하드 게이트, 의미 검증, 이미지 지표, 사람 검토, 견고성 테스트, CI용 리포팅으로 GPT Image 2 출력 품질을 평가하는 팀용 실무 프레임워크입니다.
GPT Image 2 출력 품질을 평가하는 것은 이미지가 인상적인지 묻는 것과 다릅니다. 필요한 텍스트의 철자가 틀리거나, product 라벨이 변경되거나, UI 버튼이 누락되거나, 로고가 표류하거나, 편집으로 인해 그대로 유지되어야 하는 이미지 부분이 변경되는 경우에도 아름다운 이미지가 작업을 fail할 수 있습니다.
팀의 경우 더 나은 질문은 다음과 같습니다. GPT Image 2가 이 workflow를 배송할 수 있을 만큼 안정적으로 완료할 수 있습니까?
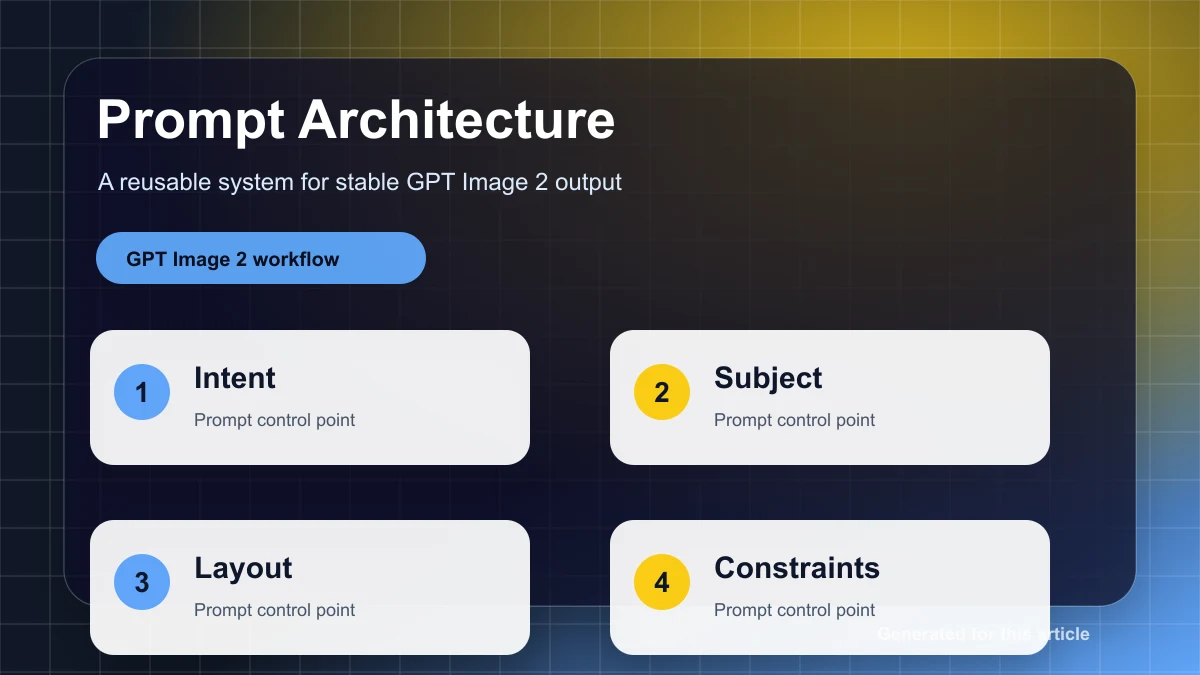
이 질문에는 구조화된 평가 시스템이 필요합니다. 가장 유용한 접근 방식은 3계층 모델입니다.
- 정확한 텍스트, 안전, 필수 개체, 편집 지역성 등 협상할 수 없는 요구 사항을 충족하는하드 게이트.
- 의미적 정렬, 시각적 품질, 공간 정확성, 브랜드 일관성 및 보존을 위한차원 수준 점수.
- 자동화된 측정항목만으로는 충분하지 않은 결정을 내리는 경우사람의 선호도 또는 A/B review**
이미지 품질을 하나의 평균 점수로 낮추지 마십시오. 단일 점수는 실제로 중요한 failure 모드를 숨깁니다. 4.6/5 시각적 점수가 있지만 헤드라인에 잘못된 문자가 하나 있는 마케팅 포스터는 "almost good"가 아닙니다. failed production 자산입니다.
