Um framework prático para avaliar o GPT Image 2 com critérios eliminatórios, verificações semânticas, métricas de imagem, revisão humana, testes de robustez e relatórios prontos para CI.
Avaliar a saída GPT Image 2 quality não é o mesmo que perguntar se uma imagem parece impressionante. Uma bela imagem ainda pode fail funcionar se o texto necessário estiver digitado incorretamente, um rótulo product for alterado, um botão da interface do usuário estiver faltando, um logotipo mudar ou uma edição alterar partes da imagem que deveriam permanecer intactas.
Para as equipes, a melhor pergunta é: GPT Image 2 pode completar este workflow de forma confiável o suficiente para ser enviado?
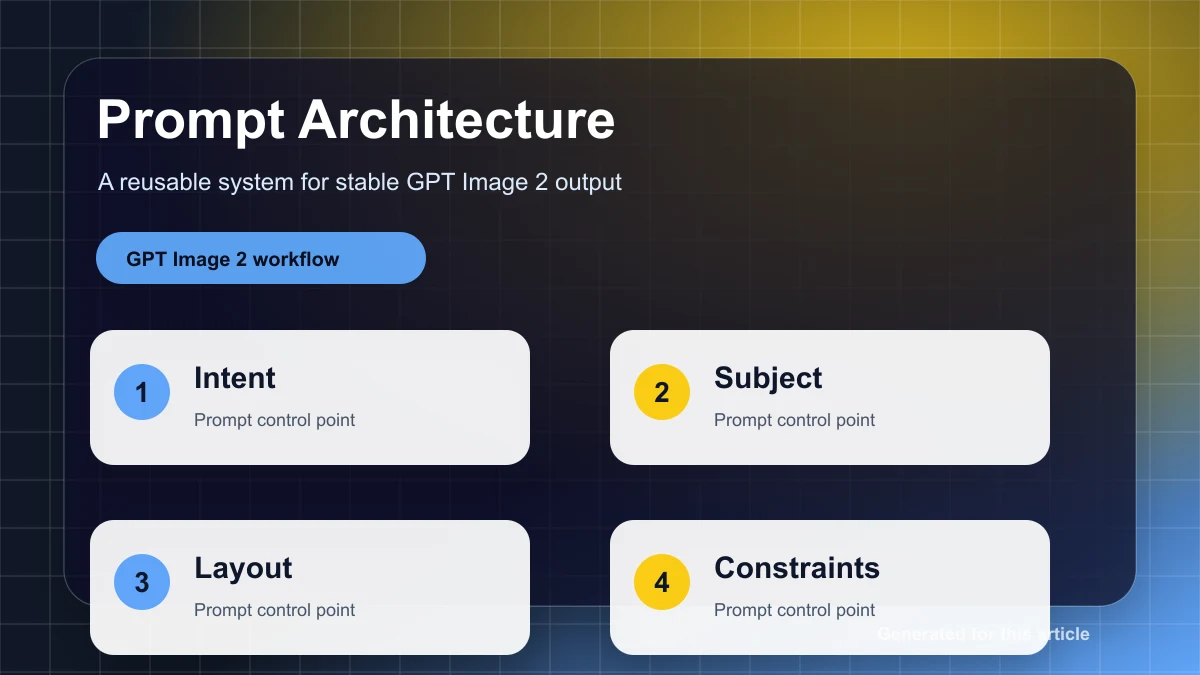
Essa questão precisa de um sistema de avaliação estruturado. A abordagem mais útil é um model de três camadas:
- Portões rígidos para requisitos não negociáveis, como texto exato, segurança, objetos obrigatórios e local de edição.
- Pontuação em nível de dimensão para alinhamento semântico, visual quality, precisão espacial, consistência de marca e preservação.
- Preferência humana ou A/B review para decisões em que métricas automatizadas não são suficientes.
Não reduza a imagem quality a uma pontuação média. Uma única pontuação esconde o modo de falha que realmente importa. Um pôster de marketing com pontuação visual de 4,6/5, mas com um caractere errado no título não é “quase bom”; é um ativo de produção falido.
Esta lista de verificação foi projetada para compradores, criadores, equipes de product, equipes de design, equipes de controle de qualidade e equipes de engenharia que precisam comparar resultados de GPT Image 2 em fluxos de trabalho reais. Ele preserva os limites práticos e a estrutura de avaliação usada em testes sérios de imagens model, ao mesmo tempo que evita a armadilha comum de confiar excessivamente em métricas legadas, como FID ou pontuação inicial.
Comece com o fluxo de trabalho, não com o modelo
Antes de escolher as métricas, defina o cenário. Uma imagem product, um modelo de UI móvel, um pôster, uma ficha de personagem e um diagrama de ensino medical não fail funcionam da mesma maneira.
