GPT Image 2 の出力品質を、ハードゲート、意味チェック、画像指標、人によるレビュー、堅牢性テスト、CI 向けレポートで評価する、チーム向けの実践フレームワーク。
GPT Image 2 の出力品質を評価することは、画像が印象的に見えるかどうかを問うことと同じではありません。必要なテキストのスペルが間違っていたり、製品ラベルが変更されたり、UI ボタンが欠落していたり、ロゴがずれていたり、編集によって変更されていないはずの画像の部分が変更されたりすると、美しい画像でもジョブが失敗する可能性があります。
チームにとって、より良い質問は、GPT Image 2 がこのワークフローを確実に完了して出荷できるかどうかということです。
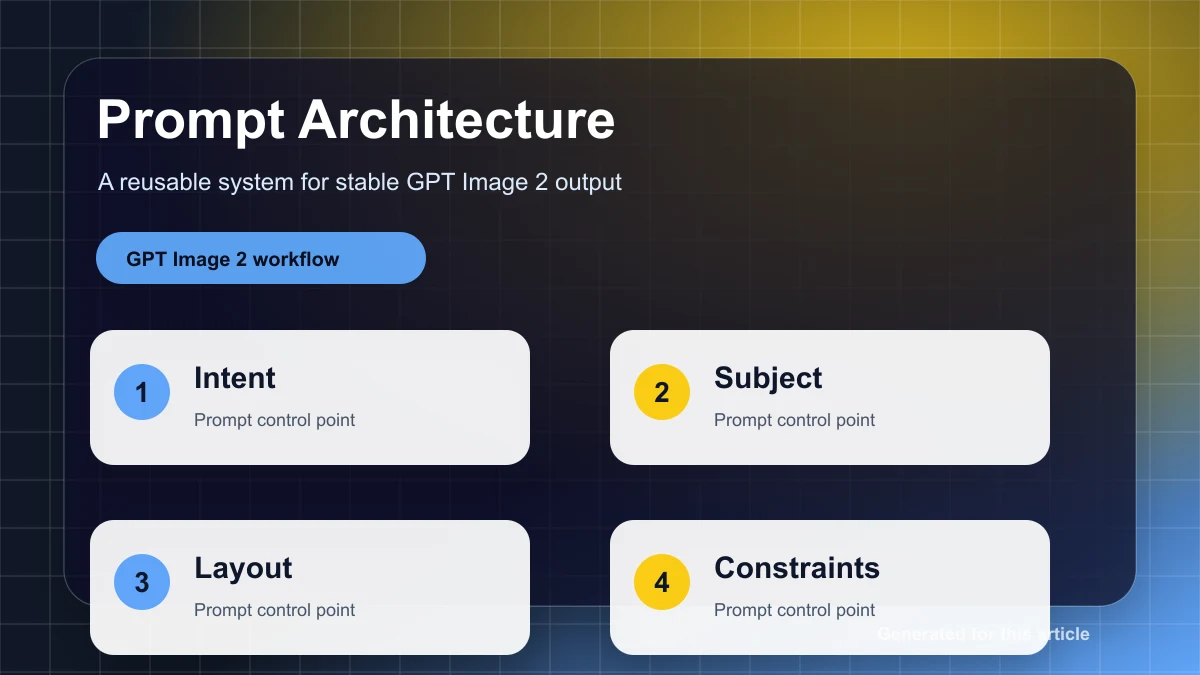
この質問には、構造化された評価システムが必要です。最も有用なアプローチは、3 層モデルです。
- 正確なテキスト、安全性、必要なオブジェクト、編集のローカリティなど、交渉の余地のない要件のためのハード ゲート。
- 次元レベルのスコアリングにより、セマンティックな整合性、ビジュアル品質、空間精度、ブランドの一貫性、保存性が向上します。
- 自動化された指標では不十分な決定については、人間の好みまたは A/B レビューを使用します。
画質を 1 つの平均スコアまで下げないでください。スコアが 1 つあると、実際に重要な故障モードが隠れてしまいます。ビジュアル スコアが 4.6/5 であるものの、見出しに 1 文字間違っているマーケティング ポスターは「ほぼ良好」ではありません。それは失敗した本番資産です。
このチェックリストは、実際のワークフロー全体で GPT Image 2 の出力を比較する必要があるバイヤー、クリエイター、製品チーム、デザイン チーム、QA チーム、エンジニアリング チーム向けに設計されています。 FID や Inception Score などの従来のメトリクスを過度に信頼するというよくある罠を回避しながら、本格的な画像モデルのテストで使用される実用的なしきい値と評価構造を保持します。
モデルではなくワークフローから始める
メトリクスを選択する前に、シナリオを定義します。製品画像、モバイル UI モックアップ、ポスター、キャラクター シート、医療指導図も同じように失敗するわけではありません。
データセットがまだ指定されていない場合は、最初に評価をシナリオ スライスに分割します。次に、各スライスでどのチェックが重要かを決定します。
| ドメイン | GPT Image 2 の一般的な使用例 | 最初の品質チェック | 注意事項 |
|---|---|---|---|
| 製品 | 白背景の製品写真、パッケージ、広告、ブランド資産の編集 | 正確なテキスト、完全なラベル、きれいなエッジ、こぼれないローカル編集 | ペア編集テストやハードゲートに最適 |
| UX | UIモックアップ、フロー画面、情報アーキテクチャ図、ボタンコピー画像 | 必要なコンポーネント、レイアウト階層、正確なボタンのテキスト、使いやすさ | テキストゲートはビューティースコアの前に来る必要があります |
| クリエイティブ | 広告キービジュアル、コミックス、絵コンテ、ポスター、キャラクターシート | スタイルの一貫性、物語の連続性、読みやすいテキスト、ブランドまたはキャラクターの一貫性 | 人間の好みは非常に価値のあるものです |
| 医療 | 教育イラスト、合成医療スタイルのビジュアル、症例スタイルの図 | プライバシー、重複リスク、事実性、臨床的に関連する属性 | ユースケースと規制基準は個別に調整する必要がある |