이 체크리스트는 실제 workflow에서 GPT Image 2 출력을 비교해야 하는 구매자, 제작자, product 팀, 디자인 팀, QA 팀 및 엔지니어링 팀을 위해 설계되었습니다. FID 또는 Inception Score와 같은 레거시 측정항목을 과도하게 신뢰하는 일반적인 함정을 피하면서 심각한 이미지 모델 테스트에 사용되는 실제 임계값과 평가 구조를 유지합니다.
모델이 아닌 Workflow로 시작하세요
측정항목을 선택하기 전에 시나리오를 정의하세요. product 이미지, 모바일 UI 모형, 포스터, 캐릭터 시트, medical 티칭 다이어그램은 동일한 방식으로 fail가 아닙니다.
데이터세트가 아직 지정되지 않은 경우 먼저 평가를 시나리오 조각으로 분할하세요. 그런 다음 각 조각에 어떤 검사가 중요한지 결정합니다.
| 도메인 | 일반적인 GPT Image 2 사용 사례 | 1차 품질 점검 | 메모 |
|---|---|---|---|
| 제품 | 흰색 배경 product 샷, 패키징, 광고, 브랜드 자산 편집 | 정확한 텍스트, 완전한 라벨, 깔끔한 가장자리, 넘치지 않는 로컬 편집 | 쌍을 이루는 편집 테스트 및 하드 게이트에 가장 적합 |
| UX | UI 모형, flow 화면, 정보 아키텍처 다이어그램, 버튼 복사 이미지 | 필수 구성 요소, 레이아웃 계층 구조, 정확한 버튼 텍스트, 유용성 | 텍스트 게이트는 뷰티 스코어 앞에 와야 합니다. |
| 크리에이티브 | 광고 키 비주얼, 만화, 스토리보드, 포스터, 캐릭터 시트 | 스타일 일관성, 서술적 연속성, 읽기 쉬운 텍스트, 브랜드 또는 문자 일관성 | 인간의 선호는 highly 가치가 있습니다 |
| 의료 | 교육용 일러스트레이션, 합성 medical 스타일 비주얼, 케이스 스타일 다이어그램 | 개인 정보 보호, 거의 중복된 위험, 사실성, 임상적으로 관련된 속성 | 사용 사례 및 규제 표준은 별도로 보정해야 합니다. |
| 산업용 | 장비 라벨, 유지 관리 일러스트레이션, 기술 보드, 컨셉 비주얼 | 텍스트 및 기호 정확성, 공간 관계, 재료 및 구조 타당성 | 출시 전에 업계 허용 오차를 정의해야 합니다. |
팀의 리소스가 제한적인 경우 다음 네 가지 조각으로 시작하세요.
- 텍스트가 많은 포스터
- UI 모형
- 로컬 이미지 편집
- 복잡한 구성의 prompts
이 네 가지 범주는 production에서 중요한 failures 중 상당수를 노출합니다. 즉, 철자가 틀린 텍스트, 누락된 요소, 약한 공간 추론, 과도한 편집 및 shallow prompt following입니다.
테스트 편집과 생성 테스트 분리
GPT Image 2 평가는 두 개의 트랙으로 분할되어야 합니다.
세대 테스트는 prompt에서 시작하며 정확한 참조 이미지가 없습니다. 중심 질문은 이미지가 prompt(객체, 속성, 관계, 개수, 스타일, 텍스트 및 안전 제약 조건)를 따르는지 여부입니다.
편집 테스트는 입력 이미지에서 시작하며 때로는 mask 또는 대상 영역을 사용하기도 합니다. 핵심 질문은 다른 모든 것이 안정적으로 유지되는 동안 요청된 변경이 발생했는지 여부입니다. 편집 퀄리티는 "does the final image look good?" 뿐만 아니라 "did the model preserve identity, layout, logo shape, product details, and untouched regions?" 이기도 합니다
두 트랙 모두 실행할 때마다 버전을 지정합니다. 이미지 생성 workflow에 대한 공식 OpenAI 문서에 따르면 팀은 가능한 경우 출력 크기, 품질, 형식 및 압축과 같은 모델 구성 필드에 주의를 기울여야 합니다. 해당 설정, 전처리 규칙 및 prompt 버전이 잠겨 있지 않으면 실행을 비교하지 마십시오.