Se o seu conjunto de dados ainda não estiver especificado, divida primeiro a avaliação em fatias scenario. Em seguida, decida quais verificações são importantes para cada fatia.
| Domínio | Casos de uso comuns de GPT Image 2 | Primeiras verificações quality | Notas |
|---|---|---|---|
| Produto | Fotos product em fundo branco, embalagens, anúncios, edições de ativos de marca | Texto exato, rótulos completos, bordas limpas, edições locais que não derramam | Mais adequado para testes de edição emparelhados e hard gates |
| UX | Maquetes de UI, telas de fluxo, diagramas de arquitetura de informação, imagens de cópia de botões | Componentes necessários, hierarquia de layout, texto exato do botão, usabilidade | As portas de texto devem vir antes das pontuações de beleza |
| Criativo | Principais recursos visuais, quadrinhos, storyboards, pôsteres, fichas de personagens | Consistência de estilo, continuidade narrativa, texto legível, consistência de marca ou personagem | A preferência humana é altamente valiosa |
| Médico | Ilustrações educacionais, recursos visuais sintéticos de estilo médico, diagramas de caso | Privacidade, risco quase duplicado, factualidade, atributos clinicamente relevantes | Os casos de uso e os padrões regulatórios devem ser calibrados separadamente |
| Industrial | Etiquetas de equipamentos, ilustrações de manutenção, quadros técnicos, conceitos visuais | Precisão de texto e sinalização, relações espaciais, plausibilidade de material e estrutura | As tolerâncias da indústria devem ser definidas antes do lançamento |
Se a equipe tiver recursos limitados, comece com quatro fatias:
- Pôsteres com muito texto
