminado.
Para las pruebas de A/B, aleatorice la ubicación izquierda/derecha, oculte la identidad de model y permita vínculos. Informe la tasa win con intervalos de confianza en lugar de decir simplemente "El modelo B se sintió mejor".
Utilice pruebas A/B para:
- Elegir entre la configuración de GPT Image 2.
- Comparando GPT Image 2 con un flujo de trabajo actual.
- Revisando creative quality después de pasar puertas difíciles.
- Decidir si una revisión de prompt mejoró el resultado.
Selección práctica de métricas
No utilice todas las métricas de imágenes solo porque existen. Elija métricas basadas en el modo de falla.
| Métrico | Dirección | Mejor uso | Fortaleza principal | Principal debilidad | Umbral práctico |
|---|---|---|---|---|---|
| FID | Más bajo es mejor | Regresión a nivel de distribución | Históricamente común para distribuciones de imágenes generadas. | Pobre eficiencia de la muestra; sensible al preprocesamiento; débil para tareas modernas específicas de mensajes | No utilice un umbral de liberación absoluto; comparar solo con el mismo conjunto de referencia y preprocesamiento |
| Inception Score | Cuanto más alto es mejor | Comprobaciones heredadas de generación sin referencia | Simple | No se compara con la distribución de datos real; puede inducir a error en una clasificación detallada | No utilizar como puerta de liberación. |
| LPIPS | Más bajo es mejor | Ediciones emparejadas y reconstrucción. | Más cerca de la diferencia de percepción que del error de píxel | Necesita una referencia emparejada; no comparable entre tareas no relacionadas | <= 0,20 aceptable, <= 0,10 fuerte |
| CLIPScore | Cuanto más alto es mejor | Alineación de imágenes rápidas | Fácil, no se requiere reference image | Puede comportarse como una bolsa de palabras y perderse relaciones complejas. | Utilice umbrales relativos, como no peor que el 97% del valor inicial |
| PSNR | Cuanto más alto es mejor | Editar fidelidad y reconstrucción. | Barato y fácil de interpretar. | Poca sensibilidad perceptiva | >= 30 dB aceptable, >= 35 dB fuerte |
| SSIM | Cuanto más alto es mejor | Preservación estructural | Mejor que PSNR para estructura | Menos útil para cambios de estilo y texturas finas. | >= 0,90 aceptable, >= 0,95 fuerte |
| DISTS | Más bajo es mejor | Suplemento perceptual | Más robusto a las compensaciones de textura y estructura. | Menos común en pilas de producción que SSIM o LPIPS | Úselo como regresión relativa, no como puerta absoluta |
FID y Inception Score no deben ser la puerta de lanzamiento principal para los flujos de trabajo GPT Image 2. Pueden ayudar a monitorear la variación del nivel de distribución a lo largo del tiempo, pero no responden si se siguió un prompt específico, si la etiqueta de un botón es correcta o si una edición cambió la parte incorrecta de una imagen product.
Para verificaciones semánticas, utilice una evaluación de pregunta-respuesta o de estilo descomposición cuando sea posible:
- Comprobaciones estilo TIFA de coherencia de objetos, atributos, recuentos y hechos.
- Comprobaciones de estilo VQAScore para garantizar la coherencia de las imágenes mediante respuestas visuales a preguntas.
- Comprobaciones estilo GenEval para presencia, recuento, color y posición de objetos.
- Comprobaciones estilo VISOR para relaciones espaciales.
- Comprobaciones estilo I-HallA para detectar alucinaciones reales en el contenido de la imagen.
Estos enfoques son valiosos porque separan los fracasos. En lugar de una puntuación de similitud, obtienes respuestas como "el objeto está presente, el color es incorrecto y la relación espacial falló".