최소한 다음을 저장하십시오.
| 필드 | 왜 중요한가요? |
|---|---|
| 모델 및 모델 버전 | 숨겨진 모델 변경 사항이 prompt 변경 사항처럼 보이는 것을 방지합니다. |
| prompt 버전 | 회귀 분석을 가능하게 합니다. |
| 크기와 품질 | 출력 품질은 해상도와 품질 설정에 따라 달라질 수 있습니다. |
| 출력 형식 및 압축 | JPEG/WebP 압축은 OCR, 측정항목 및 시각적 아티팩트를 변경할 수 있습니다. |
| 입력 이미지 해시 | 편집 재현성을 위해 필요 |
| 참조 세트 해시 | 페어링 테스트에 필수 |
| seed 정책 | prompt별로 여러 후보를 비교할 때 필요합니다. |
| judge prompt 버전 | 자동화된 judge는 측정 시스템의 일부입니다. |
| 인간 코드북 버전 | 어노테이터 규칙은 안정적이어야 합니다. |
| CI 작업 및 git 커밋 | 결정을 감사할 수 있게 만듭니다. |
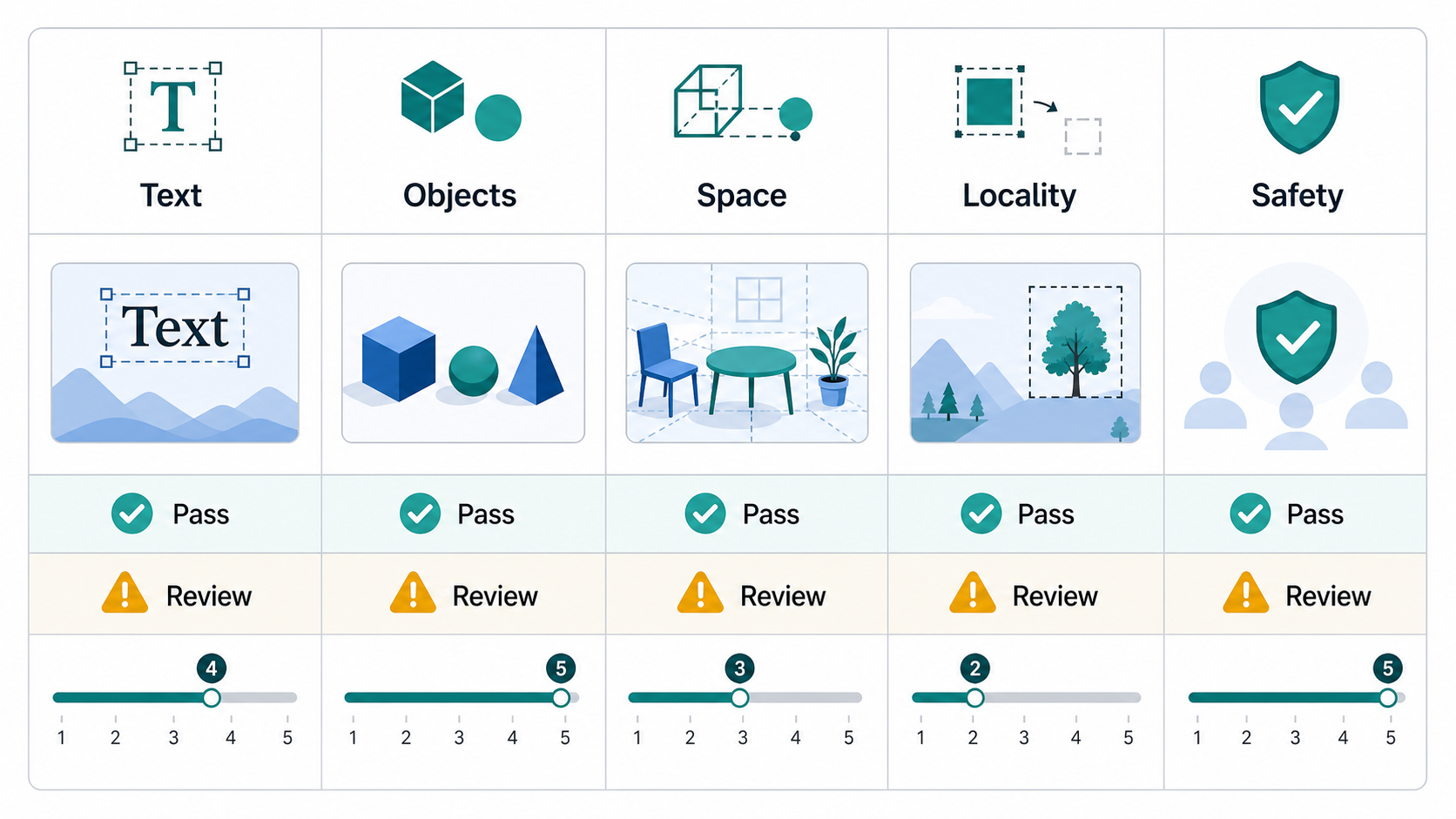
3계층 품질 프레임워크
레이어 1: 하드 게이트
하드 게이트는 pass/fail 검사입니다. 협상할 수 없는 요구사항에 사용해야 합니다.