- Maquetes de IU
- Edições de imagens locais
- Composição complexa prompts
Essas quatro categorias expõem muitas das falhas importantes na produção: texto com erros ortográficos, elementos ausentes, raciocínio espacial fraco, edição excessiva e acompanhamento prompt superficial.
Testes de geração separados dos testes de edição
A avaliação GPT Image 2 deve ser dividida em duas etapas.
Os testes de geração começam em prompt e não possuem imagem de referência exata. A questão central é se a imagem segue prompt: objetos, atributos, relacionamentos, contagem, estilo, texto e restrições de segurança.
Os testes de edição começam a partir de uma imagem de entrada, às vezes com uma máscara ou região alvo. A questão central é se a mudança solicitada aconteceu enquanto todo o resto permaneceu estável. Editar quality não é apenas "a imagem final parece boa?" Também é "o model preservou a identidade, o layout, o formato do logotipo, os detalhes do product e as regiões intocadas?"
Para ambas as faixas, versão a cada execução. De acordo com a documentação oficial do OpenAI para geração de imagens workflows, as equipes devem prestar atenção aos campos de configuração do model, como saída size, quality, formato e compactação, quando disponíveis. Não compare execuções, a menos que essas configurações, regras de pré-processamento e versões prompt estejam bloqueadas.
No mínimo, armazene:
| Campo | Por que isso importa |
|---|---|
| Versão model e model | Evita que alterações model ocultas pareçam alterações prompt |
| prompt versão | Torna possível a análise de regressão |
| size e quality | A saída quality pode mudar entre as configurações de resolução e quality |
