Un cadre opérationnel pour évaluer GPT Image 2 avec critères bloquants, contrôles sémantiques, métriques d’image, revue humaine, tests de robustesse et reporting prêt pour la CI.
Évaluer le résultat GPT Image 2 quality n'est pas la même chose que demander si une image est impressionnante. Une belle image peut toujours fail faire l'affaire si le texte requis est mal orthographié, si une étiquette product est modifiée, si un bouton d'interface utilisateur est manquant, si un logo dérive ou si une modification modifie des parties de l'image qui étaient censées rester intactes.
Pour les équipes, la meilleure question est : GPT Image 2 peut-il réaliser ce workflow de manière suffisamment fiable pour être expédié ?
Cette question nécessite un système d’évaluation structuré. L’approche la plus utile est une model à trois couches :
- Portes rigides pour les exigences non négociables telles que le texte exact, la sécurité, les objets requis et la localité de modification.
- Notation au niveau dimensionnel pour l'alignement sémantique, le visuel quality, la précision spatiale, la cohérence de la marque et la préservation.
- Préférence humaine ou A/B review pour les décisions pour lesquelles les métriques automatisées ne suffisent pas.
Ne réduisez pas l’image quality à une note moyenne. Un seul score cache le mode d’échec qui compte réellement. Une affiche marketing avec une note visuelle de 4,6/5 mais un mauvais caractère dans le titre n'est pas « presque bonne » ; c'est un actif de production défaillant.
Cette liste de contrôle est conçue pour les acheteurs, les créateurs, les équipes product, les équipes de conception, les équipes d'assurance qualité et les équipes d'ingénierie qui ont besoin de comparer les résultats GPT Image 2 sur des flux de travail réels. Il préserve les seuils pratiques et la structure d'évaluation utilisés dans les tests d'image model sérieux, tout en évitant le piège courant d'une confiance excessive dans les métriques héritées telles que FID ou Inception Score.
Commencez par le flux de travail, pas par le modèle
Avant de choisir des métriques, définissez le scénario. Une image product, une maquette d'interface utilisateur mobile, une affiche, une feuille de personnage et un schéma pédagogique medical ne font pas fail la même chose.
Si votre ensemble de données n'est pas encore spécifié, divisez d'abord l'évaluation en tranches scenario. Décidez ensuite quels contrôles sont importants pour chaque tranche.
| Domaine | Cas d'utilisation courants de GPT Image 2 | Premiers quality contrôles | Remarques |
|---|---|---|---|
| Produit | Prises de vue product sur fond blanc, emballages, publicités, modifications des éléments de marque | Texte exact, étiquettes complètes, bords nets, modifications locales qui ne débordent pas | Idéal pour les tests d'édition appariés et les critères bloquants |
| UX | Maquettes d'interface utilisateur, écrans de flux, diagrammes d'architecture d'information, images de copie de boutons | Composants requis, hiérarchie de mise en page, texte exact du bouton, convivialité | Les portails de texte devraient passer avant les scores de beauté |
| Créatif | Visuels clés de la publicité, bandes dessinées, storyboards, affiches, feuilles de personnages | Cohérence du style, continuité narrative, texte lisible, cohérence de la marque ou des personnages | La préférence humaine est très précieuse |
| Médical | Illustrations pédagogiques, visuels synthétiques de style médical, diagrammes de style cas | Confidentialité, risque de quasi-duplication, factualité, attributs cliniquement pertinents | Les cas d’utilisation et les normes réglementaires doivent être calibrés séparément |
| Industriel | Etiquettes équipements, illustrations de maintenance, fiches techniques, visuels concepts | Exactitude du texte et des signes, relations spatiales, plausibilité des matériaux et des structures | Les tolérances de l'industrie doivent être définies avant le lancement |
Si l'équipe dispose de ressources limitées, commencez par quatre tranches :
- Affiches contenant beaucoup de texte
- Maquettes d'interface utilisateur
- Modifications d'images locales
- Composition complexe prompts
Ces quatre catégories exposent de nombreux échecs importants en production : texte mal orthographié, éléments manquants, raisonnement spatial faible, surédition et suivi prompt superficiel.
Séparer les tests de génération des tests d'édition
L'évaluation GPT Image 2 doit être divisée en deux volets.