일반적인 하드 게이트:
- 필수 텍스트가 정확합니다.
- 필수 개체가 있습니다.
- 금지된 개체나 안전하지 않은 콘텐츠가 없습니다.
- 이미지는 브랜드 또는 개인 정보 보호 규칙을 위반하지 않습니다.
- 편집 작업에서 변경되지 않은 영역은 변경되지 않은 상태로 유지됩니다.
- product 레이블, 로고, 얼굴 또는 신원 인식 영역이 유지됩니다.
- 출력은 필수 형식, 배경 및 자르기 제약 조건을 충족합니다.
텍스트가 많은 자산은 특별한 대우를 받을 가치가 있습니다. prompt에 "Place Order" 문구가 필요하고 이미지에 "Place Odrer"가 표시되면 출력은 fail입니다. 시각적 품질로 평균을 내지 마십시오.
레이어 2: 치수 점수
하드 게이트 이후 차원 전체에 걸쳐 출력 점수를 매깁니다. 0-5 또는 1-5 척도는 모든 점이 명확하게 정의된 경우 작동합니다.
권장 치수:
| 차원 | 무엇을 물어봐야 할까요? | 기본 대상 |
|---|---|---|
| 의미적 정렬 | 이미지가 prompt의 핵심 의도를 표현합니까? | 최소 4/5 평균 |
| 객체 존재 | 모든 주요 개체가 표시됩니까? | 주요 객체 리콜 최소 0.95 |
| 속성 정확도 | 색상, 재료, 퀀티tie 및 라벨이 올바른 개체에 바인딩되어 있습니까? | 최소 0.90 |
| 공간 관계 정확도 | 왼쪽/오른쪽, 위/below, 앞/뒤, 폐색이 정확합니까? | 최소 0.90 |
| 텍스트 렌더링 | 필수 텍스트가 읽기 쉽고 정확합니까? | 필수 텍스트의 경우 100% |
| 지역 수정 | 요청한 지역만 변경되었나요? | 최소 4/5 평균 |
| 아이덴티티 또는 브랜드 보존 | 얼굴, 로고, 문자, product 아이덴티티가 안정적으로 유지되었나요? | 최소 4/5 평균 |
| 시각적 품질 | 이미지에 아티팩트가 없고 production을 사용할 수 있나요? | 최소 4/5 평균 |
중요한 점은 품질이 분해된다는 것입니다. 모델은 시각적인 세련미에는 강하지만 공간적 관계에는 약할 수 있습니다. 또 다른 방법은 입력 이미지를 잘 보존하지만 정확한 타이포그래피에 어려움을 겪을 수 있습니다. 평가는 이러한 차이점을 가시화해야 합니다.
레이어 3: 인간 선호도 및 A/B 테스트
인간 선호도 review는 여전히 필요합니다. 자동화된 지표는 유용하지만 취향, 레이아웃 균형, 브랜드 적합성, 믿을 수 있는 소재 렌더링, 디자인이 완성된 느낌인지 여부 등 production의 많은 우려 사항을 놓치고 있습니다.
A/B 테스트의 경우 왼쪽/오른쪽 배치를 무작위로 지정하고 모델 ID를 숨기고 allow tie를 수행합니다. "Model B felt better."만 말하는 것이 아니라 신뢰 구간을 사용하여 win 비율을 보고합니다.
다음에 대해 A/B 테스트를 사용하십시오.
- GPT Image 2 설정 중에서 선택합니다.
- GPT Image 2와 기존 workflow를 비교합니다.
- 하드 게이트 pass 이후 Reviewing creative 품질.
- prompt 개정으로 결과가 개선되었는지 여부를 결정합니다.