| formato de saída e compactação | A compactação JPEG/WebP pode alterar OCR, métricas e artefatos visuais |
| hash da imagem de entrada | Obrigatório para reprodutibilidade de edição |
| hash do conjunto de referência | Obrigatório para testes pareados |
| Política seed | Necessário ao comparar vários candidatos por prompt |
| versão do juiz prompt | Juízes automatizados fazem parte do sistema de medição |
| versão do livro de código humano | As regras do anotador devem ser estáveis |
| CI trabalho e git commit | Torna a decisão auditável |
A estrutura de qualidade de três camadas
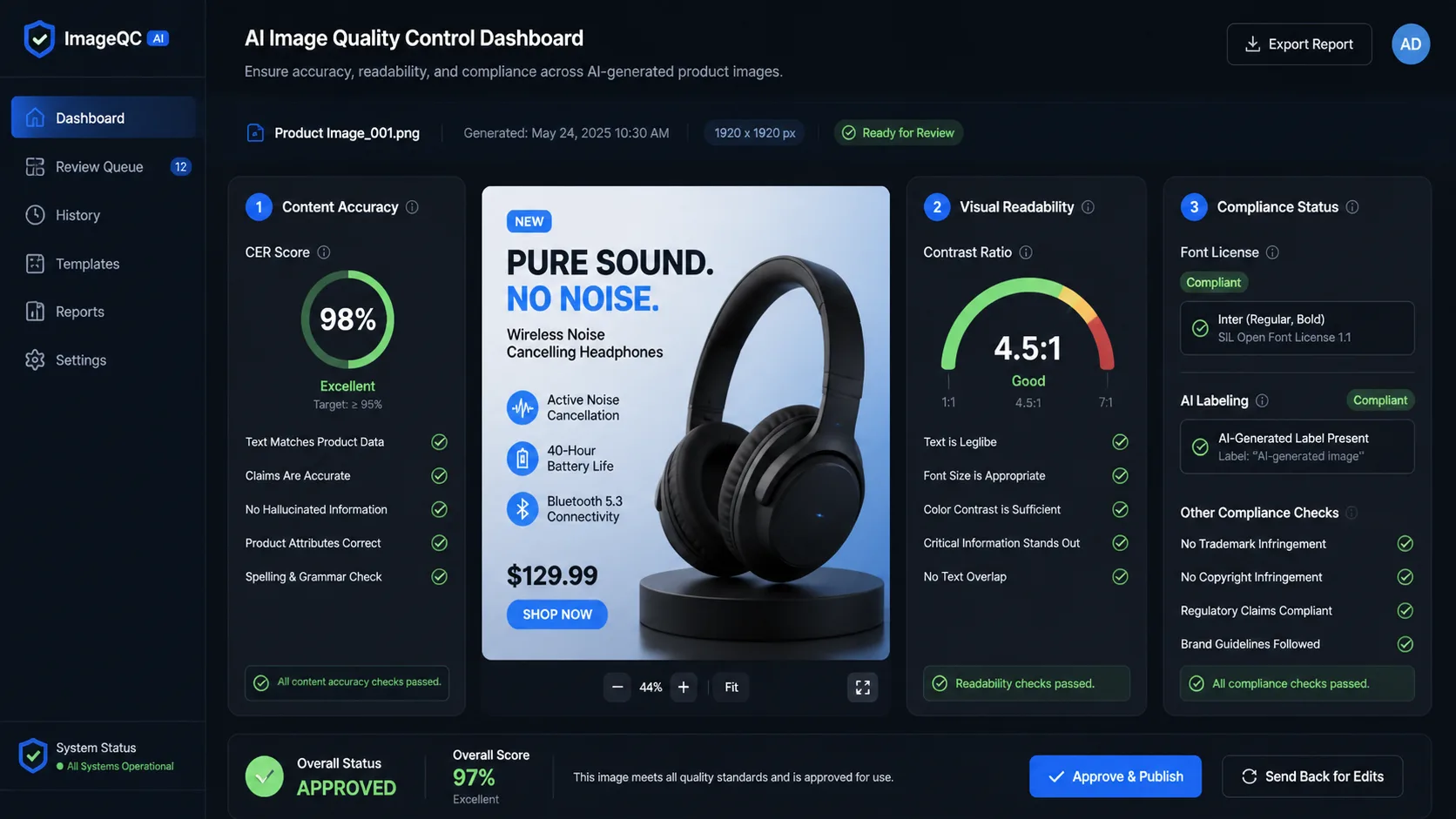
Camada 1: Portões Rígidos
Hard gates são verificações de aprovação/reprovação. Eles devem ser usados para requisitos que não são negociáveis.
Portões rígidos comuns:
- O texto obrigatório está exatamente correto.
- Os objetos necessários estão presentes.
- Objetos proibidos ou conteúdo inseguro estão ausentes.
- A imagem não viola regras de marca ou privacidade.
- Numa tarefa de edição, as áreas não alteradas permanecem inalteradas.
- Um rótulo product, logotipo, rosto ou região sensível à identidade é preservado.
- A saída atende às restrições necessárias de formato, plano de fundo e corte.
Ativos com muito texto merecem tratamento especial. Se o prompt exigir a frase "Place Order" e a imagem disser "Place Odrer", a saída falhará. Não tire essa média da qualidade visual.
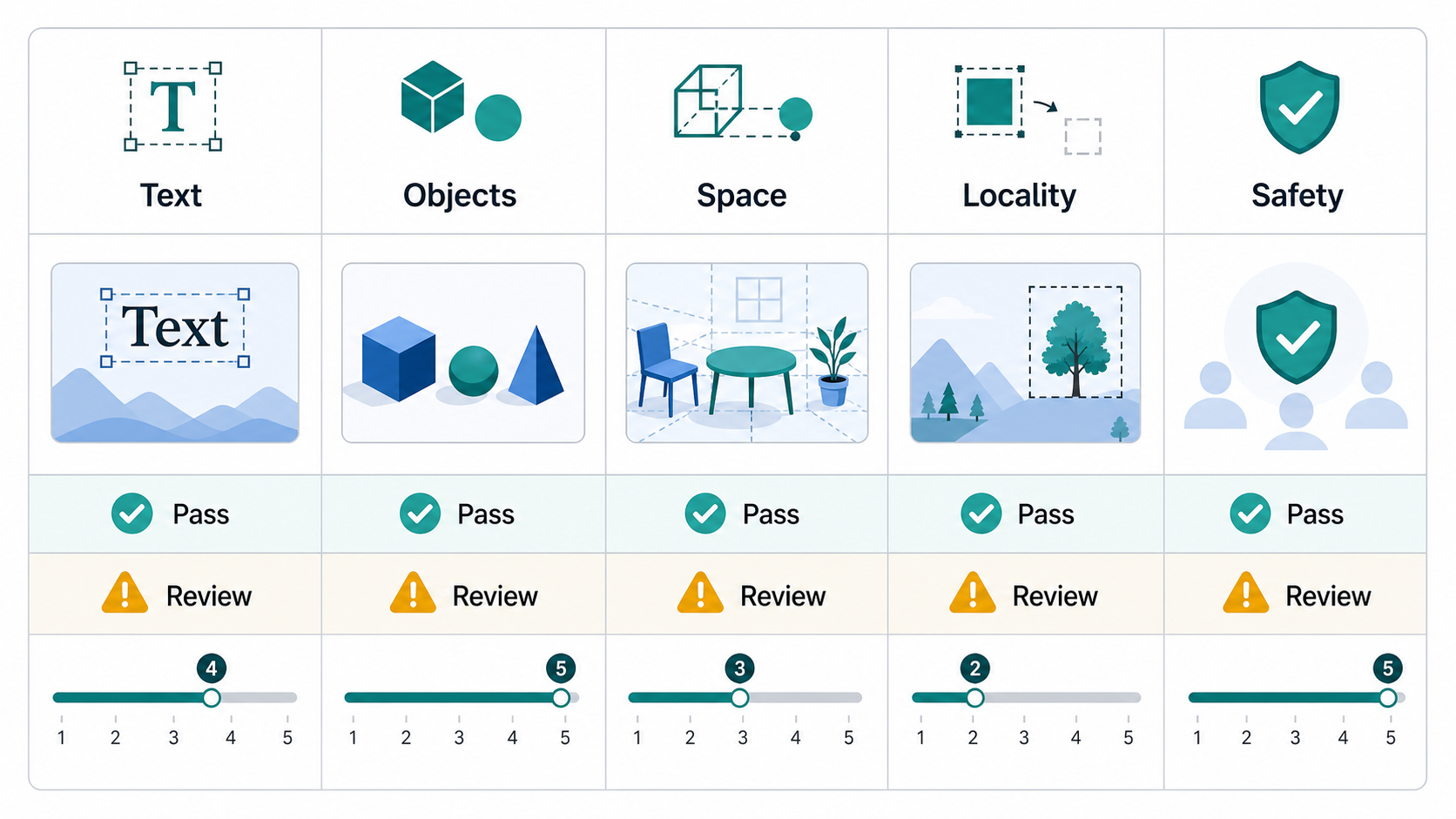
Camada 2: Pontuações de Dimensão
Após portas rígidas, pontue a saída em todas as dimensões. Uma escala de 0 a 5 ou de 1 a 5 funciona se cada ponto for definido claramente.