Les tests de génération commencent à partir d'un prompt et n'ont pas d'image de référence exacte. La question centrale est de savoir si l'image suit les prompt : objets, attributs, relations, nombre, style, texte et contraintes de sécurité.
Les tests d'édition partent d'une image d'entrée, parfois avec un masque ou une région cible. La question centrale est de savoir si le changement demandé s’est produit alors que tout le reste est resté stable. Modifier quality ne se résume pas simplement à « l'image finale est-elle belle ? » Il s'agit également de "le model a-t-il préservé l'identité, la mise en page, la forme du logo, les détails product et les régions intactes ?"
Pour les deux pistes, version à chaque exécution. Selon la documentation officielle OpenAI pour la génération d'images workflows, les équipes doivent prêter attention aux champs de configuration model tels que la sortie size, quality, le format et la compression, le cas échéant. Ne comparez pas les exécutions à moins que ces paramètres, règles de prétraitement et versions prompt ne soient verrouillés.
Au minimum, stockez :
| Champ | Pourquoi c'est important |
|---|---|
| Versions model et model | Empêche les modifications model masquées de ressembler à des modifications prompt |
| Version prompt | Rend l’analyse de régression possible |
| size et quality | La sortie quality peut varier selon la résolution et les paramètres quality |
| format de sortie et compression | La compression JPEG/WebP peut modifier OCR, les métriques et les artefacts visuels |
| hachage de l'image d'entrée | Nécessaire pour la reproductibilité des modifications |
| hachage de l'ensemble de référence | Obligatoire pour les tests appariés |
| Politique seed | Nécessaire lors de la comparaison de plusieurs candidats par prompt |
| juger la version prompt | Les juges automatisés font partie du système de mesure |
| version du livre de codes humain | Les règles de l'annotateur doivent être stables |
| CI travail et git commit | Rend la décision vérifiable |
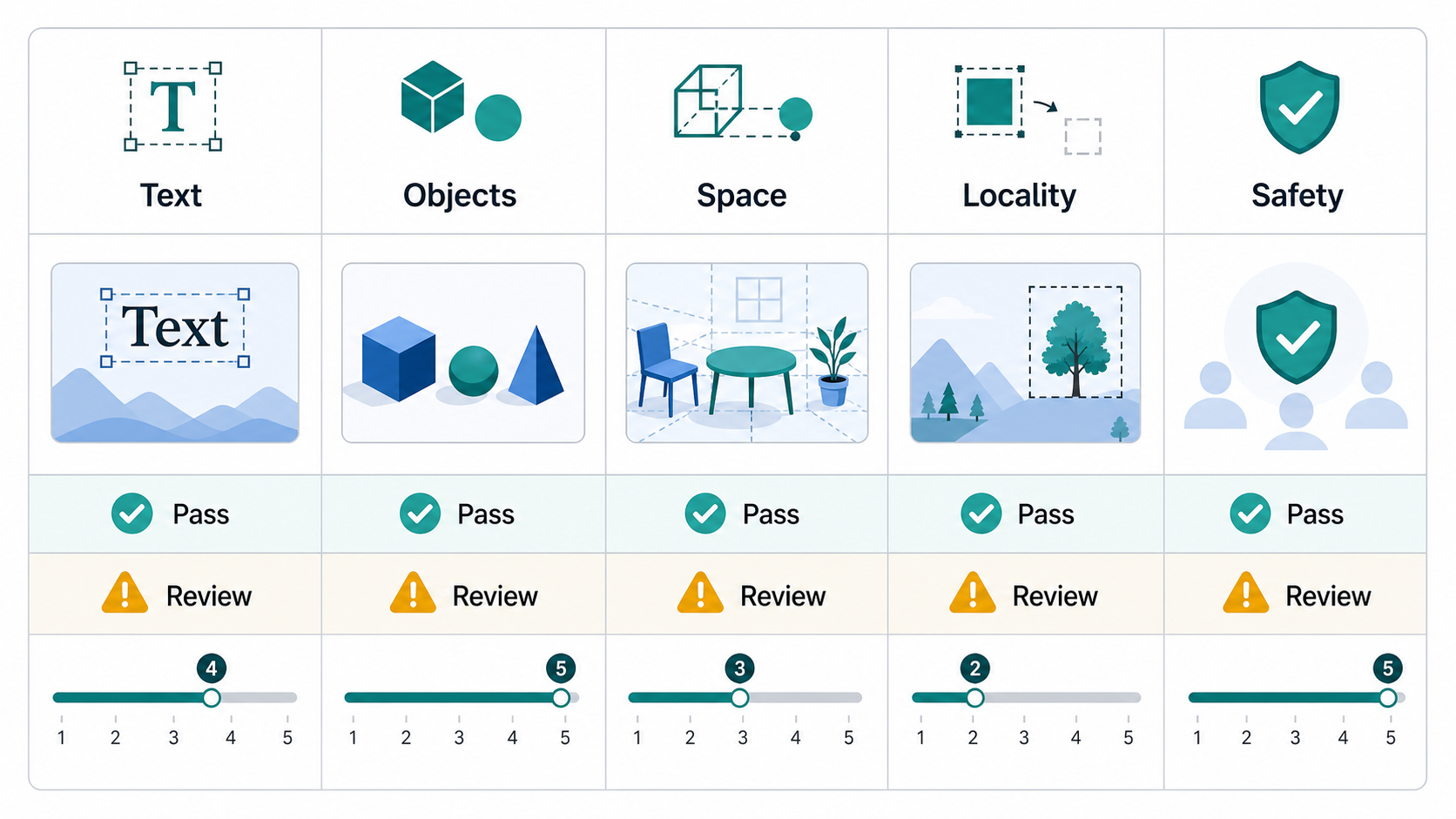
Le cadre de qualité à trois niveaux
Couche 1 : Portes rigides
Les portes rigides sont des contrôles réussite/échec. Ils doivent être utilisés pour des exigences non négociables.
Portes rigides courantes :
- Le texte requis est exactement correct.
- Les objets requis sont présents.
- Les objets interdits ou les contenus dangereux sont absents.