| 産業用 | 機器ラベル、メンテナンスイラスト、テクニカルボード、コンセプトビジュアル | テキストと記号の正確さ、空間的関係、材質と構造の妥当性 | 発売前に業界の許容範囲を定義する必要がある |
チームのリソースが限られている場合は、4 つのスライスから始めます。
- テキストの多いポスター
- UI モックアップ
- ローカル画像編集
- 複雑な構成 prompts
これら 4 つのカテゴリは、テキストのスペルミス、要素の欠落、弱い空間推論、過剰編集、浅い prompt フォローなど、本番環境で重要な問題の多くを明らかにします。
生成テストと編集テストを分離する
GPT Image 2 の評価は 2 つのトラックに分割する必要があります。
生成テストは prompt から開始され、正確な参照イメージはありません。中心的な問題は、画像が prompt (オブジェクト、属性、関係、数、スタイル、テキスト、安全制約) に従っているかどうかです。
編集テストは入力画像から始まり、場合によっては mask またはターゲット領域を使用します。中心となる問題は、他のすべてが安定している間に、要求された変更が行われたかどうかです。編集の品質は「最終的な画像がきれいに見えるかどうか」だけではありません。また、「モデルはアイデンティティ、レイアウト、ロゴの形状、製品の詳細、および手つかずの領域を保持したか?」
両方のトラックについて、実行ごとにバージョンを付けます。画像生成ワークフローに関する OpenAI の公式ドキュメントによると、チームは出力サイズ、品質、形式、可能な場合は圧縮などのモデル構成フィールドに注意を払う必要があります。これらの設定、前処理ルール、および prompt バージョンがロックされていない限り、実行を比較しないでください。
少なくとも次のものを保管します。
| フィールド | なぜそれが重要なのか |
|---|---|
| モデルとモデルのバージョン | 非表示のモデルの変更が prompt の変更のように見えないようにする |
| prompt バージョン | 回帰分析が可能になります |
| サイズと品質 | 出力品質は解像度と品質設定によって変化する可能性があります |
| 出力形式と圧縮 | JPEG/WebP 圧縮により、OCR、メトリクス、および視覚的なアーティファクトが変更される可能性があります |
| 入力画像ハッシュ | 編集の再現性のために必要 |
| 参照セットのハッシュ | ペアテストに必須 |
| seed ポリシー | promptごとに複数の候補を比較する場合に必要 |
| judge prompt バージョン | 自動化されたjudgeは測定システムの一部です |
| 人間のコードブックバージョン | アノテーターのルールは安定している必要があります |
| CI ジョブと git commit | 決定を監査可能にする |
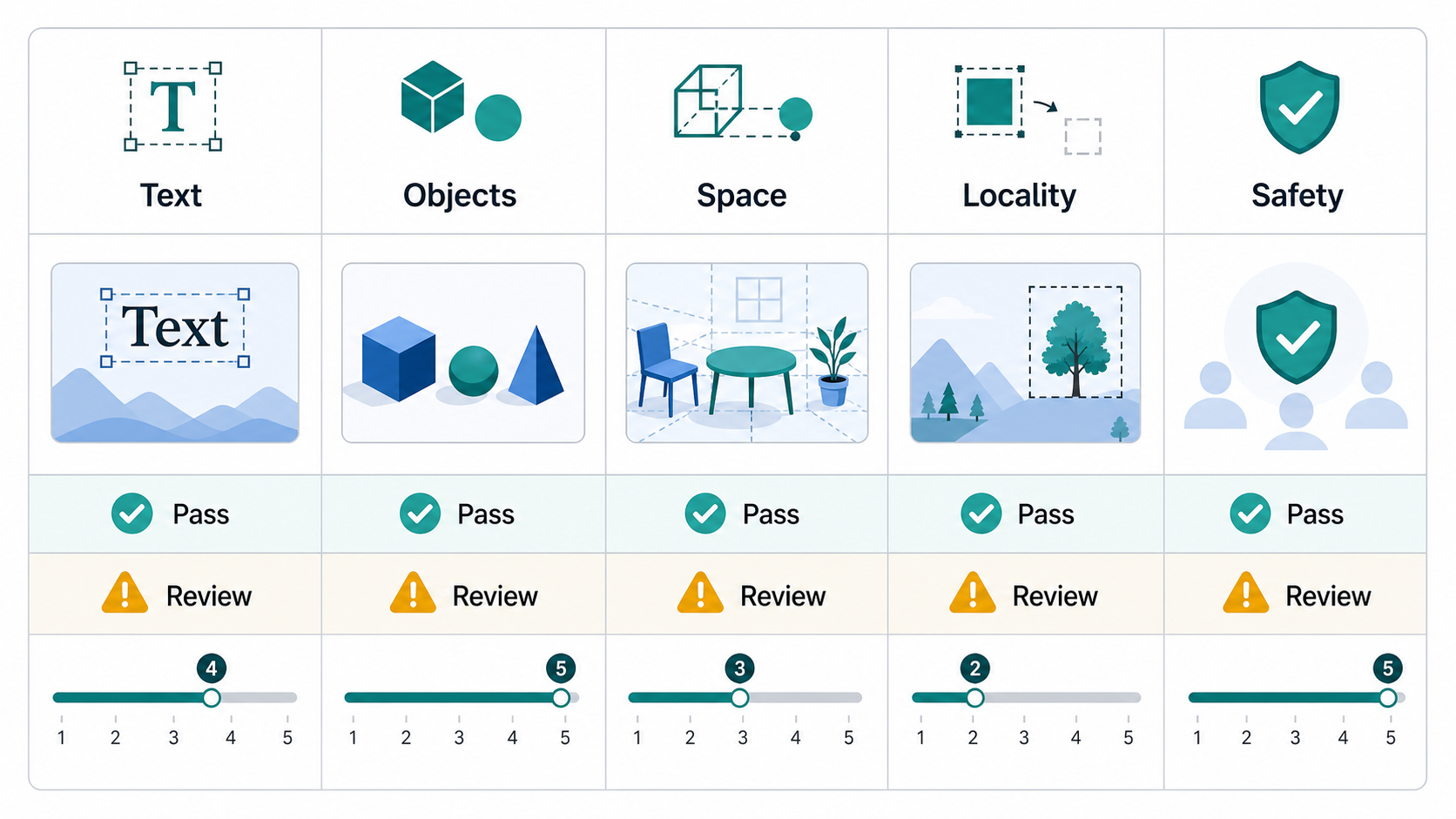
3 層の品質フレームワーク
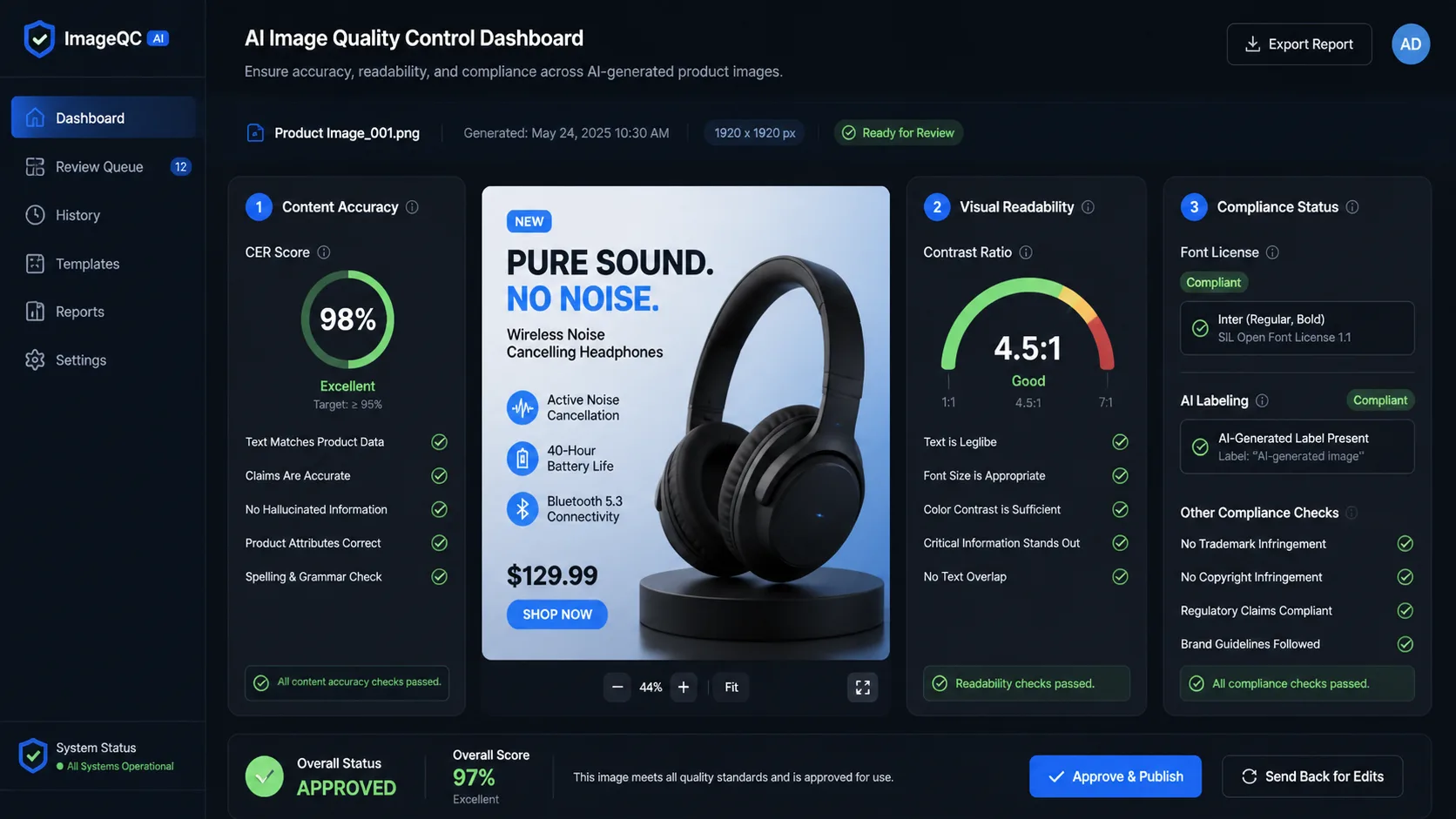
レイヤー 1: ハード ゲート
ハードゲートは合否チェックです。交渉の余地のない要件に使用する必要があります。
一般的なハード ゲート:
- 必須のテキストは正確です。
- 必要なオブジェクトが存在します。
- 禁止されたオブジェクトや安全でないコンテンツは存在しません。
- 画像はブランドやプライバシーの規則に違反していません。