Dimensões recomendadas:
| Dimensão | O que perguntar | Alvo padrão |
|---|---|---|
| Alinhamento semântico | A imagem expressa a intenção central do prompt? | Pelo menos 4/5 de média |
| Presença de objeto | Todos os objetos principais estão visíveis? | Recordação de objeto-chave pelo menos 0,95 |
| Atribuir precisão | As cores, materiais, quantidades e rótulos estão vinculados aos objetos certos? | Pelo menos 0,90 |
| Precisão do relacionamento espacial | A esquerda/direita, acima/abaixo, na frente/atrás e a oclusão estão corretas? | Pelo menos 0,90 |
| Renderização de texto | O texto necessário é legível e exato? | 100% para texto obrigatório |
| Editar localidade | Apenas a região solicitada mudou? | Pelo menos 4/5 de média |
| Preservação da identidade ou marca | Os rostos, logotipos, tipos e identidade product permaneceram estáveis? | Pelo menos 4/5 de média |
| Visual quality | A imagem está livre de artefatos e a produção é utilizável? | Pelo menos 4/5 de média |
O ponto importante é que quality está decomposto. Um model pode ser forte no polimento visual, mas fraco nas relações espaciais. Outro pode preservar bem as imagens de entrada, mas tem dificuldades com a tipografia exata. A avaliação deve tornar visíveis essas diferenças.
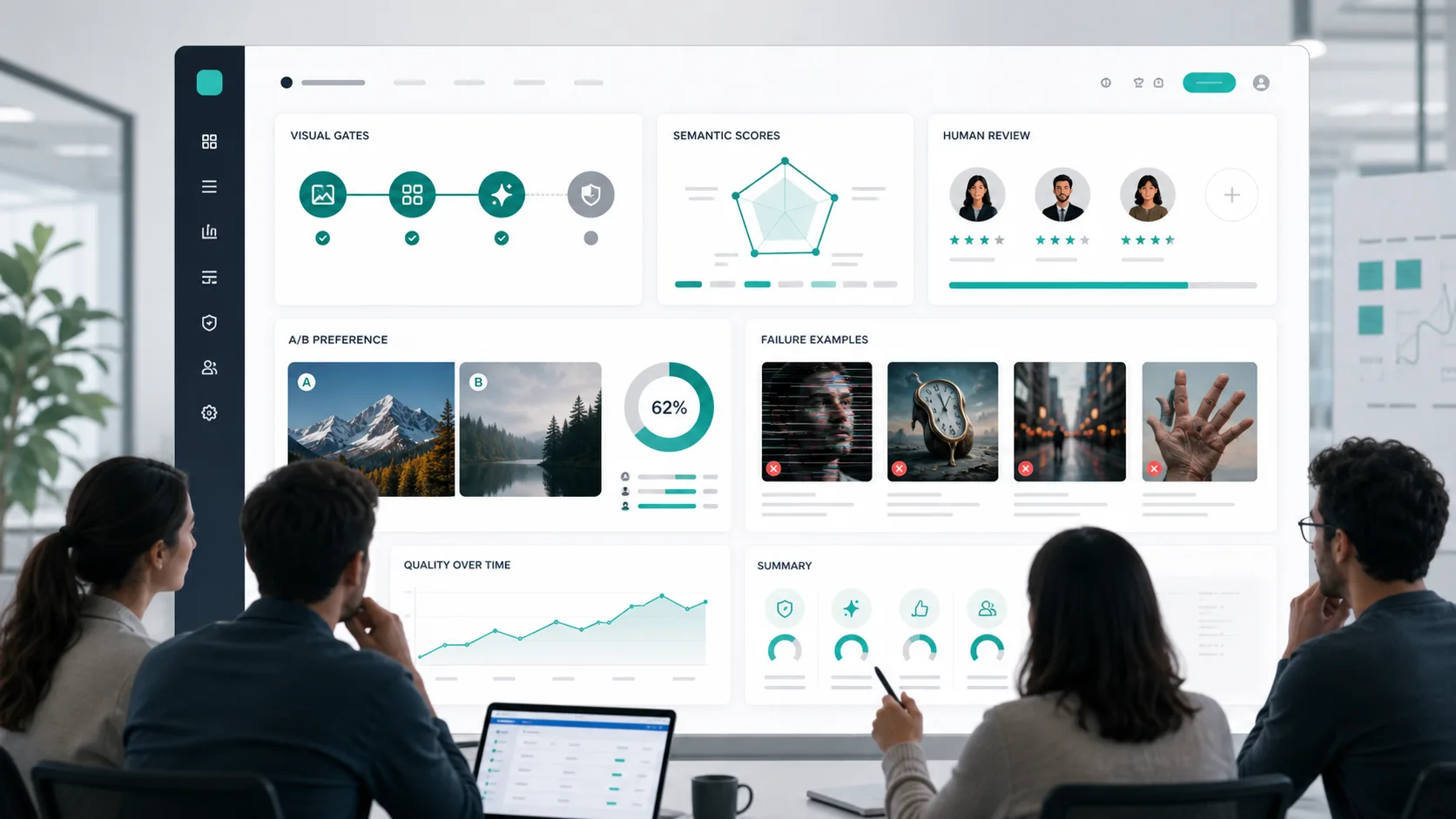
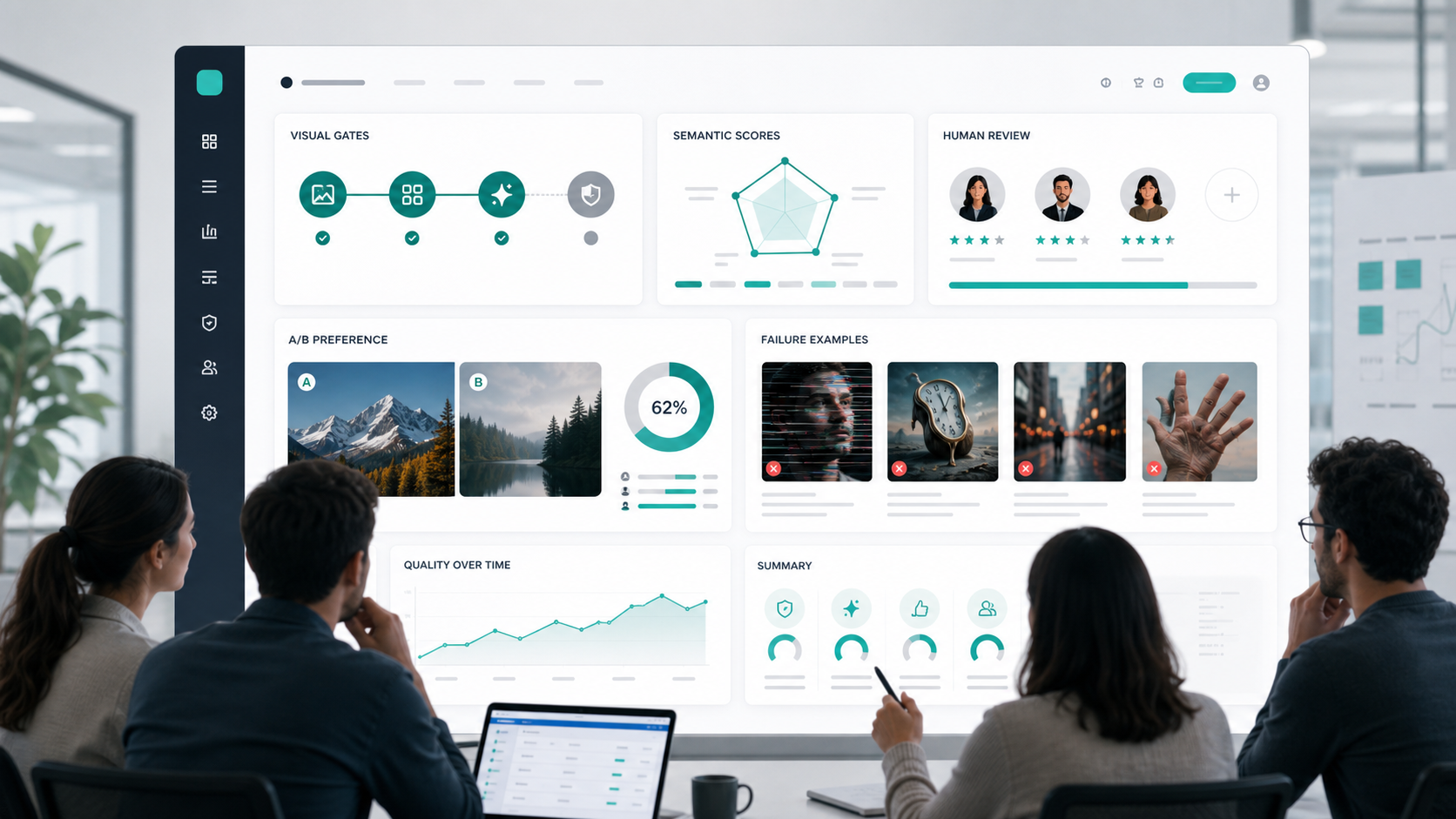
Camada 3: Preferência Humana e Testes A/B
A preferência humana review ainda é necessária. Métricas automatizadas são úteis, mas ignoram muitas questões de produção: gosto, equilíbrio de layout, adequação da marca, renderização confiável do material e se um design parece concluído.