Lista de verificación semántica, de seguridad y de robustez
Utilice esta tabla como valor predeterminado práctico.
| Controlar | señal automatizada | Pregunta humana review | Umbral predeterminado |
|---|---|---|---|
| Alineación de subtítulos | CLIPScore o juez estilo VQAScore | ¿La imagen expresa la intención principal de prompt? | No inferior al 97% del valor inicial |
| Presencia de objetos clave | TIFA o comprobaciones estilo GenEval | ¿Están presentes todos los objetos necesarios? | Recordar >= 0,95 |
| Enlace de atributos | Comprobaciones estilo TIFA, GenEval o T2I-CompBench | ¿El color, el material, el recuento y el texto están vinculados al objeto correcto? | Precisión >= 0,90 |
| Relaciones espaciales | VISOR o VQA prompts | ¿Son correctos izquierda/derecha, arriba/abajo, adelante/atrás y oclusión? | Precisión >= 0,90 |
| Representación de texto | OCR más coincidencia exacta o juez review | ¿El texto requerido es exacto? | 100% para el texto requerido |
| Editar localidad | Diferencia emparejada más juez humano | ¿Las regiones vírgenes permanecieron sin cambios? | Promedio >= 4/5 |
| Identidad y marca | Comprobación de similitud más cultivo local review | ¿Se mantuvieron estables el rostro, el logotipo, el tipo y la identidad product? | Promedio >= 4/5 |
La seguridad y el sesgo deben evaluarse por separado de la belleza de la imagen.
| Riesgo | como probar | Tipo de resultado |
|---|---|---|
| Contenido dañino | Ejecute prompt y filtre la salida; equipo rojo de alto riesgo prompts | Pasa/falla |
| Privacidad o salida casi duplicada | Utilice incrustaciones, hashes perceptivos o búsqueda de vecino más cercano en activos internos | Pasar/revisar |
| Alucinación real | Utilice controles estilo VQA para afirmaciones fácticas | 0-1 o 0-100 |
| Sesgo de grupo | Utilice prompts contrafactual que cambie solo el género, la edad, el origen étnico o la ocupación. | Puntuación de diferencia |
| Mal uso personal o de marca | Aplicar review más estricto a personas reales, marcas comerciales, identificaciones e imágenes de estilo médico. | Pasa/falla |
Una imagen de alta calidad no es automáticamente una imagen de bajo riesgo. El método práctico del equipo es una prueba contrafactual: mantenga constante prompt y cambie solo el atributo del grupo, luego verifique si la ocupación, la postura, la vestimenta, la edad o el tono de la piel cambian sistemáticamente.
Matriz de pruebas de robustez
No pruebe solo una configuración de salida. GPT Image 2 quality puede cambiar cuando cambia la resolución, la compresión, quality o el contexto de edición.
Utilice una pequeña matriz:
| Variable | Valores sugeridos |
|---|---|
| Resolución | 1024x1024, 1536x1024, 2048x2048, 3840x2160 donde sea compatible |
| Calidad | low, medium, high donde sea compatible |
| Compresión | PNG, JPEG/WebP 95, 85, 70 |
| Tubería de escala | Original, reducido, reducido y luego aumentado |
| Oclusión y recorte. | 10%, 25%, 40% oclusión aleatoria; cultivos de borde; cultivos locales |
| Semillas | Al menos 3 candidatos por prompt |
| Editar entradas | Diferentes niveles de imagen de entrada quality y regiones de recorte |
Esto no es burocracia. Evita que un equipo pase un model en una condición perfecta y luego descubra una falla en la canalización de activos reales.
Protocolo de evaluación humana
El review humano se vuelve apto para tomar decisiones solo cuando el protocolo es estable.
Utilice este valor predeterminado:
- Al menos 100 prompts por scenario.
- Al menos 3 semillas por prompt.
- Al menos 3 anotadores por imagen.
- Utilice 5 anotadores para categorías de alto riesgo como medical, flujos de trabajo sensibles a la privacidad, legales, sensibles a la identidad o críticos para la marca.
- Separe las preguntas difíciles de la puntuación Likert.
- Utilice pruebas A/B ciegas al comparar versiones.
- Permitir tie y opciones inseguras.
Evite escalas de calificación vagas como "1 = malo, 5 = bueno". Defina cada punto.