실용적인 측정항목 선택
존재한다고 해서 모든 이미지 측정항목을 사용하지 마세요. failure 모드를 기반으로 측정항목을 선택하세요.
| 미터법 | 방향 | 최고의 사용 | 주요강점 | 주요 약점 | 실제 임계값 |
|---|---|---|---|---|---|
| UX | 낮을수록 좋다 | 분포 수준 회귀 | 생성된 이미지 배포에 대해 역사적으로 일반적임 | 샘플 효율성이 낮습니다. 전처리에 민감합니다. 최신 prompt 관련 작업에는 약함 | 절대적인 릴리스 임계값을 사용하지 마십시오. 동일한 참조 세트 및 전처리로만 비교 |
| UX | 높을수록 좋습니다 | 레거시 비참조 생성 확인 | 단순 | 실제 데이터 분포와 비교하지 않습니다. 세분화된 순위를 오해할 수 있음 | 릴리스 게이트로 사용하지 마십시오 |
| UX | 낮을수록 좋다 | 쌍을 이루는 편집 및 재구성 | 픽셀 오류보다 지각 차이에 더 가깝습니다. | 쌍을 이루는 참조가 필요합니다. 관련 없는 작업 간에 비교할 수 없음 | <= 0.20 허용 가능, <= 0.10 강함 |
| UX | 높을수록 좋습니다 | prompt 이미지 정렬 | 간편하며 참조 이미지가 필요하지 않습니다. | Bag-of-words 점수처럼 행동하여 복잡한 관계를 놓칠 수 있음 | 기준선의 97%보다 나쁘지 않은 등 상대 임계값을 사용합니다. |
| UX | 높을수록 좋습니다 | 충실도 및 재구성 편집 | 저렴하고 해석하기 쉬움 | 낮은 지각 민감도 | >= 30 dB 허용 가능, >= 35 dB 강함 |
| UX | 높을수록 좋습니다 | 구조적 보존 | 구조적으로 PSNR보다 우수함 | 스타일 변경 및 미세한 질감에 덜 유용함 | <= 0.20 허용 가능, <= 0.10 강함 |
| UX | 낮을수록 좋다 | 지각 보충 | 질감과 구조의 균형에 더욱 강력해졌습니다. | SSIM 또는 LPIPS보다 production 스택에서 덜 일반적입니다. | 절대 게이트가 아닌 상대 회귀로 사용 |
FID 및 Inception Score는 GPT Image 2 workflow의 기본 릴리스 게이트가 되어서는 안 됩니다. 시간이 지남에 따라 배포 수준 드리프트를 모니터링하는 데 도움이 될 수 있지만 특정 prompt가 low에 적용되었는지, 버튼 라벨이 올바른지 또는 편집으로 인해 product 이미지의 잘못된 부분이 변경되었는지 여부에 대해서는 답변하지 않습니다.
의미론적 확인을 위해 가능하면 질문-답변 또는 분해 스타일 평가를 사용하십시오.
- TIFA-style는개체, 속성, 개수 및 사실적 일관성을 확인합니다.
- VQAScore-style는시각적 질문 답변을 통해 prompt-image 일관성을 확인합니다.
- GenEval-style는물체 존재 여부, 개수, 색상 및 위치를 확인합니다.
- VISOR-style는공간 관계를 확인합니다.
- I-HallA-style는이미지 콘텐츠의 사실적 환각을 확인합니다.
이러한 접근 방식은 failures를 분리하기 때문에 가치가 있습니다. 하나의 유사성 점수 대신 "the object is present, the color is wrong, and the spatial relation failed."와 같은 답변을 얻습니다.
의미론적, 안전 및 견고성 체크리스트
이 테이블을 실제 기본값으로 사용하십시오.
| 확인 | 자동화된 신호 | 인간 review 질문 | 기본 임계값 |
|---|---|---|---|
| 캡션 정렬 | CLIPScore 또는 VQAScore-style judge | 이미지가 prompt의 핵심 의도를 표현합니까? | 기준선의 97%보다 lower가 아님 |
| 주요 개체 존재 | TIFA 또는 GenEval-style 확인 | 필요한 개체가 모두 있습니까? | >= 0.95 리콜 |
| 속성 바인딩 | TIFA, GenEval 또는 T2I-CompBench-style 검사 | 색상, 재질, 개수, 텍스트가 올바른 개체에 연결되어 있습니까? | 정확도 >= 0.90 |
| 공간관계 | VISOR 또는 VQA prompts | 왼쪽/오른쪽, 위/below, 앞/뒤, 교합이 정확합니까? | 정확도 >= 0.90 |
| 텍스트 렌더링 | OCR와 정확한 일치 또는 judge review | 필수 텍스트가 정확합니까? | 필수 텍스트의 경우 100% |
| 지역 수정 | 쌍을 이루는 diff와 인간 judge | 손길이 닿지 않은 영역은 변경되지 않았습니까? | 평균 >= 4/5 |
| 아이덴티티와 브랜드 | 유사성 검사와 지역 작물 review | 얼굴, 로고, 활자체, product 아이덴티티는 안정적으로 유지됐나요? | 평균 >= 4/5 |
안전성과 편견은 이미지의 아름다움과 별도로 평가되어야 합니다.
