GPT Image 2 आउटपुट गुणवत्ता का मूल्यांकन करने के लिए टीमों हेतु एक व्यावहारिक फ्रेमवर्क, जिसमें hard gates, semantic checks, image metrics, human review, robustness testing और CI-ready reporting शामिल हैं।
GPT Image 2 आउटपुट गुणवत्ता का मूल्यांकन करना यह पूछने के समान नहीं है कि कोई छवि प्रभावशाली दिखती है या नहीं। एक सुंदर छवि अभी भी fail काम कर सकती है यदि आवश्यक पाठ गलत वर्तनी में है, एक product लेबल बदल दिया गया है, एक यूआई बटन गायब है, एक लोगो भटक गया है, या एक संपादन छवि के उन हिस्सों को बदल देता है जिन्हें अछूता रहना चाहिए था।
टीमों के लिए, बेहतर सवाल यह है: क्या GPT Image 2 इस workflow को शिप करने के लिए पर्याप्त रूप से पूरा कर सकता है?
उस प्रश्न के लिए एक संरचित मूल्यांकन प्रणाली की आवश्यकता है। सबसे उपयोगी दृष्टिकोण तीन-परत मॉडल है:
- हार्ड गेट्सगैर-परक्राम्य आवश्यकताओं जैसे कि सटीक पाठ, सुरक्षा, आवश्यक वस्तुएं और संपादन स्थान के लिए।
- सिमेंटिक संरेखण, दृश्य गुणवत्ता, स्थानिक सटीकता, ब्रांड स्थिरता और संरक्षण के लिए आयाम-स्तरीय स्कोरिंग।
- मानव प्राथमिकता या A/B reviewउन निर्णयों के लिए जहां स्वचालित मेट्रिक्स पर्याप्त नहीं हैं।
छवि गुणवत्ता को एक औसत अंक तक कम न करें। एक एकल स्कोर failure मोड को छुपाता है जो वास्तव में मायने रखता है। 4.6/5 विज़ुअल स्कोर वाला एक मार्केटिंग पोस्टर लेकिन शीर्षक में एक गलत चरित्र "almost good" नहीं है; यह एक failed production संपत्ति है।
यह चेकलिस्ट खरीदारों, रचनाकारों, product टीमों, डिज़ाइन टीमों, QA टीमों और इंजीनियरिंग टीमों के लिए डिज़ाइन की गई है, जिन्हें वास्तविक workflows में GPT Image 2 आउटपुट की तुलना करने की आवश्यकता है। यह गंभीर छवि मॉडल परीक्षण में उपयोग की जाने वाली व्यावहारिक सीमाओं और मूल्यांकन संरचना को संरक्षित करता है, जबकि FID या Inception Score जैसे अति-भरोसेमंद विरासत मेट्रिक्स के सामान्य जाल से बचता है।
Workflow से प्रारंभ करें, मॉडल से नहीं
मेट्रिक्स चुनने से पहले, परिदृश्य को परिभाषित करें। एक product छवि, एक मोबाइल यूआई मॉकअप, एक पोस्टर, एक कैरेक्टर शीट, और एक medical शिक्षण आरेख एक ही तरह से fail नहीं है।
यदि आपका डेटासेट अभी तक निर्दिष्ट नहीं है, तो पहले मूल्यांकन को परिदृश्य स्लाइस में विभाजित करें। फिर तय करें कि प्रत्येक स्लाइस के लिए कौन सा चेक मायने रखता है।
| डोमेन | सामान्य GPT Image 2 उपयोग के मामले | पहले गुणवत्ता की जांच | टिप्पणियाँ |
|---|---|---|---|
| उत्पाद | सफ़ेद-पृष्ठभूमि product शॉट्स, पैकेजिंग, विज्ञापन, ब्रांड संपत्ति संपादन | सटीक पाठ, पूर्ण लेबल, साफ किनारे, स्थानीय संपादन जो फैलते नहीं हैं | युग्मित संपादन परीक्षणों और हार्ड गेट्स के लिए सबसे उपयुक्त |
| UX | यूआई मॉकअप, flow स्क्रीन, सूचना आर्किटेक्चर आरेख, बटन-कॉपी छवियां | आवश्यक घटक, लेआउट पदानुक्रम, सटीक बटन टेक्स्ट, प्रयोज्यता | सौंदर्य स्कोर से पहले टेक्स्ट गेट्स आने चाहिए |