- 編集タスクでは、タッチされていない領域は変更されません。
- 製品ラベル、ロゴ、顔、またはアイデンティティに敏感な領域は保持されます。
- 出力は、必要な形式、背景、切り抜きの制約を満たしています。
テキストの多いアセットは特別な扱いに値します。 prompt に「Place Order」というフレーズが必要で、画像に「Place Odrer」と表示されている場合、出力は失敗します。それを視覚的な品質で平均化しないでください。
レイヤー 2: ディメンション スコア
ハードゲートの後、次元全体で出力をスコアリングします。すべての点が明確に定義されている場合、0-5 または 1-5 スケールが機能します。
推奨寸法:
| 次元 | 何を尋ねるべきか | デフォルトのターゲット |
|---|---|---|
| セマンティックな調整 | 画像はpromptの中心的な意図を表現していますか? | 平均 4/5 以上 |
| オブジェクトの存在 | すべてのキー オブジェクトが表示されていますか? | キーオブジェクトは少なくとも 0.95 をリコールします |
| 属性の精度 | 色、素材、数量、ラベルは適切なオブジェクトにバインドされていますか? | 少なくとも 0.90 |
| 空間関係の精度 | 左/右、上/下、前/後ろ、噛み合わせは正しいですか? | 少なくとも 0.90 |
| テキストのレンダリング | 必要なテキストは読みやすく、正確ですか? | 必須テキストの 100% |
| 地域の編集 | 要求されたリージョンのみが変更されましたか? | 平均 4/5 以上 |
| アイデンティティまたはブランドの保護 | 顔、ロゴ、タイプ、製品のアイデンティティは安定していましたか? | 平均 4/5 以上 |
| ビジュアル品質 | 画像にアーチファクトはなく、制作に使用できますか? | 平均 4/5 以上 |
重要な点は、品質が分解されるということです。モデルは視覚的な洗練には優れていますが、空間的な関係には弱い場合があります。別の例では、入力画像はうまく保存されますが、正確なタイポグラフィに苦労する場合があります。評価では、それらの違いが見えるようにする必要があります。
レイヤー 3: 人間の好みと A/B テスト
人間の好みの検討は依然として必要です。自動化されたメトリクスは便利ですが、テイスト、レイアウトのバランス、ブランドの適合性、マテリアルのレンダリング、デザインが完成したと感じられるかどうかなど、制作上の多くの懸念事項を見逃しています。
A/B テストの場合、左右の配置をランダム化し、モデル ID を非表示にし、タイを許可します。 「モデル B の方が良いと感じた」とだけ言うのではなく、信頼区間を使用して勝率を報告します。
A/B テストは次の目的で使用します。
- GPT Image 2 設定から選択します。
- GPT Image 2 と既存のワークフローを比較します。
- 厳しい関門を通過した後にクリエイティブの品質をレビューします。
- prompt リビジョンによって結果が改善されたかどうかを判断します。
実用的なメトリクスの選択
存在するからといって、すべての画像メトリクスを使用しないでください。障害モードに基づいてメトリクスを選択します。
| メトリック | 方向 | 最適な使用方法 | 主な強み | 主な弱点 | 実用的な閾値 |
|---|---|---|---|---|---|