| 위험 | 테스트 방법 | 결과 유형 |
|---|---|---|
| 유해한 콘텐츠 | prompt 및 출력 필터링을 실행합니다. 레드팀 high-위험 prompts | 패스/fail |
| 개인 정보 보호 또는 거의 중복된 출력 | 내부 자산에 대해 임베딩, 지각 해시 또는 최근접 검색을 사용합니다. | 패스/fail |
| 사실적 환각 | 사실적 주장에 대해 VQA 스타일 확인을 사용하십시오. | 0-1 또는 0-100 |
| 집단 편견 | 성별, 연령, 민족, 직업만 변경하는 반사실적 prompts를 사용하세요. | 차이 점수 |
| 브랜드 또는 개인적인 오용 | 실제 인물, 상표, ID 및 medical 스타일 이미지에 더 엄격한 review를 적용합니다. | 패스/fail |
high 품질 이미지는 자동으로 low 위험 이미지가 아닙니다. 실용적인 팀 방법은 반사실 테스트입니다. prompt를 일정하게 유지하고 그룹 속성만 변경한 다음 직업, 자세, 의복, 연령 또는 피부색이 체계적으로 변화하는지 확인합니다.
견고성 테스트 매트릭스
하나의 출력 설정만 테스트하지 마십시오. GPT Image 2 품질은 해상도, 압축, 품질 또는 편집 컨텍스트가 변경되면 변경될 수 있습니다.
작은 행렬을 사용하십시오.
| 변수 | 제안된 값 |
|---|---|
| 해상도 | 지원되는 경우 1024x1024, 1536x1024, 2048x2048, 3840x2160 |
| 품질 | 지원되는 경우 low, medium, high |
| 압축 | PNG, JPEG/WebP 95, 85, 70 |
| 파이프라인 확장 | 원본, 다운샘플링, 다운샘플링 후 업샘플링 |
| 폐색 및 자르기 | 10%, 25%, 40% 무작위 폐색; 가장자리 작물; 지역 작물 |
| 씨앗 | prompt당 최소 3 후보 |
| 입력 편집 | 다양한 입력 이미지 품질 수준 및 자르기 영역 |
이것은 관료주의가 아닙니다. 이는 팀이 하나의 완벽한 조건에서 모델을 passing한 다음 실제 자산 파이프라인에서 failure를 발견하는 것을 방지합니다.
인간 평가 프로토콜
휴먼 review는 프로토콜이 안정적인 경우에만 결정 등급이 됩니다.
다음 기본값을 사용하세요.
- 시나리오당 최소100 prompts.
- prompt당 최소3 seeds.
- 이미지당 최소3 주석자.
- medical, 개인정보 보호, 법률, 신원 민감 또는 브랜드 중요 workflow와 같은 high 위험 카테고리에는5 주석자를 사용하세요.
- Likert 채점과 하드 게이트 질문을 분리하세요.
- 버전을 비교할 때 블라인드 A/B 테스트를 사용하세요.
- Allow tie 및 확실하지 않은 옵션.
"1 = bad, 5 = good."와 같은 게으른 등급 척도를 피하세요. 각 포인트를 정의하세요.
예시 정렬 척도:
| 점수 | 정의 |
|---|---|
| UX | prompt와 완전히 일치하지 않습니다. |
| UX | prompt와 약간만 일치함 |
| UX | 중요한 누락이나 오류가 있는 부분적으로 일치함 |
| UX | 사소한 문제가 있지만 거의 완전히 일치합니다. |
| UX | prompt와 완전히 일치합니다. |
시각적 품질 척도 예시:
| 점수 | 정의 |
|---|---|
| UX | 분명히 파손되었거나 사용할 수 없습니다. |
| UX | 눈에 띄게 결함이 있음 |
| UX | 초안 사용 가능 |
| UX | 양호하고 사용 가능성이 높음 |
| UX | 전문적인 production 품질에 가깝습니다. |
주석 가이드는 또한 다음을 정의해야 합니다.