| रचनात्मक | विज्ञापन कुंजी दृश्य, कॉमिक्स, स्टोरीबोर्ड, पोस्टर, चरित्र पत्रक | शैली की निरंतरता, कथा की निरंतरता, पठनीय पाठ, ब्रांड या चरित्र की निरंतरता | मानवीय प्राथमिकता highly मूल्यवान है |
| मेडिकल | शैक्षिक चित्रण, सिंथेटिक medical-शैली दृश्य, केस-शैली आरेख | गोपनीयता, लगभग डुप्लिकेट जोखिम, तथ्यात्मकता, चिकित्सकीय रूप से प्रासंगिक विशेषताएं | उपयोग-मामले और नियामक मानकों को अलग से अंशांकित किया जाना चाहिए |
| औद्योगिक | उपकरण लेबल, रखरखाव चित्र, तकनीकी बोर्ड, अवधारणा दृश्य | पाठ और संकेत सटीकता, स्थानिक संबंध, सामग्री और संरचना संभाव्यता | लॉन्च से पहले उद्योग की सहनशीलता को परिभाषित किया जाना चाहिए |
यदि टीम के पास सीमित संसाधन हैं, तो चार स्लाइस से शुरुआत करें:
- पाठ-भारी पोस्टर
- यूआई मॉकअप
- स्थानीय छवि संपादन
- जटिल संरचना prompts
ये चार श्रेणियां production में मायने रखने वाले कई failures को उजागर करती हैं: गलत वर्तनी वाला पाठ, गायब तत्व, कमजोर स्थानिक तर्क, अति-संपादन, और shallow prompt following।
संपादन परीक्षण से जनरेशन परीक्षण को अलग करें
GPT Image 2 मूल्यांकन को दो ट्रैक में विभाजित किया जाना चाहिए।
जनरेशन परीक्षणprompt से शुरू होते हैं और उनकी कोई सटीक संदर्भ छवि नहीं होती है। केंद्रीय प्रश्न यह है कि क्या छवि prompt को फोल करती है: ऑब्जेक्ट, विशेषताएँ, रिश्ते, गिनती, शैली, पाठ और सुरक्षा बाधाएँ।
संपादन परीक्षणएक इनपुट छवि से शुरू होते हैं, कभी-कभी mask या लक्ष्य क्षेत्र के साथ। मुख्य प्रश्न यह है कि क्या अनुरोधित परिवर्तन तब हुआ जब बाकी सब कुछ स्थिर रहा। संपादन गुणवत्ता सिर्फ "does the final image look good?" नहीं है बल्कि "did the model preserve identity, layout, logo shape, product details, and untouched regions?" भी है
दोनों ट्रैक के लिए, प्रत्येक संस्करण संस्करण। छवि निर्माण workflows के लिए आधिकारिक OpenAI दस्तावेज़ के अनुसार, टीमों को जहां उपलब्ध हो वहां आउटपुट आकार, गुणवत्ता, प्रारूप और संपीड़न जैसे मॉडल कॉन्फ़िगरेशन फ़ील्ड पर ध्यान देना चाहिए। जब तक वे सेटिंग्स, प्रीप्रोसेसिंग नियम और prompt संस्करण लॉक न हों, तब तक रन की तुलना न करें।
कम से कम, स्टोर करें:
| मैदान | यह क्यों मायने रखता है? |
|---|---|
| मॉडल और मॉडल संस्करण | छिपे हुए मॉडल परिवर्तनों को prompt परिवर्तनों की तरह दिखने से रोकता है |
| prompt संस्करण | प्रतिगमन विश्लेषण को संभव बनाता है |
| आकार और गुणवत्ता | आउटपुट गुणवत्ता रिज़ॉल्यूशन और गुणवत्ता सेटिंग्स में भिन्न हो सकती है |
| आउटपुट स्वरूप और संपीड़न | JPEG/WebP संपीड़न OCR, मेट्रिक्स और दृश्य कलाकृतियों को बदल सकता है |
| इनपुट छवि हैश | संपादन प्रतिलिपि प्रस्तुत करने योग्यता के लिए आवश्यक है |
| संदर्भ सेट हैश | युग्मित परीक्षणों के लिए आवश्यक |