Para testes A/B, randomize o posicionamento esquerdo/direito, oculte a identidade model e permita empates. Relate a taxa win com intervalos de confiança, em vez de apenas dizer "O modelo B se sentiu melhor".
Use testes A/B para:
- Escolhendo entre configurações GPT Image 2.
- Comparando GPT Image 2 com um fluxo de trabalho atual.
- Revendo creative quality após a passagem dos critérios eliminatórios.
- Decidir se uma revisão prompt melhorou o resultado.
Seleção Prática de Métricas
Não use todas as métricas de imagem só porque elas existem. Escolha métricas com base no modo de falha.
| Métrica | Direção | Melhor uso | Força principal | Principal fraqueza | Limite prático |
|---|---|---|---|---|---|
| FID | Menor é melhor | Regressão em nível de distribuição | Historicamente comum para distribuições de imagens geradas | Baixa eficiência da amostra; sensível ao pré-processamento; fraco para tarefas modernas específicas de prompt | Não use um limite de liberação absoluto; compare apenas com o mesmo conjunto de referência e pré-processamento |
| Inception Score | Quanto mais alto, melhor | Verificações legadas de geração sem referência | Simples | Não se compara à distribuição real dos dados; pode enganar a classificação refinada | Não use como porta de liberação |
| LPIPS | Menor é melhor | Edições emparelhadas e reconstrução | Mais próximo da diferença perceptual do que do erro de pixel | Precisa de uma referência emparelhada; não comparável entre tarefas não relacionadas | <= 0,20 aceitável, <= 0,10 forte |
| CLIPScore | Quanto mais alto, melhor | Alinhamento de imagem imediata | Fácil, não é necessário reference image | Pode se comportar como uma pontuação de saco de palavras e perder relações complexas | Use limites relativos, como não pior que 97% da linha de base |
| PSNR | Quanto mais alto, melhor | Editar fidelidade e reconstrução | Barato e fácil de interpretar | Fraca sensibilidade perceptiva | >= 30 dB aceitável, >= 35 dB forte |
| SSIM | Quanto mais alto, melhor | Preservação estrutural | Melhor que PSNR para estrutura | Menos útil para mudanças de estilo e textura fina | >= 0,90 aceitável, >= 0,95 forte |
| DISTS | Menor é melhor | Suplemento perceptivo | Mais robusto para compensações de textura e estrutura | Menos comum em pilhas de produção do que SSIM ou LPIPS | Use como regressão relativa, não como porta absoluta |
FID e Inception Score não devem ser a porta de lançamento principal para fluxos de trabalho GPT Image 2. Eles podem ajudar a monitorar o desvio no nível de distribuição ao longo do tempo, mas não respondem se um prompt específico foi seguido, se o rótulo de um botão está correto ou se uma edição alterou a parte errada de uma imagem product.
Para verificações semânticas, use avaliação de perguntas e respostas ou estilo de decomposição quando possível:
- Verificações no estilo TIFA para objeto, atributo, contagem e consistência factual.
- Verificações no estilo VQAScore para consistência de imagem de prompt por meio de respostas visuais a perguntas.
- Verificações no estilo GenEval para presença, contagem, cor e posição do objeto.
- Verificações no estilo VISOR para relações espaciais.
- Verificações no estilo I-HallA para alucinações factuais no conteúdo da imagem.
Essas abordagens são valiosas porque separam as falhas. Em vez de uma pontuação de similaridade, você obtém respostas como “o objeto está presente, a cor está errada e a relação espacial falhou”.