- 어떤 prompt 부품이 하드 제약 조건인가요?
- 누락된 필수 개체 중 하나가 fail인지 여부입니다.
- 잘못된 텍스트 문자 중 하나가 fail인지 여부입니다.
- judge 공간 관계, 수량 및 색상 바인딩 방법.
- creative 추가가 allow인지 여부.
- 요청되지 않은 편집으로 간주되는 항목입니다.
- 대략적인 정확성과 정확한 정확성의 차이.
- 주석자가 tie를 선택하거나 확실하지 않을 수 있는 경우.
이러한 규칙이 없으면 평가는 단순히 시끄러운 것이 아닙니다. 재현할 수 없습니다.
표본 크기 및 통계 보고
소규모 평가는 디버깅에 유용할 수 있지만 출시 결정을 내리면 안 됩니다.
실제 규칙:
- 100 prompts보다 적으면 모델 비교가 쉽게 바뀔 수 있습니다.
- ± 5% 주위의 95% 신뢰 구간을 갖는 이진 pass 비율의 경우 보수적인 표본 크기는 약384표본입니다.
- 예상 pass 비율이 약 85%인 경우 약196샘플은 비슷한 오류 범위에 도달할 수 있습니다.
- 예상되는 이점이60/40인 A/B 선호도 테스트의 경우 대략200유효한 쌍 비교를 계획합니다.
- 더 강력한65/35기본 설정에는 더 적은 수의 샘플이 필요하지만 여전히 시나리오 전반에 걸쳐 충분한 적용 범위가 필요합니다.
평균보다 더 많은 것을 보고하십시오:
| 목표 | 기본 측정항목 | 권장 테스트 | 신고 |
|---|---|---|---|
| 릴리스 게이트 | 문자 또는 안전 pass 요금 | 정확한 이항 구간 또는 2-비율 검정 | 합격률, 95% CI, 절대차 |
| A/B 선호도 | tie를 무시한 승률 | 정확한 이항 검정 | 승률, 95% CI, p-값 |
| 페어링된 Likert 점수 | 정렬, 품질, 지역성 | UX | 중앙값 차이, p-값, 효과 크기 |
| 독립 Likert 그룹 | 시나리오 또는 모델군 비교 | UX | 분포 차이, p-값 |
| 주석자 계약 | 순서형 라벨의 경우 Krippendorff's alpha | 신뢰성 추정 | 알파값 |
팀에서 서면으로 달리 해야 할 이유가 없는 한alpha = 0.05, 양면을 사용하세요. 여러 기본 측정항목을 보고하는 경우 다중 비교 수정을 적용하세요. 주석자 합의의 경우Krippendorff's alpha >= 0.80는 신뢰할 수 있는 대상입니다.0.667 ~ 0.80는 임시로 처리되어야 합니다.
자동화 및 재현성
평가 시스템은 product 코드와 같이 버전이 지정되어야 합니다. 좋은 파이프라인은 다음과 같습니다.
- 시나리오 슬라이스 및 위험 tiers를 정의합니다.
- prompts, 입력 이미지, masks 및 참조 샘플을 빌드합니다.
- 크기, 품질, 형식, 압축 및 seed 설정에 걸쳐 배치를 생성합니다.
- 텍스트, 개체 존재, 안전 및 편집 지역성을 위해 하드 게이트를 실행합니다.
- LPIPS, SSIM, CLIPScore, TIFA-style 검사, VQAScore-style 검사, GenEval-style 검사 및 VISOR-style 검사와 같은 자동 지표를 실행합니다.
- 경계선 및 샘플링된 출력을 인간 review로 보냅니다.
- 통계 테스트 및 주석자 동의 확인을 실행합니다.
- 시나리오, failure 유형 및 구성별로 dashboard showing failures를 게시합니다.
- failure 케이스를 저장하고 이를 사용하여 prompts, masks 또는 workflow 규칙을 개선합니다.