| seed नीति | प्रति prompt एकाधिक उम्मीदवारों की तुलना करते समय इसकी आवश्यकता होती है |
| judge prompt संस्करण | स्वचालित judge माप प्रणाली का हिस्सा हैं |
| मानव कोडबुक संस्करण | एनोटेटर नियम स्थिर होने चाहिए |
| CI जॉब और गिट कमिट | निर्णय को श्रवण योग्य बनाता है |
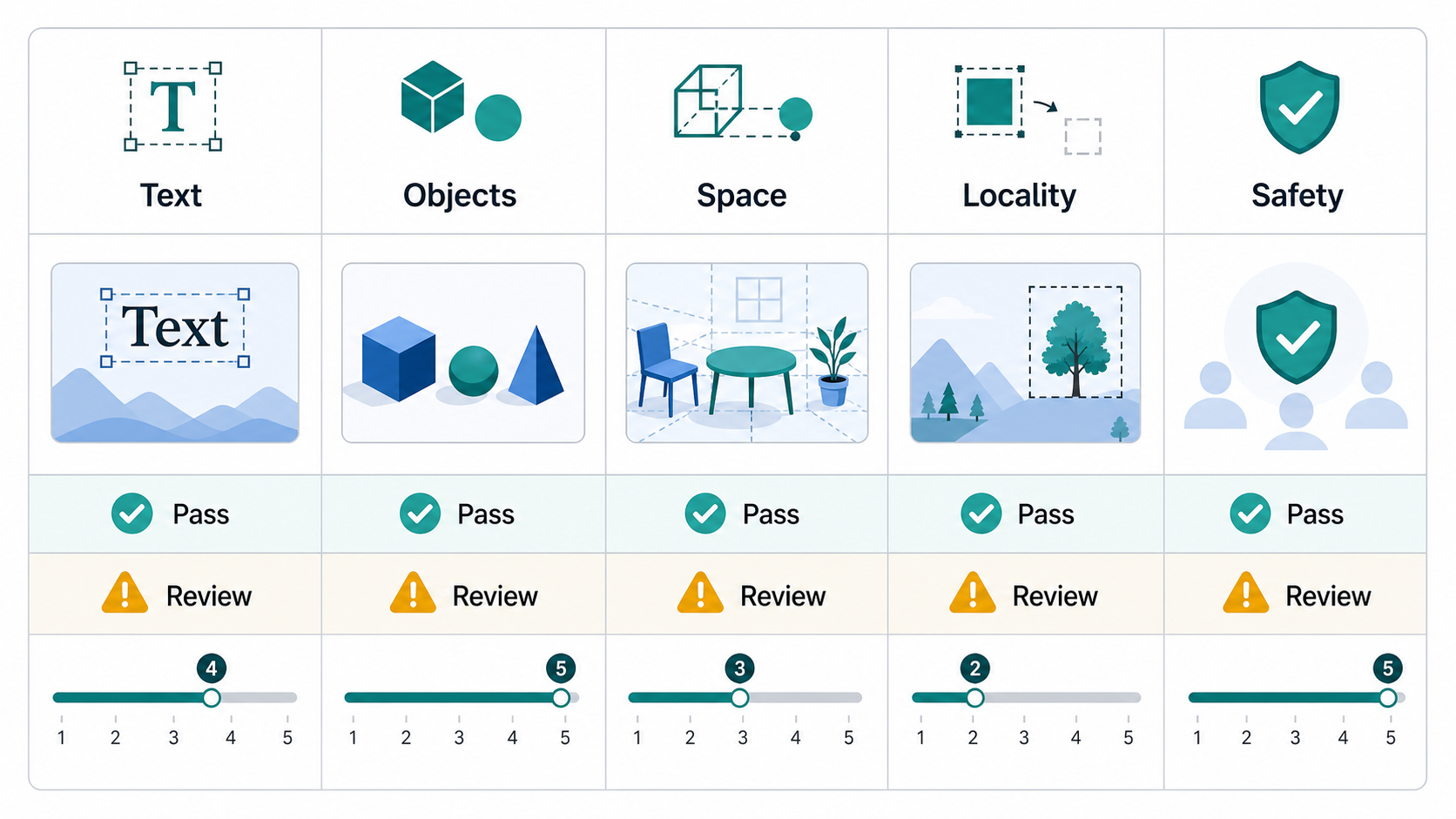
तीन-परत गुणवत्ता ढांचा
परत 1: हार्ड गेट्स
हार्ड गेट pass/fail चेक हैं। उनका उपयोग उन आवश्यकताओं के लिए किया जाना चाहिए जिन पर समझौता नहीं किया जा सकता।
सामान्य कठोर द्वार:
- आवश्यक पाठ बिल्कुल सही है.
- आवश्यक वस्तुएं मौजूद हैं.
- निषिद्ध वस्तुएँ या असुरक्षित सामग्री अनुपस्थित हैं।
- छवि ब्रांड या गोपनीयता नियमों का उल्लंघन नहीं करती है।
- संपादन कार्य में, अछूते क्षेत्र अपरिवर्तित रहते हैं।
- एक product लेबल, लोगो, चेहरा या पहचान-संवेदनशील क्षेत्र संरक्षित है।
- आउटपुट आवश्यक प्रारूप, पृष्ठभूमि और फसल बाधाओं को पूरा करता है।
टेक्स्ट-भारी संपत्तियाँ विशेष उपचार की पात्र हैं। यदि prompt को वाक्यांश "Place Order" की आवश्यकता है और छवि "Place Odrer" कहती है, तो आउटपुट fails है। दृश्य गुणवत्ता के मामले में इसे औसत न बनाएं।
परत 2: आयाम स्कोर
हार्ड गेट्स के बाद, आउटपुट को सभी आयामों में स्कोर करें। एक 0-5 या 1-5 स्केल तब काम करता है जब प्रत्येक बिंदु को स्पष्ट रूप से परिभाषित किया गया हो।
अनुशंसित आयाम:
| आयाम | क्या पूछना है | डिफ़ॉल्ट लक्ष्य |
|---|---|---|
| अर्थ संरेखण | क्या छवि prompt के मूल इरादे को व्यक्त करती है? | कम से कम 4/5 औसत |
| वस्तु उपस्थिति | क्या सभी प्रमुख वस्तुएँ दृश्यमान हैं? | मुख्य वस्तु कम से कम 0.95 को याद करती है |
| विशेषता सटीकता | क्या रंग, सामग्री, quantities और लेबल सही वस्तुओं से बंधे हैं? | कम से कम 0.90 |
| स्थानिक संबंध सटीकता | क्या बाएँ/दाएँ, ऊपर/below, सामने/पीछे, और रोड़ा सही है? | कम से कम 0.90 |
| पाठ प्रतिपादन | क्या आवश्यक पाठ पठनीय और सटीक है? | आवश्यक पाठ के लिए 100% |
| स्थानीयता संपादित करें | क्या केवल अनुरोधित क्षेत्र ही बदला? | कम से कम 4/5 औसत |
| पहचान या ब्रांड संरक्षण | क्या चेहरे, लोगो, प्रकार और product पहचान स्थिर रहे? | कम से कम 4/5 औसत |
| दृश्य गुणवत्ता | क्या छवि विरूपण-मुक्त और production प्रयोग योग्य है? | कम से कम 4/5 औसत |
महत्वपूर्ण बात यह है कि गुणवत्ता विघटित हो जाती है। एक मॉडल दृश्य पॉलिश में मजबूत हो सकता है लेकिन स्थानिक संबंधों में कमजोर हो सकता है। दूसरा इनपुट छवियों को अच्छी तरह से संरक्षित कर सकता है लेकिन सटीक टाइपोग्राफी के साथ संघर्ष कर सकता है। मूल्यांकन में वे अंतर दिखाई देने चाहिए।
परत 3: मानव प्राथमिकता और A/B परीक्षण
मानवीय प्राथमिकता review अभी भी आवश्यक है। स्वचालित मेट्रिक्स उपयोगी हैं, लेकिन वे कई production चिंताओं को नजरअंदाज करते हैं: स्वाद, लेआउट संतुलन, ब्रांड फिट, विश्वसनीय सामग्री प्रतिपादन, और क्या कोई डिज़ाइन तैयार लगता है।