| UX | 低いほど良い | 分布レベルの回帰 | 生成された画像ディストリビューションでは歴史的に一般的 | サンプル効率が低い。前処理に敏感。最新の prompt 固有のタスクには弱い | 絶対的なリリースしきい値は使用しないでください。同じ参照セットと前処理のみで比較します。 |
| UX | 高いほど良い | 従来の非参照生成チェック | シンプル | 実際のデータ分布とは比較できません。きめ細かいランキングが誤解を招く可能性がある | リリースゲートとして使用しないでください |
| UX | 低いほど良い | ペア編集と再構築 | ピクセル誤差よりも知覚的な違いに近い | ペアの参照が必要です。無関係なタスク間では比較できない | <= 0.20 許容可能、<= 0.10 強力 |
| UX | 高いほど良い | プロンプト画像の位置合わせ | 簡単、参考画像不要 | 袋詰めのスコアのように動作し、複雑な関係を見逃す可能性があります | ベースラインの 97% 以下などの相対的なしきい値を使用します。 |
| UX | 高いほど良い | 編集の忠実性と再構築 | 安価で解釈が簡単 | 知覚感度が低い | >= 30 dB は許容可能、>= 35 dB は強力 |
| UX | 高いほど良い | 構造保存 | 構造的にはPSNRよりも優れています | スタイルの変更や細かいテクスチャにはあまり役に立たない | <= 0.20 許容可能、<= 0.10 強力 |
| UX | 低いほど良い | 知覚サプリメント | テクスチャと構造のトレードオフに対してより堅牢 | 実稼働スタックでは、SSIM または LPIPS よりも一般的ではありません。 | 絶対ゲートではなく相対回帰として使用します |
FID および Inception Score は、GPT Image 2 ワークフローのプライマリ リリース ゲートであってはなりません。これらは、時間の経過に伴う配布レベルのドリフトを監視するのに役立ちますが、特定の prompt に従っていたかどうか、ボタンのラベルが正しいかどうか、または編集により製品画像の間違った部分が変更されたかどうかには答えません。
セマンティック チェックの場合は、可能であれば質問応答または分解スタイルの評価を使用します。
- TIFA-style は、オブジェクト、属性、数、および事実の一貫性をチェックします。
- VQAScore-style は、視覚的な質問応答を通じて prompt-image の一貫性をチェックします。
- GenEval-style はオブジェクトの存在、数、色、位置をチェックします。
- VISOR-style は空間関係をチェックします。
- I-HallA-style は、画像コンテンツ内の事実上の幻覚をチェックします。
これらのアプローチは、失敗を分解するため価値があります。 1 つの類似性スコアの代わりに、「オブジェクトが存在する、色が間違っている、空間的関係が失敗している」などの回答が得られます。
セマンティック、安全性、堅牢性のチェックリスト
この表を実用的なデフォルトとして使用してください。
| チェックする | 自動信号 | 人間によるレビューの質問 | デフォルトのしきい値 |
|---|---|---|---|
| キャプションの配置 | CLIPScore または VQAScore-style judge | 画像はpromptの中心的な意図を表現していますか? | ベースラインの 97% 以上 |
| キーオブジェクトの存在 | TIFA または GenEval-style チェック | 必要なオブジェクトはすべて存在しますか? | リコール >= 0.95 |