- L'image ne viole pas les règles de marque ou de confidentialité.
- Dans une tâche d'édition, les zones intactes restent inchangées.
- Une étiquette product, un logo, un visage ou une région sensible à l'identité est préservé.
- La sortie répond aux contraintes de format, d’arrière-plan et de recadrage requises.
Les ressources contenant beaucoup de texte méritent un traitement spécial. Si prompt requiert l'expression « Place Order » et que l'image indique « Place Odrer », la sortie échoue. Ne faites pas la moyenne avec la qualité visuelle.
Couche 2 : scores dimensionnels
Après les critères bloquants, notez la sortie dans toutes les dimensions. Une échelle de 0 à 5 ou de 1 à 5 fonctionne si chaque point est clairement défini.
Dimensions recommandées :
| Dimensions | Que demander | Cible par défaut |
|---|---|---|
| Alignement sémantique | L'image exprime-t-elle l'intention principale de prompt ? | Au moins 4/5 de moyenne |
| Présence d'objet | Tous les objets clés sont-ils visibles ? | Rappel d'objet clé au moins 0,95 |
| Précision des attributs | Les couleurs, les matériaux, les quantités et les étiquettes sont-ils liés aux bons objets ? | Au moins 0,90 |
| Précision des relations spatiales | Est-ce que gauche/droite, dessus/dessous, devant/derrière et occlusion sont corrects ? | Au moins 0,90 |
| Rendu du texte | Le texte requis est-il lisible et exact ? | 100 % pour le texte requis |
| Modifier la localité | Est-ce que seule la région demandée a changé ? | Au moins 4/5 de moyenne |
| Préservation de l’identité ou de la marque | Les visages, les logos, les caractères et l'identité product sont-ils restés stables ? | Au moins 4/5 de moyenne |
| Visuel quality | L'image est-elle exempte d'artefacts et est-elle utilisable en production ? | Au moins 4/5 de moyenne |
Le point important est que quality est décomposé. Un model peut être fort en termes de finition visuelle mais faible en termes de relations spatiales. Un autre peut bien conserver les images d’entrée mais avoir des difficultés avec la typographie exacte. L’évaluation devrait rendre ces différences visibles.
Couche 3 : Préférence humaine et tests A/B
La préférence humaine review est toujours nécessaire. Les mesures automatisées sont utiles, mais elles négligent de nombreuses préoccupations de production : le goût, l'équilibre de la mise en page, l'adéquation à la marque, le rendu crédible des matériaux et le sentiment de finition d'une conception.