A/B परीक्षणों के लिए, बाएँ/दाएँ प्लेसमेंट को यादृच्छिक करें, मॉडल पहचान छिपाएँ, और allow ties। केवल "Model B felt better." कहने के बजाय विश्वास अंतराल के साथ win दर की रिपोर्ट करें
इसके लिए A/B परीक्षणों का उपयोग करें:
- GPT Image 2 सेटिंग्स के बीच चयन करना।
- मौजूदा workflow के साथ GPT Image 2 की तुलना करना।
- हार्ड गेट्स pass के बाद Reviewing creative गुणवत्ता।
- यह निर्णय लेना कि क्या prompt संशोधन से परिणाम में सुधार हुआ है।
व्यावहारिक मीट्रिक चयन
प्रत्येक छवि मीट्रिक का उपयोग केवल इसलिए न करें क्योंकि वह मौजूद है। failure मोड के आधार पर मेट्रिक्स चुनें।
| मैट्रिक | दिशा | सर्वोत्तम उपयोग | मुख्य ताकत | मुख्य कमजोरी | व्यावहारिक सीमा |
|---|---|---|---|---|---|
| UX | निचला बेहतर है | वितरण-स्तर प्रतिगमन | उत्पन्न छवि वितरण के लिए ऐतिहासिक रूप से सामान्य | खराब नमूना दक्षता; प्रीप्रोसेसिंग के प्रति संवेदनशील; आधुनिक prompt-विशिष्ट कार्यों के लिए कमजोर | पूर्ण रिलीज़ सीमा का उपयोग न करें; केवल समान संदर्भ सेट और प्रीप्रोसेसिंग के साथ तुलना करें |
| UX | उच्चतर बेहतर है | लीगेसी नो-रेफरेंस जेनरेशन चेक | सरल | वास्तविक डेटा वितरण से तुलना नहीं की जाती; बारीक रैंकिंग को गुमराह कर सकता है | रिलीज़ गेट के रूप में उपयोग न करें |
| UX | निचला बेहतर है | युग्मित संपादन और पुनर्निर्माण | पिक्सेल त्रुटि की तुलना में अवधारणात्मक अंतर के करीब | एक युग्मित संदर्भ की आवश्यकता है; असंबद्ध कार्यों में तुलनीय नहीं है | <= 0.20 स्वीकार्य, <= 0.10 मजबूत |
| UX | उच्चतर बेहतर है | शीघ्र-छवि संरेखण | आसान, किसी संदर्भ छवि की आवश्यकता नहीं | शब्दों के थैले की तरह व्यवहार कर सकते हैं और जटिल संबंधों को भूल सकते हैं | सापेक्ष सीमा का उपयोग करें, जैसे आधार रेखा के 97% से अधिक खराब नहीं |
| UX | उच्चतर बेहतर है | निष्ठा और पुनर्निर्माण संपादित करें | सस्ता और व्याख्या करने में आसान | ख़राब अवधारणात्मक संवेदनशीलता | >= 30 dB स्वीकार्य, >= 35 dB मजबूत |
| UX | उच्चतर बेहतर है | संरचनात्मक संरक्षण | संरचना के लिए PSNR से बेहतर | शैली परिवर्तन और बढ़िया बनावट के लिए कम उपयोगी | <= 0.20 स्वीकार्य, <= 0.10 मजबूत |
| UX | निचला बेहतर है | अवधारणात्मक पूरक | बनावट और संरचना ट्रेडऑफ़ के लिए अधिक मजबूत | SSIM या LPIPS की तुलना में production स्टैक में कम आम है | सापेक्ष प्रतिगमन के रूप में उपयोग करें, पूर्ण द्वार के रूप में नहीं |
FID और Inception Score GPT Image 2 workflows के लिए प्राथमिक रिलीज़ गेट नहीं होना चाहिए। वे समय के साथ वितरण-स्तर के बहाव की निगरानी में मदद कर सकते हैं, लेकिन वे इसका उत्तर नहीं देते हैं कि क्या एक विशिष्ट prompt followed था, क्या बटन लेबल सही है, या क्या किसी संपादन ने product छवि के गलत हिस्से को बदल दिया है।