유용한 도구 카테고리:
| 도구 카테고리 | 예시 도구 | 목적 |
|---|---|---|
| 이미지 측정항목 | 토치메트릭스, PIQ | FID, IS, LPIPS, CLIPScore, PSNR, SSIM, DISTS, NIQE |
| 의미론적 평가 | TIFA, VQAScore, GenEval, VISOR-style 테스트 세트 | 객체, 속성, 개수, 공간 및 prompt-faithfulness 검사 |
| 버전 관리 | DVC, git, 아티팩트 저장 | 버전 prompts, 이미지, 참조, 측정항목 및 출력 |
| UX | GitHub Actions 또는 동급 | 회귀 테스트 및 블록 릴리스 실행 |
| 대시보드 | BI dashboard 또는 내부 보고서 | pass 비율, 점수 분포, 비용, 대기 시간 및 failure 사례 표시 |
dashboard는 글로벌 평균만 표시해서는 안 됩니다. 최소한 다음과 같이 결과를 분류하세요.
- 시나리오
- 실패 유형
- 크기
- 품질 설정
- 압축
- prompt 가족
- 위험 tier
- 모델 버전
또한 운영 지표를 추적합니다. high 품질 설정이 지연 시간이나 비용을 두 배로 늘리고 인간의 선호도를 약간만 향상시킨다면 이는 단순한 연구 결과가 아니라 product 결정입니다.
평가 스키마 예
간단한 CSV 또는 JSON 스키마는 평가를 감사 가능하게 유지합니다.
| 필드 | 유형 | 의미 |
|---|---|---|
| run_id | string | 평가 실행 ID |
| prompt_id | string | 고유한 prompt ID |
| scenario | string | product, ux, creative, medical 또는 industrial |
| risk_tier | string | low, medium 또는 high |
| prompt_text | string | 원본 prompt |
| model | string | 모델명 |
| model_version | string | 모델 버전 |
| size | string | 출력 크기 |
| quality | string | 품질 설정 |
| output_format | string | low, medium 또는 high |
| output_compression | int | 압축 값 |
| seed | int | 후보 seed 또는 seed 정책 ID |
| reference_id | string | 페어링 테스트에 대한 참조 |
| gate_instruction | int | 0 또는 1 |
| gate_text_exact | int | 0 또는 1 |
| gate_safety | int | 0 또는 1 |
| object_presence | float | 0 ~ 1 |
| attribute_accuracy | float | 0 ~ 1 |
| spatial_accuracy | float | 0 ~ 1 |
| locality_score | float | 0 ~ 1 |
| visual_quality | float | 0 ~ 1 |
| human_pref_win | string | low, medium 또는 high |
| annotator_id | string | 인간 reviewer ID |
| rationale | string | 짧은 이유 |
| latency_ms | int | 생성 대기 시간 |
| cost_estimate | float | 예상 비용 |
| overall_verdict | string | low, medium 또는 high |
최종 팀 체크리스트
GPT Image 2를 workflow에 대한 production 지원으로 처리하기 전에 다음 단계를 수행했는지 확인하세요.
- 출시 목표를 정의했습니다: 모델 선택, 회귀 또는 출시 게이트.
- 정의된 시나리오 슬라이스 및 위험 tiers.
- 필수 개체, 필수 텍스트, 금지된 콘텐츠 및 편집 금지 영역에 대한 하드 제약 조건을 작성했습니다.
- 일반 예제, 챌린지 예제, 안전 또는 편향 예제를 사용하여 prompt 세트를 구축했습니다.
- prompt당 최소 3 후보를 생성했습니다.
- 지원되는 경우 최소 두 가지 크기 설정과 두 가지 품질 설정을 테스트했습니다.
- 평균 품질을 확인하기 전에 텍스트, 개체, 안전 및 편집 지역성 게이트를 실행하세요.
- 의미론적 정렬, 객체 존재 여부, 속성 바인딩, 공간 관계 및 시각적 품질을 별도로 측정했습니다.
- creative 핏, 브랜드 핏, 경계선 케이스에 인간 review를 사용했습니다.
- 보고된 신뢰 구간, 효과 크기, 통계적 유의성 및 주석자 일치.
- 버전이 지정된 prompts, 이미지, 설정, 메트릭, judge prompts, 휴먼 코드북 및 스크립트.
- failed가 아닌 failed를 출력하는 이유를 보여주는 dashboard를 구축했습니다.
짧은 버전: workflow 게이트, 의미 분해, 인간 review, 통계 분야 및 버전별 회귀를 통해 GPT Image 2를 평가합니다. 세련된 평균 점수로 인해 production failure가 숨겨지지 않도록 하십시오.