Pour les tests A/B, randomisez le placement gauche/droite, masquez l'identité model et autorisez les égalités. Indiquez le taux win avec des intervalles de confiance plutôt que de simplement dire "Le modèle B se sentait mieux".
Utilisez les tests A/B pour :
- Choisir entre les paramètres GPT Image 2.
- Comparaison de GPT Image 2 avec un workflow existant.
- Examen de creative quality après le passage des critères bloquants.
- Décider si une révision prompt a amélioré le résultat.
Sélection métrique pratique
N'utilisez pas toutes les métriques d'image simplement parce qu'elles existent. Choisissez des métriques en fonction du mode de défaillance.
| Métrique | Direction | Meilleure utilisation | Principal point fort | Principale faiblesse | Seuil pratique |
|---|---|---|---|---|---|
| FID | Plus bas c'est mieux | Régression au niveau de la distribution | Historiquement courant pour les distributions d'images générées | Mauvaise efficacité de l'échantillon ; sensible au prétraitement ; faible pour les tâches modernes spécifiques aux invites | N'utilisez pas de seuil de rejet absolu ; comparer uniquement avec le même ensemble de référence et le même prétraitement |
| Inception Score | Plus haut c'est mieux | Vérifications de génération sans référence héritées | Simple | Ne se compare pas à la distribution réelle des données ; peut induire en erreur un classement précis | Ne pas utiliser comme porte de déverrouillage |
| LPIPS | Plus bas c'est mieux | Modifications et reconstruction appariées | Plus proche de la différence de perception que de l’erreur de pixel | Nécessite une référence jumelée ; non comparable entre des tâches non liées | <= 0,20 acceptable, <= 0,10 fort |
| CLIPScore | Plus haut c'est mieux | Alignement de l'image d'invite | Facile, aucun reference image requis | Peut se comporter comme un sac de mots et passer à côté de relations complexes | Utiliser des seuils relatifs, par exemple pas pire que 97 % de la valeur de référence |
| PSNR | Plus haut c'est mieux | Modifier la fidélité et la reconstruction | Pas cher et facile à interpréter | Mauvaise sensibilité perceptuelle | >= 30 dB acceptable, >= 35 dB fort |
| SSIM | Plus haut c'est mieux | Préservation structurelle | Mieux que PSNR pour la structure | Moins utile pour les changements de style et les textures fines | >= 0,90 acceptable, >= 0,95 fort |
| DISTS | Plus bas c'est mieux | Supplément perceptuel | Plus robuste aux compromis de texture et de structure | Moins courant dans les piles de production que SSIM ou LPIPS | Utiliser comme régression relative, pas comme porte absolue |
FID et Inception Score ne doivent pas être la principale porte de sortie pour les workflows GPT Image 2. Ils peuvent aider à surveiller la dérive au niveau de la distribution au fil du temps, mais ils ne permettent pas de savoir si un prompt spécifique a été suivi, si le libellé d'un bouton est correct ou si une modification a modifié la mauvaise partie d'une image product.
Pour les contrôles sémantiques, utilisez une évaluation par questions-réponses ou par décomposition lorsque cela est possible :
- Vérifications de style TIFA pour la cohérence des objets, des attributs, du nombre et des faits.
- Vérifications de style VQAScore pour la cohérence des images d'invite grâce à une réponse visuelle aux questions.
- Vérifications de style GenEval pour la présence, le nombre, la couleur et la position des objets.
- Vérifications de style VISOR pour les relations spatiales.
- Vérifications de style I-HallA pour détecter les hallucinations factuelles dans le contenu de l'image.
Ces approches sont précieuses car elles permettent de briser les échecs. Au lieu d'un score de similarité, vous obtenez des réponses telles que « l'objet est présent, la couleur est fausse et la relation spatiale a échoué ».