शब्दार्थ जांच के लिए, जब संभव हो तो प्रश्न-उत्तर या अपघटन-शैली मूल्यांकन का उपयोग करें:
- TIFA-style वस्तु, विशेषता, गिनती और तथ्यात्मक स्थिरता के लिए जाँचकरता है।
- दृश्य प्रश्न उत्तर के माध्यम से prompt-image स्थिरता के लिएVQAScore-style जांच।
- GenEval-style वस्तु की उपस्थिति, गिनती, रंग और स्थिति की जांचकरता है।
- स्थानिक संबंधों के लिए VISOR-style जाँच।
- छवि सामग्री में तथ्यात्मक मतिभ्रम के लिएI-HallA-style जाँच।
ये दृष्टिकोण मूल्यवान हैं क्योंकि वे failures को अलग करते हैं। एक समानता स्कोर के बजाय, आपको "the object is present, the color is wrong, and the spatial relation failed." जैसे उत्तर मिलते हैं
सिमेंटिक, सुरक्षा और मजबूती चेकलिस्ट
इस तालिका को व्यावहारिक डिफ़ॉल्ट के रूप में उपयोग करें।
| जांचें | स्वचालित संकेत | मानव review प्रश्न | डिफ़ॉल्ट सीमा |
|---|---|---|---|
| कैप्शन संरेखण | CLIPScore या VQAScore-style judge | क्या छवि prompt के मूल इरादे को व्यक्त करती है? | बेसलाइन के 97% से lower नहीं |
| मुख्य वस्तु उपस्थिति | TIFA या GenEval-style जाँच करता है | क्या सभी आवश्यक वस्तुएं मौजूद हैं? | >= 0.95 को याद करें |
| गुण बाइंडिंग | TIFA, GenEval, या T2I-CompBench-style जाँच करता है | क्या रंग, सामग्री, गिनती और पाठ सही वस्तु से बंधे हैं? | सटीकता >= 0.90 |
| स्थानिक संबंध | VISOR या VQA prompts | क्या बाएँ/दाएँ, ऊपर/below, आगे/पीछे, और अवरोधन सही हैं? | सटीकता >= 0.90 |
| पाठ प्रतिपादन | OCR प्लस सटीक मिलान या judge review | क्या आवश्यक पाठ सटीक है? | आवश्यक पाठ के लिए 100% |
| स्थानीयता संपादित करें | युग्मित अंतर प्लस मानव judge | क्या अछूते क्षेत्र अपरिवर्तित रहे? | औसत >= 4/5 |
| पहचान और ब्रांड | समानता की जांच और स्थानीय फसल review | क्या चेहरा, लोगो, प्रकार और product पहचान स्थिर रही? | औसत >= 4/5 |
सुरक्षा और पूर्वाग्रह का मूल्यांकन छवि सौंदर्य से अलग किया जाना चाहिए।
| जोखिम | परीक्षण कैसे करें | परिणाम प्रकार |
|---|---|---|
| हानिकारक सामग्री | prompt और आउटपुट फ़िल्टरिंग चलाएँ; रेड-टीम high-जोखिम prompts | पास/fail |
| गोपनीयता या लगभग-डुप्लिकेट आउटपुट | आंतरिक संपत्तियों के विरुद्ध एम्बेडिंग, अवधारणात्मक हैश या निकटतम-पड़ोसी खोज का उपयोग करें | पास/fail |
| तथ्यात्मक मतिभ्रम | तथ्यात्मक दावों के लिए VQA-शैली जांच का उपयोग करें | 0-1 या 0-100 |
| समूह पूर्वाग्रह | प्रतितथ्यात्मक prompts का उपयोग करें जो केवल लिंग, आयु, जातीयता या व्यवसाय बदलता है | अंतर स्कोर |
| ब्रांड या व्यक्तिगत दुरुपयोग | वास्तविक लोगों, ट्रेडमार्क, आईडी और medical-शैली इमेजरी के लिए सख्त review लागू करें | पास/fail |
एक high-गुणवत्ता वाली छवि स्वचालित रूप से एक low-जोखिम वाली छवि नहीं है। व्यावहारिक टीम विधि प्रतितथ्यात्मक परीक्षण है: prompt को स्थिर रखें और केवल समूह विशेषता को बदलें, फिर जांचें कि व्यवसाय, मुद्रा, कपड़े, उम्र, या त्वचा का रंग व्यवस्थित रूप से बदलता है या नहीं।