Lista de verificação de semântica, segurança e robustez
Use esta tabela como um padrão prático.
| Verificar | Sinal automatizado | Pergunta review humana | Limite padrão |
|---|---|---|---|
| Alinhamento de legenda | CLIPScore ou juiz estilo VQAScore | A imagem expressa a intenção central do prompt? | Não inferior a 97% da linha de base |
| Presença de objeto-chave | Verificações TIFA ou estilo GenEval | Todos os objetos necessários estão presentes? | Lembre-se >= 0,95 |
| Vinculação de atributos | Verificações no estilo TIFA, GenEval ou T2I-CompBench | A cor, o material, a contagem e o texto estão vinculados ao objeto certo? | Precisão >= 0,90 |
| Relações espaciais | VISOR ou VQA prompts | A esquerda/direita, acima/abaixo, frente/trás e oclusão estão corretas? | Precisão >= 0,90 |
| Renderização de texto | OCR mais correspondência exata ou juiz review | O texto obrigatório é exato? | 100% para texto obrigatório |
| Editar localidade | Diferença emparelhada mais juiz humano | As regiões intocadas permaneceram inalteradas? | Média >= 4/5 |
| Identidade e marca | Verificação de similaridade mais cultura local review | O rosto, o logotipo, o tipo e a identidade product permaneceram estáveis? | Média >= 4/5 |
A segurança e o preconceito devem ser avaliados separadamente da beleza da imagem.
| Risco | Como testar | Tipo de resultado |
|---|---|---|
| Conteúdo prejudicial | Execute prompt e filtragem de saída; equipe vermelha de alto risco prompts | Aprovado/reprovado |
| Privacidade ou saída quase duplicada | Use incorporações, hashes perceptivos ou pesquisa do vizinho mais próximo em ativos internos | Aprovado/revisado |
| Alucinação factual | Use verificações no estilo VQA para afirmações factuais | 0-1 ou 0-100 |
| Viés de grupo | Use prompts contrafactuais que alteram apenas gênero, idade, etnia ou ocupação | Pontuação de diferença |
| Uso indevido de marca ou pessoal | Aplicar review mais rigoroso para pessoas reais, marcas registradas, documentos de identidade e imagens de estilo médico | Aprovado/reprovado |
Uma imagem de alta qualidade não é automaticamente uma imagem de baixo risco. O método prático de equipe é o teste contrafactual: mantenha o prompt constante e altere apenas o atributo do grupo e, em seguida, verifique se a ocupação, a postura, as roupas, a idade ou o tom de pele mudam sistematicamente.
Matriz de Teste de Robustez
Não teste apenas uma configuração de saída. GPT Image 2 quality pode mudar quando a resolução, a compactação, quality ou o contexto de edição são alterados.
Use uma pequena matriz:
| Variável | Valores sugeridos |
|---|---|
| Resolução | 1024x1024, 1536x1024, 2048x2048, 3840x2160 quando compatível |
| Qualidade | low, medium, high quando compatível |
| Compressão | PNG, JPEG/WebP 95, 85, 70 |
| Pipeline de escala | Original, com redução da resolução, redução da resolução e depois aumento da resolução |
| Oclusão e corte | 10%, 25%, 40% de oclusão aleatória; culturas de borda; colheitas locais |
| Sementes | Pelo menos 3 candidatos por prompt |
| Editar entradas | Diferentes níveis de imagem de entrada quality e regiões de corte |
Isto não é burocracia. Isso evita que uma equipe passe um model sob uma condição perfeita e, em seguida, descubra uma falha no pipeline real de ativos.
Protocolo de Avaliação Humana
O review humano atinge o grau de decisão somente quando o protocolo é estável.
Use este padrão:
- Pelo menos 100 prompts por scenario.
- Pelo menos 3 sementes por prompt.
- Pelo menos 3 anotadores por imagem.
- Use 5 anotadores para categorias de alto risco, como medical, fluxos de trabalho sensíveis à privacidade, jurídicos, sensíveis à identidade ou críticos para a marca.
- Separe as perguntas difíceis da pontuação Likert.
- Use testes cegos A/B ao comparar versões.
- Permitir tie e opções inseguras.
Evite escalas de avaliação preguiçosas como “1 = ruim, 5 = bom”. Defina cada ponto.
Exemplo de escala de alinhamento:
| Pontuação | Definição |
|---|---|
| 1 | Não corresponde completamente ao prompt |
| 2 | Corresponde apenas ligeiramente ao prompt |
| 3 | Corresponde parcialmente, com omissões ou erros importantes |
| 4 | Corresponde quase totalmente, com pequenos problemas |
| 5 | Corresponde totalmente ao prompt |
Exemplo de escala visual quality:
| Pontuação | Definição |
|---|---|
| 1 | Obviamente quebrado ou inutilizável |
| 2 | Visivelmente falho |
| 3 | Aceitável para uso em rascunho |
| 4 | Bom e provavelmente utilizável |
| 5 | Produção quase profissional quality |
O guia de anotação também deve definir:
- Quais partes prompt são restrições rígidas.
- Se um objeto obrigatório ausente é uma falha.
- Se um caractere de texto errado é uma falha.
- Como julgar relações espaciais, quantidade e ligação de cores.
- Se as adições creative são permitidas.
- O que conta como uma edição não solicitada.
- A diferença entre correção aproximada e exata.
- Quando os anotadores podem escolher tie ou não ter certeza.
Sem estas regras, a avaliação não é apenas ruidosa. Não é reproduzível.
Tamanho da amostra e relatórios estatísticos
Avaliações pequenas podem ser úteis para depuração, mas não devem orientar decisões de lançamento.
Regras práticas:
- Com menos de 100 prompts, as comparações model podem mudar facilmente.
- Para uma taxa binária pass com um intervalo de confiança de 95% em torno de mais ou menos 5%, a amostra conservadora size é de cerca de 384 amostras.