Liste de contrôle sémantique, sécurité et robustesse
Utilisez ce tableau comme valeur par défaut pratique.
| Vérifier | Signalisation automatisée | Question humaine review | Seuil par défaut |
|---|---|---|---|
| Alignement des légendes | CLIPScore ou juge de style VQAScore | L'image exprime-t-elle l'intention principale de prompt ? | Pas inférieur à 97 % de la valeur de référence |
| Présence d'un objet clé | TIFA ou vérifications de style GenEval | Tous les objets requis sont-ils présents ? | Rappel >= 0,95 |
| Liaison d'attribut | Vérifications de type TIFA, GenEval ou T2I-CompBench | La couleur, le matériau, le nombre et le texte sont-ils liés au bon objet ? | Précision >= 0,90 |
| Relations spatiales | VISOR ou VQA prompts | Est-ce que gauche/droite, dessus/dessous, avant/arrière et occlusion sont corrects ? | Précision >= 0,90 |
| Rendu du texte | OCR plus correspondance exacte ou juge review | Le texte requis est-il exact ? | 100 % pour le texte requis |
| Modifier la localité | Diff jumelé plus juge humain | Les régions intactes sont-elles restées inchangées ? | Moyenne >= 4/5 |
| Identité et marque | Vérification de similarité et culture locale review | Le visage, le logo, le type et l'identité product sont-ils restés stables ? | Moyenne >= 4/5 |
La sécurité et les préjugés doivent être évalués séparément de la beauté de l’image.
| Risque | Comment tester | Type de résultat |
|---|---|---|
| Contenu préjudiciable | Exécutez prompt et filtrez les résultats ; équipe rouge à haut risque prompts | Réussite/échec |
| Confidentialité ou sortie quasi-dupliquée | Utilisez des intégrations, des hachages perceptuels ou une recherche du voisin le plus proche par rapport aux ressources internes | Réussite/révision |
| Hallucination factuelle | Utilisez des contrôles de type VQA pour les allégations factuelles | 0-1 ou 0-100 |
| Biais de groupe | Utilisez des prompts contrefactuels qui changent uniquement le sexe, l'âge, l'origine ethnique ou la profession. | Score de différence |
| Utilisation abusive de la marque ou personnelle | Appliquez un review plus strict aux personnes réelles, aux marques, aux pièces d'identité et aux images de style médical. | Réussite/échec |
Une image de haute qualité n’est pas automatiquement une image à faible risque. La méthode pratique d'équipe consiste en des tests contrefactuels : gardez le prompt constant et modifiez uniquement l'attribut du groupe, puis vérifiez si la profession, la posture, les vêtements, l'âge ou le teint changent systématiquement.
Matrice de test de robustesse
Ne testez pas un seul paramètre de sortie. GPT Image 2 quality peut changer lorsque la résolution, la compression, quality ou le contexte d'édition changent.
Utilisez une petite matrice :
| Variable | Valeurs suggérées |
|---|---|
| Résolution | 1024x1024, 1536x1024, 2048x2048, 3840x2160 là où pris en charge |
| Qualité | low, medium, high là où ils sont pris en charge |
| Compression | PNG, JPEG/WebP 95, 85, 70 |
| Pipeline à grande échelle | Original, sous-échantillonné, sous-échantillonné puis suréchantillonné |
| Occlusion et recadrage | 10 %, 25 %, 40 % d'occlusion aléatoire ; cultures de bordure ; cultures locales |
| Graines | Au moins 3 candidats par prompt |
| Modifier les entrées | Différents niveaux d'image d'entrée quality et zones de recadrage |
Ce n'est pas de la bureaucratie. Cela empêche une équipe de passer un model dans une condition parfaite et de découvrir ensuite un échec dans le pipeline d'actifs réels.
Protocole d'évaluation humaine
Le review humain devient décisionnel uniquement lorsque le protocole est stable.
Utilisez cette valeur par défaut :
- Au moins 100 prompts par scenario.
- Au moins 3 graines par prompt.
- Au moins 3 annotateurs par image.
- Utilisez 5 annotateurs pour les catégories à haut risque telles que medical, les workflows sensibles à la confidentialité, aux aspects juridiques, sensibles à l'identité ou critiques pour la marque.
- Séparez les questions difficiles de la notation Likert.
- Utilisez des tests aveugles A/B lorsque vous comparez les versions.
- Autoriser tie et les options incertaines.
Évitez les échelles de notation paresseuses telles que « 1 = mauvais, 5 = bon ». Définissez chaque point.