| 属性バインディング | TIFA、GenEval、または T2I-CompBench-style チェック | 色、素材、数、テキストは正しいオブジェクトにバインドされていますか? | 精度 >= 0.90 |
| 空間関係 | VISOR または VQA prompts | 左右、上下、前後、噛み合わせは正しいですか? | 精度 >= 0.90 |
| テキストのレンダリング | OCR と完全一致、または judge レビュー | 必要なテキストは正確ですか? | 必須テキストの 100% |
| 地域の編集 | ペアの差分と人間の judge | 手付かずの地域はそのまま残ったのでしょうか? | 平均 >= 4/5 |
| アイデンティティとブランド | 類似性チェックと地元作物のレビュー | 文字盤、ロゴ、タイプ、製品のアイデンティティは安定していましたか? | 平均 >= 4/5 |
安全性とバイアスは画像の美しさとは別に評価されるべきです。
| リスク | テスト方法 | 結果の種類 |
|---|---|---|
| 有害なコンテンツ | prompt を実行し、フィルタリングを出力します。レッドチーム ハイリスク prompts | 合格/不合格 |
| プライバシーまたはほぼ重複した出力 | 内部資産に対して埋め込み、知覚ハッシュ、または最近傍検索を使用する | 合格/レビュー |
| 事実に基づく幻覚 | 事実に基づく主張に対して VQA スタイルのチェックを使用する | 0-1 または 0-100 |
| グループバイアス | 性別、年齢、民族、職業のみを変更する反事実的な prompts を使用する | 差分スコア |
| ブランドまたは個人の悪用 | 実在の人物、商標、ID、医療風の画像に対してより厳格な審査を適用する | 合格/不合格 |
高品質の画像が自動的に低リスク画像になるわけではありません。実践的なチーム手法は反事実テストです。prompt を一定に保ち、グループ属性のみを変更し、職業、姿勢、服装、年齢、肌の色調が体系的に変化するかどうかを確認します。
ロバストネステストマトリックス
1 つの出力設定だけをテストしないでください。 GPT Image 2 の品質は、解像度、圧縮、品質、または編集コンテキストが変更されると変更される可能性があります。
小さな行列を使用します。
| 変数 | 推奨値 |
|---|---|
| 解像度 | 1024x1024、1536x1024、2048x2048、3840x2160 (サポートされている場合) |
| 品質 | サポートされている場合は低、中、高 |
| 圧縮 | PNG、JPEG/WebP 95、85、70 |
| パイプラインのスケールアップ | オリジナル、ダウンサンプリング、ダウンサンプリングしてからアップサンプリング |
| オクルージョンとクロップ | 10%、25%、40% ランダム オクルージョン。端の作物。地元の作物 |
| 種子 | prompt ごとに少なくとも 3 候補者 |
| 入力の編集 | さまざまな入力画質レベルとトリミング領域 |
これは官僚主義ではありません。これにより、チームが 1 つの完璧な条件下でモデルを通過させた後、実際の資産パイプラインで障害が発見されることを防ぎます。
人間による評価プロトコル
人間によるレビューは、プロトコルが安定している場合にのみ決定等級となります。
このデフォルトを使用します。
- シナリオごとに少なくとも100 prompts。
- 少なくともprompt あたり 3 seeds。