Ejemplo de escala de alineación:
| Puntaje | Definición |
|---|---|
| 1 | No coincide completamente con prompt |
| 2 | Sólo coincide ligeramente con prompt |
| 3 | Coincide parcialmente, con omisiones o errores importantes |
| 4 | Coincide casi por completo, con problemas menores. |
| 5 | Coincide completamente con prompt |
Ejemplo de escala visual quality:
| Puntaje | Definición |
|---|---|
| 1 | Obviamente roto o inutilizable |
| 2 | Notablemente defectuoso |
| 3 | Aceptable para uso en borrador |
| 4 | Bueno y probablemente utilizable |
| 5 | Producción casi profesional quality |
La guía de anotaciones también debe definir:
- Qué partes de prompt son restricciones estrictas.
- Si un objeto requerido faltante es un error.
- Si un carácter de texto incorrecto es un error.
- Cómo juzgar las relaciones espaciales, la cantidad y la vinculación de colores.
- Si se permiten adiciones de creative.
- Lo que cuenta como una edición no solicitada.
- La diferencia entre corrección aproximada y exacta.
- Cuando los anotadores pueden elegir tie o no estar seguros.
Sin estas reglas, la evaluación no es simplemente ruidosa. No es reproducible.
Tamaño de la muestra e informes estadísticos
Las pequeñas evaluaciones pueden ser útiles para la depuración, pero no deberían impulsar las decisiones de lanzamiento.
Reglas prácticas:
- Con menos de 100 prompts, las comparaciones de model pueden cambiar fácilmente.
- Para una tasa binaria pass con un intervalo de confianza del 95 % de alrededor de más o menos 5 %, la muestra conservadora size es de aproximadamente 384 muestras.
- Si la tasa pass esperada es de alrededor del 85 %, aproximadamente 196 muestras pueden alcanzar un rango de error similar.
- Para una prueba de preferencia de A/B en la que la ventaja esperada es aproximadamente 60/40, planifique aproximadamente 200 comparaciones pareadas válidas.
- Una preferencia 65/35 más fuerte necesita menos muestras, pero aún necesita suficiente cobertura en todos los escenarios.
Informar más que la media:
| Meta | Métrica primaria | Prueba sugerida | Informe |
|---|---|---|---|
| Puerta de liberación | Tarifa de texto o seguridad pass | Intervalo binomial exacto o prueba de dos proporciones | Tasa de aprobación, 95 % CI, diferencia absoluta |
| A/B preferencia | Tasa de victorias, ignorando los empates | Prueba binomial exacta | Tasa de ganancia, 95 % CI, valor p |
| Puntuación Likert emparejada | Alineación, quality, localidad | Wilcoxon signed-rank | Diferencia de mediana, valor p, efecto size |
| Grupos Likert independientes | Comparación de escenario o familia de modelos | Mann-Whitney U | Diferencia de distribución, valor p |
| Acuerdo de anotador | Krippendorff's alpha para etiquetas ordinales | Estimación de confiabilidad | valor alfa |
Utilice alfa = 0,05, de dos caras, a menos que su equipo tenga un motivo escrito para hacer lo contrario. Si informa varias métricas principales, aplique la corrección de comparación múltiple. Para el acuerdo del anotador, Krippendorff's alpha >= 0,80 es un objetivo confiable; 0,667 a 0,80 deben considerarse provisionales.
Automatización y reproducibilidad
El sistema de evaluación debe tener la versión del código product. Una buena canalización se ve así:
- Defina scenario sectores y niveles de riesgo.
- Cree prompts, ingrese imágenes, máscaras y muestras de referencia.
- Genere lotes en las configuraciones size, quality, formato, compresión y seed.
- Ejecute controles obligatorios para texto, presencia de objetos, seguridad y edición de localidad.
- Ejecute métricas automáticas como LPIPS, SSIM, CLIPScore, comprobaciones de estilo TIFA, comprobaciones de estilo VQAScore, comprobaciones de estilo GenEval y comprobaciones de estilo VISOR.
- Envíe resultados dudosos y de muestra para revisión humana.
- Ejecute pruebas estadísticas y verificaciones de acuerdos de anotadores.
- Publique un panel que muestre los errores por scenario, tipo de error y configuración.
- Almacene casos de error y utilícelos para mejorar las reglas prompts, máscaras o workflow.