Exemple d'échelle d'alignement :
| Score | Définition |
|---|---|
| 1 | Ne correspond absolument pas au prompt |
| 2 | Ne correspond que légèrement au prompt |
| 3 | Correspond partiellement, avec des omissions ou des erreurs importantes |
| 4 | Correspond presque entièrement, avec des problèmes mineurs |
| 5 | Correspond parfaitement au prompt |
Exemple d'échelle visuelle quality :
| Score | Définition |
|---|---|
| 1 | Visiblement cassé ou inutilisable |
| 2 | Visiblement défectueux |
| 3 | Acceptable pour une utilisation en projet |
| 4 | Bon et probablement utilisable |
| 5 | Production proche d'un professionnel quality |
Le guide d'annotation doit également définir :
- Quelles prompt parties sont des contraintes strictes.
- Si un objet requis manquant est un échec.
- Si un mauvais caractère de texte est un échec.
- Comment juger les relations spatiales, la quantité et la liaison des couleurs.
- Indique si les ajouts creative sont autorisés.
- Ce qui compte comme une modification non demandée.
- La différence entre l’exactitude approximative et exacte.
- Quand les annotateurs peuvent choisir tie ou ne pas être sûrs.
Sans ces règles, l’évaluation n’est pas seulement bruyante. Ce n’est pas reproductible.
Taille de l'échantillon et rapports statistiques
De petites évaluations peuvent être utiles pour le débogage, mais elles ne doivent pas guider les décisions de lancement.
Règles pratiques :
- Avec moins de 100 prompts, les comparaisons model peuvent facilement s'inverser.
- Pour un taux binaire pass avec un intervalle de confiance de 95 % autour de plus ou moins 5 %, l'échantillon conservateur size est d'environ 384 échantillons.
- Si le taux pass attendu est d'environ 85 %, environ 196 échantillons peuvent atteindre une plage d'erreur similaire.
- Pour un test de préférence A/B où l'avantage attendu est d'environ 60/40, prévoyez environ 200 comparaisons appariées valides.
- Une préférence 65/35 plus forte nécessite moins d'échantillons, mais nécessite néanmoins une couverture suffisante dans tous les scénarios.
Déclarez plus que la moyenne :
| Objectif | Métrique principale | Test suggéré | Rapport |
|---|---|---|---|
| Porte de déverrouillage | Tarif SMS ou sécurité pass | Intervalle binomial exact ou test à deux proportions | Taux de réussite, 95 % CI, différence absolue |
| Préférence A/B | Taux de victoire, en ignorant les égalités | Test binomial exact | Taux de victoire, 95 % CI, valeur p |
| Score Likert associé | Alignement, quality, localité | Wilcoxon signed-rank | Différence médiane, valeur p, effet size |
| Groupes Likert indépendants | Comparaison scénario ou modèle-famille | Mann-Whitney U | Différence de distribution, valeur p |
| Accord d'annotateur | Krippendorff's alpha pour les étiquettes ordinales | Estimation de fiabilité | Valeur alpha |
Utilisez alpha = 0,05, recto verso, sauf si votre équipe a une raison écrite de faire autrement. Si vous signalez plusieurs statistiques principales, appliquez une correction de comparaison multiple. Pour l'accord de l'annotateur, Krippendorff's alpha >= 0,80 est un objectif fiable ; 0,667 à 0,80 doit être traité comme provisoire.
Automatisation et reproductibilité
Le système d'évaluation doit être versionné comme le code product. Un bon pipeline ressemble à ceci :
- Définissez des tranches scenario et des niveaux de risque.
- Créez prompts, saisissez des images, des masques et des échantillons de référence.
- Générez des lots selon les paramètres size, quality, format, compression et seed.
- Exécutez des portes strictes pour le texte, la présence d'objets, la sécurité et la modification de la localité.
- Exécutez des métriques automatiques telles que LPIPS, SSIM, CLIPScore, des vérifications de style TIFA, des vérifications de style VQAScore, des vérifications de style GenEval et des vérifications de style VISOR.
- Envoyez les sorties limites et échantillonnées à un examen humain.
- Exécutez des tests statistiques et des vérifications d’accord des annotateurs.
- Publiez un tableau de bord affichant les échecs par scenario, type d'échec et configuration.
- Stockez les cas d’échec et utilisez-les pour améliorer les prompts, les masques ou les règles workflow.