- 画像ごとに少なくとも3 アノテーター。
- 5 アノテーターは、医療、プライバシーに敏感なワークフロー、法律、アイデンティティに敏感なワークフロー、またはブランドに重要なワークフローなどの高リスクのカテゴリに使用します。
- 難しいゲートの質問を Likert スコアリングから分離します。
- バージョンを比較する場合は、ブラインド A/B テストを使用します。
- 同点および不確実なオプションを許可します。
「1 = 悪い、5 = 良い」などの怠惰な評価スケールは避けてください。各点を定義します。
アライメントスケールの例:
| スコア | 定義 |
|---|---|
| UX | prompt とは完全に一致しません |
| UX | prompt とわずかにのみ一致します |
| UX | 部分的に一致しますが、重要な欠落またはエラーがあります |
| UX | ほぼ完全に一致しますが、小さな問題があります |
| UX | prompt に完全一致 |
ビジュアル品質スケールの例:
| スコア | 定義 |
|---|---|
| UX | 明らかに壊れているか使えない |
| UX | 著しく欠陥がある |
| UX | ドラフトでの使用が可能 |
| UX | 良好で使用可能である可能性が高い |
| UX | プロに近い制作品質 |
注釈ガイドでは以下も定義する必要があります。
- prompt のどのパーツがハード制約になっているか。
- 必須オブジェクトが 1 つ欠けている場合は失敗かどうか。
- 間違ったテキスト文字が 1 文字でも失敗するかどうか。
- judge の空間関係、数量、色のバインディングの方法。
- クリエイティブな追加が許可されるかどうか。
- リクエストされていない編集としてカウントされるもの。
- おおよその正確さと正確な正確さの違い。
- アノテーターが同点か不確実かを選択する場合。
これらのルールがなければ、評価はただうるさいだけではありません。再現性はありません。
サンプルサイズと統計レポート
小規模な評価はデバッグには役立ちますが、起動の決定に影響を与えるべきではありません。
実際的なルール:
- 100 promptsより少ない場合、モデルの比較は簡単に反転します。
- 95% 信頼区間がプラスまたはマイナス 5% 付近のバイナリ合格率の場合、控えめなサンプル サイズは約384サンプルです。
- 予想される合格率が 85% 程度の場合、約196のサンプルが同様の誤差範囲に達する可能性があります。
- 予想される利点が約60/40である A/B プリファレンス テストの場合、およそ200の有効な一対の比較を計画します。
- より強力な65/35設定では必要なサンプルは少なくなりますが、それでもシナリオ全体を十分にカバーする必要があります。
平均以上のレポートをする:
| 目標 | プライマリメトリクス | 推奨されるテスト | レポート |
|---|---|---|---|
| リリースゲート | テキストまたは安全性の合格率 | 正確な二項区間または 2 つの比例検定 | 合格率、95% CI、絶対差 |
| A/B の設定 | 同点を無視した勝率 | 正確な二項検定 | 勝率、95% CI、p 値 |
| ペアリングされた Likert スコア | 整合性、品質、地域性 | UX | 中央値の差、p 値、効果量 |
| 独立したLikertグループ | シナリオまたはモデル ファミリの比較 | UX | 分布の差、p 値 |
| アノテーター契約 | 序数ラベルの場合は Krippendorff's alpha | 信頼性の推定 | アルファ値 |