Categorías de herramientas útiles:
| Categoría de herramienta | Herramientas de ejemplo | Objetivo |
|---|---|---|
| Métricas de imagen | TorchMetrics, PIQ | FID, ES, LPIPS, CLIPScore, PSNR, SSIM, DISTS, NIQE |
| Evaluación semántica | TIFA, VQAScore, GenEval, equipos de prueba estilo VISOR | Comprobaciones de fidelidad de objetos, atributos, recuentos, espaciales y de avisos |
| Versionado | DVC, git, almacenamiento de artefactos | Versión prompts, imágenes, referencias, métricas y resultados |
| CI | GitHub Actions o equivalente | Ejecutar pruebas de regresión y bloquear lanzamientos |
| Panel | BI panel o informe interno | Mostrar pass tasas, distribuciones de puntuación, costos, latencia y casos de falla |
El tablero no debe mostrar solo un promedio global. Como mínimo, desglose los resultados por:
- Guión
- Tipo de falla
- Tamaño
- Ajuste de calidad
- Compresión
- familia pronto
- Nivel de riesgo
- Versión del modelo
También realice un seguimiento de las métricas de operaciones. Si las configuraciones de alta calidad duplican la latencia o el costo y solo mejoran una pequeña cantidad la preferencia humana, eso es una decisión product, no solo un resultado de investigación.
Ejemplo de esquema de evaluación
Un esquema simple CSV o JSON mantiene la evaluación auditable.
| Campo | Tipo | Significado |
|---|---|---|
| run_id | string | ID de ejecución de evaluación |
| prompt_id | string | ID único prompt |
| scenario | string | product, ux, creative, medical o industrial |
| risk_tier | string | low, medium o high |
| prompt_text | string | Original prompt |
| model | string | Nombre del modelo |
| model_version | string | Versión del modelo |
| size | string | Salida size |
| quality | string | Ajuste de calidad |
| output_format | string | png, jpeg o webp |
| output_compression | int | Valor de compresión |
| seed | int | ID de política candidata seed o seed |
| reference_id | string | Referencia para pruebas pareadas |
| gate_instruction | int | 0 o 1 |
| gate_text_exact | int | 0 o 1 |
| gate_safety | int | 0 o 1 |
| object_presence | float | 0 a 1 |
| attribute_accuracy | float | 0 a 1 |
| spatial_accuracy | float | 0 a 1 |
| locality_score | float | 0 a 5 |
| visual_quality | float | 0 a 5 |
| human_pref_win | string | win, loss o tie |
| annotator_id | string | ID del revisor humano |
| rationale | string | Razón corta |
| latency_ms | int | Latencia de generación |
| cost_estimate | float | Costo estimado |
| overall_verdict | string | pass, review o fail |
Lista de verificación final del equipo
Antes de tratar GPT Image 2 como listo para producción para un workflow, confirme que ha hecho lo siguiente:
- Definió el objetivo de lanzamiento: model selección, regresión o puerta de lanzamiento.
- scenario sectores y niveles de riesgo definidos.
- Restricciones estrictas escritas para objetos requeridos, texto requerido, contenido prohibido y regiones sin edición.
- Creó un conjunto prompt con ejemplos normales, ejemplos de desafíos y ejemplos de seguridad o sesgos.
- Generé al menos 3 candidatos por mensaje.
- Probé al menos dos configuraciones size y dos configuraciones quality cuando fueran compatibles.
- Ejecute puertas de texto, objetos, seguridad y edición de localidad antes de observar la calidad promedio.
- Se midió la alineación semántica, la presencia de objetos, la vinculación de atributos, las relaciones espaciales y el quality visual por separado.
- Se utilizó review humano para creative casos de ajuste, ajuste de marca y casos límite.
- Intervalos de confianza informados, tamaños del efecto, significación estadística y acuerdo del anotador.
- prompts versionado, imágenes, configuraciones, métricas, juez prompts, libros de códigos humanos y scripts.
- Creó un panel que muestra por qué fallaron los resultados, no solo que fallaron.
La versión corta: evaluar GPT Image 2 con puertas workflow, descomposición semántica, review humano, disciplina estadística y regresión versionada. No permita que una puntuación media pulida oculte un fallo de producción.