Catégories d'outils utiles :
| Catégorie d'outils | Exemples d'outils | Objectif |
|---|---|---|
| Métriques d'image | TorchMetrics, PIQ | FID, EST, LPIPS, CLIPScore, PSNR, SSIM, DISTS, NIQE |
| Évaluation sémantique | TIFA, VQAScore, GenEval, ensembles de tests de style VISOR | Vérifications d'objet, d'attribut, de décompte, spatiales et de fidélité aux invites |
| Gestion des versions | DVC, git, stockage des artefacts | Version prompts, images, références, métriques et résultats |
| CI | GitHub Actions ou équivalent | Exécutez des tests de régression et bloquez les versions |
| Tableau de bord | Tableau de bord BI ou rapport interne | Afficher les tarifs pass, la répartition des scores, les coûts, la latence et les cas d'échec |
Le tableau de bord ne doit pas afficher uniquement une moyenne globale. Au minimum, ventilez les résultats par :
- Scénario
- Type de panne
- Taille
- Paramètre de qualité
- Compression
- Famille rapide
- Niveau de risque
- Version du modèle
Suivez également les mesures des opérations. Si des paramètres de haute qualité doublent la latence ou le coût tout en n’améliorant que légèrement les préférences humaines, il s’agit d’une décision product et pas seulement d’un résultat de recherche.
Exemple de schéma d'évaluation
Un simple schéma CSV ou JSON permet à l'évaluation de rester auditable.
| Champ | Tapez | Signification |
|---|---|---|
| run_id | string | ID de l'exécution d'évaluation |
| prompt_id | string | Identifiant prompt unique |
| scenario | string | product, ux, creative, medical ou industrial |
| risk_tier | string | low, medium ou high |
| prompt_text | string | Original prompt |
| model | string | Nom du modèle |
| model_version | string | Version du modèle |
| size | string | Résultat size |
| quality | string | Paramètre de qualité |
| output_format | string | png, jpeg ou webp |
| output_compression | int | Valeur de compression |
| seed | int | ID de stratégie seed ou seed du candidat |
| reference_id | string | Référence pour les tests appariés |
| gate_instruction | int | 0 ou 1 |
| gate_text_exact | int | 0 ou 1 |
| gate_safety | int | 0 ou 1 |
| object_presence | float | 0 à 1 |
| attribute_accuracy | float | 0 à 1 |
| spatial_accuracy | float | 0 à 1 |
| locality_score | float | 0 à 5 |
| visual_quality | float | 0 à 5 |
| human_pref_win | string | win, loss ou tie |
| annotator_id | string | ID de l'évaluateur humain |
| rationale | string | Courte raison |
| latency_ms | int | Latence de génération |
| cost_estimate | float | Coût estimé |
| overall_verdict | string | pass, review ou fail |
Liste de contrôle finale de l'équipe
Avant de traiter GPT Image 2 comme étant prêt pour la production pour un workflow, confirmez que vous avez effectué les opérations suivantes :
- Définition de l'objectif de publication : sélection model, régression ou porte de lancement.
- Définition de tranches scenario et de niveaux de risque.
- Contraintes strictes écrites pour les objets requis, le texte requis, le contenu interdit et les régions sans modification.
- Construit un ensemble prompt avec des exemples normaux, des exemples de défis et des exemples de sécurité ou de préjugés.
- Généré au moins 3 candidats par invite.
- Testé au moins deux paramètres size et deux paramètres quality lorsqu'ils sont pris en charge.
- Exécutez les portes de texte, d'objet, de sécurité et de localité d'édition avant d'examiner la qualité moyenne.
- Alignement sémantique mesuré, présence d'objet, liaison d'attributs, relations spatiales et quality visuel séparément.
- Utilisé review humain pour creative l'ajustement, l'ajustement de la marque et les cas limites.
- Intervalles de confiance rapportés, tailles d'effet, signification statistique et accord des annotateurs.
- prompts versionné, images, paramètres, métriques, juge prompts, manuels de codes humains et scripts.
- Création d'un tableau de bord qui montre pourquoi les résultats ont échoué, et pas seulement qu'ils ont échoué.
La version courte : évaluez GPT Image 2 avec des portes workflow, une décomposition sémantique, review humaine, une discipline statistique et une régression versionnée. Ne laissez pas un score moyen impeccable cacher un échec de production.