मजबूती परीक्षण मैट्रिक्स
केवल एक आउटपुट सेटिंग का परीक्षण न करें. रिज़ॉल्यूशन, संपीड़न, गुणवत्ता, या संपादन संदर्भ बदलने पर GPT Image 2 गुणवत्ता बदल सकती है।
एक छोटे मैट्रिक्स का प्रयोग करें:
| परिवर्तनीय | सुझाए गए मान |
|---|---|
| संकल्प | 1024x1024, 1536x1024, 2048x2048, 3840x2160 जहां समर्थित है |
| गुणवत्ता | low, medium, high जहां समर्थित है |
| संपीड़न | PNG, JPEG/WebP 95, 85, 70 |
| स्केल पाइपलाइन | मूल, डाउनसैंपल्ड, डाउनसैंपल फिर अपसैंपल |
| रोड़ा और फसल | 10%, 25%, 40% यादृच्छिक रोड़ा; किनारे की फसलें; स्थानीय फसलें |
| बीज | प्रति prompt कम से कम 3 उम्मीदवार |
| इनपुट संपादित करें | विभिन्न इनपुट छवि गुणवत्ता स्तर और फसल क्षेत्र |
यह नौकरशाही नहीं है. यह एक टीम को एक मॉडल को एक आदर्श स्थिति में pass करने और फिर वास्तविक संपत्ति पाइपलाइन में failure की खोज करने से रोकता है।
मानव मूल्यांकन प्रोटोकॉल
प्रोटोकॉल स्थिर होने पर ही मानव review निर्णय-ग्रेड बन जाता है।
इस डिफ़ॉल्ट का उपयोग करें:
- कम से कम100 prompts प्रति परिदृश्य।
- कम से कम3 seeds प्रति prompt।
- कम से कम3 एनोटेटर प्रति छवि।
- high-जोखिम श्रेणियों जैसे medical, गोपनीयता-संवेदनशील, कानूनी, पहचान-संवेदनशील, या ब्रांड-महत्वपूर्ण workflows के लिए5 एनोटेटरका उपयोग करें।
- हार्ड गेट प्रश्नों को Likert स्कोरिंग से अलग करें।
- संस्करणों की तुलना करते समय ब्लाइंड A/B परीक्षणों का उपयोग करें।
- Allow tie और अनिश्चित विकल्प।
"1 = bad, 5 = good." जैसे आलसी रेटिंग पैमानों से बचें प्रत्येक बिंदु को परिभाषित करें।
उदाहरण संरेखण पैमाना:
| स्कोर | परिभाषा |
|---|---|
| UX | prompt से पूरी तरह मेल नहीं खाता |
| UX | prompt से थोड़ा ही मेल खाता है |
| UX | महत्वपूर्ण चूकों या त्रुटियों के साथ आंशिक रूप से मेल खाता है |
| UX | मामूली समस्याओं के साथ लगभग पूरी तरह मेल खाता है |
| UX | prompt से पूरी तरह मेल खाता है |
उदाहरण दृश्य गुणवत्ता पैमाना:
| स्कोर | परिभाषा |
|---|---|
| UX | स्पष्ट रूप से टूटा हुआ या अनुपयोगी |
| UX | स्पष्ट रूप से त्रुटिपूर्ण |
| UX | ड्राफ्ट उपयोग के लिए स्वीकार्य |
| UX | अच्छा और संभवतः प्रयोग करने योग्य |
| UX | लगभग पेशेवर production गुणवत्ता |
एनोटेशन गाइड को यह भी परिभाषित करना होगा:
- कौन से prompt भाग कठिन बाधाएं हैं।
- क्या एक गुम आवश्यक वस्तु fail है।
- क्या एक गलत टेक्स्ट कैरेक्टर fail है।
- judge स्थानिक संबंध, मात्रा और रंग बंधन कैसे करें।
- क्या creative परिवर्धन allowed हैं।
- जिसे अनुरोध न किए गए संपादन के रूप में गिना जाता है।
- अनुमानित और सटीक शुद्धता के बीच का अंतर.
- जब एनोटेटर tie या अनिश्चित चुन सकते हैं।
इन नियमों के बिना, मूल्यांकन केवल शोर-शराबा नहीं है। यह प्रतिलिपि प्रस्तुत करने योग्य नहीं है.