チームに書面による理由がない限り、alpha = 0.05(両面) を使用してください。複数の主要指標を報告する場合は、多重比較補正を適用します。アノテーターの同意の場合、Krippendorff's alpha >= 0.80は信頼できるターゲットです。0.667 ~ 0.80は暫定的なものとして扱う必要があります。
自動化と再現性
評価システムは製品コードと同様にバージョン管理する必要があります。優れたパイプラインは次のようになります。
- シナリオのスライスとリスク層を定義します。
- prompts、入力画像、masks、および参照サンプルをビルドします。
- サイズ、品質、形式、圧縮、seed 設定全体でバッチを生成します。
- テキスト、オブジェクトの存在、安全性、および編集のローカリティに対してハード ゲートを実行します。
- LPIPS、SSIM、CLIPScore、TIFA-style チェック、VQAScore-style チェック、GenEval-style チェック、VISOR-style チェックなどの自動メトリクスを実行します。
- 境界線とサンプリングされた出力を人間のレビューに送信します。
- 統計テストとアノテーターの同意チェックを実行します。
- シナリオ、障害タイプ、構成ごとに障害を表示するダッシュボードを公開します。
- 失敗事例を保存し、prompts、masks、またはワークフロー ルールの改善に使用します。
便利なツールのカテゴリ:
| ツールカテゴリ | ツールの例 | 目的 |
|---|---|---|
| 画像メトリクス | トーチメトリクス、PIQ | FID、IS、LPIPS、CLIPScore、PSNR、SSIM、DISTS、NIQE |
| 意味的評価 | TIFA、VQAScore、GenEval、VISOR-style テスト セット | オブジェクト、属性、数、空間、および prompt-faithfulness チェック |
| バージョン管理 | DVC、git、アーティファクト ストレージ | バージョン prompts、イメージ、リファレンス、メトリック、および出力 |
| UX | GitHub Actions または同等品 | 回帰テストを実行し、リリースをブロックする |
| ダッシュボード | BI ダッシュボードまたは内部レポート | 合格率、スコア分布、コスト、待ち時間、失敗例を表示します |
ダッシュボードには世界平均のみが表示されるべきではありません。少なくとも、結果を次のように分類します。
- シナリオ
- 故障の種類
- サイズ
- 品質設定
- 圧縮
- 迅速な家族
- リスク層
- モデルバージョン
操作メトリクスも追跡します。高品質の設定により遅延やコストが 2 倍になり、人間の好みがわずかしか改善されない場合、それは単なる研究結果ではなく、製品の決定です。
評価スキームの例
単純な CSV または JSON スキーマにより、評価が監査可能に保たれます。
| フィールド | 種類 | 意味 |
|---|---|---|
| run_id | string | 評価実行ID |
| prompt_id | string | 一意の prompt ID |
| scenario | string | 製品、UX、クリエイティブ、医療、または産業 |
| risk_tier | string | 低、中、または高 |
| prompt_text | string | オリジナル prompt |