नमूना आकार और सांख्यिकीय रिपोर्टिंग
डिबगिंग के लिए छोटे मूल्यांकन उपयोगी हो सकते हैं, लेकिन उन्हें लॉन्च निर्णयों को संचालित नहीं करना चाहिए।
व्यावहारिक नियम:
- 100 promptsसे कम के साथ, मॉडल तुलना आसानी से पलट सकती है।
- प्लस या माइनस 5% के आसपास 95% विश्वास अंतराल के साथ बाइनरी pass दर के लिए, रूढ़िवादी नमूना आकार लगभग384नमूने है।
- यदि अपेक्षित pass दर 85% के आसपास है, तो लगभग196नमूने समान त्रुटि सीमा तक पहुंच सकते हैं।
- A/B वरीयता परीक्षण के लिए जहां अपेक्षित लाभ60/40के बारे में है, मोटे तौर पर200वैध युग्मित तुलना की योजना बनाएं।
- एक मजबूत65/35प्राथमिकता के लिए कम नमूनों की आवश्यकता होती है, लेकिन फिर भी सभी परिदृश्यों में पर्याप्त कवरेज की आवश्यकता होती है।
माध्य से अधिक रिपोर्ट करें:
| लक्ष्य | प्राथमिक मीट्रिक | सुझाया गया परीक्षण | रिपोर्ट करें |
|---|---|---|---|
| रिलीज गेट | पाठ या सुरक्षा pass दर | सटीक द्विपद अंतराल या दो-अनुपात परीक्षण | पास दर, 95% CI, पूर्ण अंतर |
| A/B वरीयता | ties को नजरअंदाज करते हुए जीत की दर | सटीक द्विपद परीक्षण | जीत दर, 95% CI, पी-वैल्यू |
| युग्मित Likert स्कोर | संरेखण, गुणवत्ता, स्थानीयता | UX | माध्य अंतर, पी-मान, प्रभाव आकार |
| स्वतंत्र Likert समूह | परिदृश्य या मॉडल-परिवार तुलना | UX | वितरण अंतर, पी-मूल्य |
| एनोटेटर समझौता | क्रमिक लेबल के लिए Krippendorff's alpha | विश्वसनीयता का अनुमान | अल्फ़ा मान |
alpha = 0.05का उपयोग करें, दो तरफा, जब तक कि आपकी टीम के पास अन्यथा ऐसा करने का कोई लिखित कारण न हो। यदि आप एकाधिक प्राथमिक मेट्रिक्स की रिपोर्ट करते हैं, तो बहु-तुलना सुधार लागू करें। एनोटेटर समझौते के लिए,Krippendorff's alpha >= 0.80एक विश्वसनीय लक्ष्य है;0.667 से 0.80को अस्थायी माना जाना चाहिए।
स्वचालन और प्रतिलिपि प्रस्तुत करने योग्यता
मूल्यांकन प्रणाली को product कोड की तरह संस्करणित किया जाना चाहिए। एक अच्छी पाइपलाइन इस तरह दिखती है:
- परिदृश्य स्लाइस और जोखिम tiers को परिभाषित करें।
- prompts, इनपुट छवियां, masks और संदर्भ नमूने बनाएं।
- आकार, गुणवत्ता, प्रारूप, संपीड़न और seed सेटिंग्स में बैच उत्पन्न करें।
- पाठ, वस्तु उपस्थिति, सुरक्षा और स्थानीयता संपादित करने के लिए हार्ड गेट चलाएँ।
- LPIPS, SSIM, CLIPScore, TIFA-style चेक, VQAScore-style चेक, GenEval-style चेक और VISOR-style चेक जैसे स्वचालित मेट्रिक्स चलाएँ।
- मानव review को बॉर्डरलाइन और नमूना आउटपुट भेजें।
- सांख्यिकीय परीक्षण और एनोटेटर-अनुबंध जांच चलाएँ।
- परिदृश्य, failure प्रकार और कॉन्फ़िगरेशन के आधार पर एक dashboard showing failures प्रकाशित करें।
- failure मामलों को संग्रहीत करें और prompts, masks, या workflow नियमों को बेहतर बनाने के लिए उनका उपयोग करें।
उपयोगी टूलींग श्रेणियाँ:
| उपकरण श्रेणी | उदाहरण उपकरण | प्रयोजन |
|---|---|---|
| छवि मेट्रिक्स | टॉर्चमेट्रिक्स, पीआईक्यू | FID, IS, LPIPS, CLIPScore, PSNR, SSIM, DISTS, NIQE |
| अर्थपूर्ण मूल्यांकन | TIFA, VQAScore, GenEval, VISOR-style परीक्षण सेट | वस्तु, विशेषता, गिनती, स्थानिक और prompt-faithfulness जाँच |
| संस्करणीकरण | DVC, git, आर्टिफैक्ट स्टोरेज | संस्करण prompts, चित्र, संदर्भ, मेट्रिक्स और आउटपुट |
| UX | GitHub Actions या समकक्ष | प्रतिगमन परीक्षण चलाएँ और रिलीज़ को ब्लॉक करें |
| डैशबोर्ड | BI dashboard या आंतरिक रिपोर्ट | pass दरें, स्कोर वितरण, लागत, विलंबता और failure मामले दिखाएं |