| model | string | 機種名 |
| model_version | string | モデルバージョン |
| size | string | 出力サイズ |
| quality | string | 品質設定 |
| output_format | string | png、jpeg、または webp |
| output_compression | int | 圧縮値 |
| seed | int | 候補 seed または seed ポリシー ID |
| reference_id | string | ペアテストのリファレンス |
| gate_instruction | int | 0 または 1 |
| gate_text_exact | int | 0 または 1 |
| gate_safety | int | 0 または 1 |
| object_presence | float | 0 ~ 1 |
| attribute_accuracy | float | 0 ~ 1 |
| spatial_accuracy | float | 0 ~ 1 |
| locality_score | float | 0 ~ 1 |
| visual_quality | float | 0 ~ 1 |
| human_pref_win | string | 勝つか、負けるか、引き分けか |
| annotator_id | string | 人間のレビュー担当者 ID |
| rationale | string | 短い理由 |
| latency_ms | int | 生成レイテンシ |
| cost_estimate | float | 推定コスト |
| overall_verdict | string | 合格、審査、または不合格 |
最終チームチェックリスト
GPT Image 2 をワークフローの実稼働準備ができているものとして扱う前に、次のことを行ったことを確認してください。
- リリース目標を定義しました: モデルの選択、回帰、または開始ゲート。
- 定義されたシナリオのスライスとリスク層。
- 必須のオブジェクト、必須のテキスト、禁止されたコンテンツ、および編集禁止領域に対する厳密な制約を記述します。
- 通常の例、チャレンジの例、安全性またはバイアスの例を含む prompt セットを構築しました。
- prompt ごとに少なくとも 3 個の候補を生成しました。
- サポートされている場合は、少なくとも 2 つのサイズ設定と 2 つの品質設定をテストしました。
- 平均的な品質を確認する前に、テキスト、オブジェクト、セーフティ、および編集ローカリティ ゲートを実行します。
- セマンティックアライメント、オブジェクトの存在、属性バインディング、空間関係、視覚的品質を個別に測定します。
- クリエイティブの適合性、ブランドの適合性、境界線のケースについては人間によるレビューを使用しました。
- 報告された信頼区間、効果の大きさ、統計的有意性、およびアノテーターの一致。
- バージョン付きの prompts、イメージ、設定、メトリクス、judge prompts、ヒューマン コードブック、およびスクリプト。
- 出力が失敗したことだけでなく、出力が失敗した理由を示すダッシュボードを構築しました。
短いバージョン: ワークフロー ゲート、セマンティック分解、人間によるレビュー、統計規律、およびバージョン付き回帰を使用して GPT Image 2 を評価します。洗練された平均スコアに本番の失敗を隠蔽しないでください。