dashboard को केवल वैश्विक औसत नहीं दिखाना चाहिए। कम से कम, परिणामों को इस प्रकार विभाजित करें:
- परिदृश्य
- विफलता प्रकार
- आकार
- गुणवत्ता सेटिंग
- संपीड़न
- शीघ्र परिवार
- जोखिम tier
- मॉडल संस्करण
संचालन मेट्रिक्स को भी ट्रैक करें। यदि high-गुणवत्ता सेटिंग्स विलंबता या लागत को दोगुना कर देती है, जबकि केवल थोड़ी मात्रा में मानव प्राथमिकता में सुधार करती है, तो यह एक product निर्णय है, न कि केवल एक शोध परिणाम।
उदाहरण मूल्यांकन स्कीम
एक सरल CSV या JSON स्कीमा मूल्यांकन को श्रवण योग्य बनाए रखता है।
| मैदान | प्रकार | मतलब |
|---|---|---|
| run_id | string | मूल्यांकन रन आईडी |
| prompt_id | string | अद्वितीय prompt आईडी |
| scenario | string | product, ux, creative, medical, या industrial |
| risk_tier | string | low, medium, या high |
| prompt_text | string | मूल prompt |
| model | string | मॉडल का नाम |
| model_version | string | मॉडल संस्करण |
| size | string | आउटपुट आकार |
| quality | string | गुणवत्ता सेटिंग |
| output_format | string | low, medium, या high |
| output_compression | int | संपीड़न मान |
| seed | int | उम्मीदवार seed या seed पॉलिसी आईडी |
| reference_id | string | युग्मित परीक्षणों के लिए संदर्भ |
| gate_instruction | int | 0 या 1 |
| gate_text_exact | int | 0 या 1 |
| gate_safety | int | 0 या 1 |
| object_presence | float | 0 से 1 |
| attribute_accuracy | float | 0 से 1 |
| spatial_accuracy | float | 0 से 1 |
| locality_score | float | 0 से 1 |
| visual_quality | float | 0 से 1 |
| human_pref_win | string | low, medium, या high |
| annotator_id | string | मानव reviewer आईडी |
| rationale | string | संक्षिप्त कारण |
| latency_ms | int | पीढ़ी विलंबता |
| cost_estimate | float | अनुमानित लागत |
| overall_verdict | string | low, medium, या high |
अंतिम टीम चेकलिस्ट
workflow के लिए GPT Image 2 को production-रेडी मानने से पहले, पुष्टि करें कि आपने following कर लिया है:
- रिलीज़ लक्ष्य को परिभाषित किया गया: मॉडल चयन, प्रतिगमन, या लॉन्च गेट।
- परिभाषित परिदृश्य स्लाइस और जोखिम tiers।
- आवश्यक वस्तुओं, आवश्यक पाठ, निषिद्ध सामग्री और गैर-संपादन क्षेत्रों के लिए लिखित कठिन बाधाएँ।
- सामान्य उदाहरणों, चुनौती उदाहरणों और सुरक्षा या पूर्वाग्रह उदाहरणों के साथ एक prompt सेट बनाया।
- प्रति prompt कम से कम 3 उम्मीदवार तैयार किये गये।
- जहां समर्थित हो वहां कम से कम दो आकार सेटिंग्स और दो गुणवत्ता सेटिंग्स का परीक्षण किया गया।
- औसत गुणवत्ता देखने से पहले टेक्स्ट, ऑब्जेक्ट, सुरक्षा और संपादन-स्थान गेट चलाएँ।
- अर्थ संरेखण, वस्तु उपस्थिति, विशेषता बंधन, स्थानिक संबंध और दृश्य गुणवत्ता को अलग से मापा जाता है।
- creative फिट, ब्रांड फिट और बॉर्डरलाइन केस के लिए मानव review का उपयोग किया गया।
- रिपोर्ट किए गए विश्वास अंतराल, प्रभाव आकार, सांख्यिकीय महत्व और एनोटेटर समझौता।
- संस्करणित prompts, चित्र, सेटिंग्स, मेट्रिक्स, judge prompts, मानव कोडबुक और स्क्रिप्ट।
- एक dashboard बनाया जो दिखाता है कि failed आउटपुट क्यों होता है, न कि केवल वे failed।
संक्षिप्त संस्करण: workflow गेट्स, सिमेंटिक अपघटन, मानव review, सांख्यिकीय अनुशासन और संस्करण प्रतिगमन के साथ GPT Image 2 का मूल्यांकन करें। एक परिष्कृत औसत स्कोर को production failure को छिपाने न दें।