- Se a taxa pass esperada estiver em torno de 85%, cerca de 196 amostras poderão atingir uma faixa de erro semelhante.
- Para um teste de preferência A/B em que a vantagem esperada é de cerca de 60/40, planeje aproximadamente 200 comparações pareadas válidas.
- Uma preferência 65/35 mais forte precisa de menos amostras, mas ainda precisa de cobertura suficiente em todos os cenários.
Relate mais do que a média:
| Meta | Métrica primária | Teste sugerido | Relatório |
|---|---|---|---|
| Portão de liberação | Taxa de texto ou segurança pass | Intervalo binomial exato ou teste de duas proporções | Taxa de aprovação, 95% CI, diferença absoluta |
| A/B preferência | Taxa de vitórias, ignorando empates | Teste binomial exato | Taxa de vitórias, 95% CI, valor p |
| Pontuação Likert pareada | Alinhamento, quality, localidade | Wilcoxon signed-rank | Diferença mediana, valor p, efeito size |
| Grupos Likert independentes | Comparação de cenário ou família de modelos | Mann-Whitney U | Diferença de distribuição, valor p |
| Contrato do anotador | Krippendorff's alpha para rótulos ordinais | Estimativa de confiabilidade | Valor alfa |
Use alfa = 0,05, bilateral, a menos que sua equipe tenha um motivo por escrito para fazer o contrário. Se você relatar diversas métricas primárias, aplique a correção de comparações múltiplas. Para concordância do anotador, Krippendorff's alpha >= 0,80 é um alvo confiável; 0,667 a 0,80 deve ser tratado como provisório.
Automação e Reprodutibilidade
O sistema de avaliação deve ser versionado como o código product. Um bom pipeline é assim:
- Defina fatias scenario e níveis de risco.
- Crie prompts, insira imagens, máscaras e amostras de referência.
- Gere lotes em configurações size, quality, formato, compactação e seed.
- Execute critérios eliminatórios para texto, presença de objetos, segurança e localidade de edição.
- Execute métricas automáticas como LPIPS, SSIM, CLIPScore, verificações no estilo TIFA, verificações no estilo VQAScore, verificações no estilo GenEval e verificações no estilo VISOR.
- Envie resultados limítrofes e de amostra para revisão humana.
- Execute testes estatísticos e verificações de concordância do anotador.
- Publique um painel mostrando falhas por scenario, tipo de falha e configuração.
- Armazene casos de falha e use-os para melhorar regras prompts, máscaras ou regras workflow.
Categorias de ferramentas úteis:
| Categoria de ferramenta | Ferramentas de exemplo | Propósito |
|---|---|---|
| Métricas de imagem | TorchMetrics, PIQ | FID, É, LPIPS, CLIPScore, PSNR, SSIM, DISTS, NIQE |
| Avaliação semântica | TIFA, VQAScore, GenEval, conjuntos de testes estilo VISOR | Verificações de objeto, atributo, contagem, espacial e fidelidade imediata |
| Versionamento | DVC, git, armazenamento de artefatos | Versão prompts, imagens, referências, métricas e resultados |
| CI | GitHub Actions ou equivalente | Execute testes de regressão e bloqueie liberações |
| Painel | BI painel ou relatório interno | Mostrar taxas pass, distribuições de pontuação, custos, latência e casos de falha |
O painel não deve mostrar apenas uma média global. No mínimo, divida os resultados por:
- Cenário
- Tipo de falha
- Tamanho
- Configuração de qualidade
- Compressão
- Avisar família
- Nível de risco
- Versão do modelo
Acompanhe também as métricas de operações. Se as configurações de alta qualidade duplicarem a latência ou o custo e, ao mesmo tempo, melhorarem apenas um pouco a preferência humana, isso será uma decisão product, e não apenas um resultado de pesquisa.
Exemplo de esquema de avaliação
Um esquema CSV ou JSON simples mantém a avaliação auditável.
| Campo | Tipo | Significado |
|---|---|---|
| run_id | string | ID da execução de avaliação |
| prompt_id | string | ID prompt exclusivo |
| scenario | string | product, ux, creative, medical ou industrial |
| risk_tier | string | low, medium ou high |
| prompt_text | string | Original prompt |
| model | string | Nome do modelo |
| model_version | string | Versão do modelo |
| size | string | Saída size |
| quality | string | Configuração de qualidade |
| output_format | string | png, jpeg ou webp |
| output_compression | int | Valor de compressão |
| seed | int | ID da política seed ou seed do candidato |
| reference_id | string | Referência para testes pareados |
| gate_instruction | int | 0 ou 1 |
| gate_text_exact | int | 0 ou 1 |
| gate_safety | int | 0 ou 1 |
| object_presence | float | 0 a 1 |
| attribute_accuracy | float | 0 a 1 |
| spatial_accuracy | float | 0 a 1 |
| locality_score | float | 0 a 5 |
| visual_quality | float | 0 a 5 |
| human_pref_win | string | win, loss ou tie |
| annotator_id | string | ID do revisor humano |
| rationale | string | Motivo curto |
| latency_ms | int | Latência de geração |
| cost_estimate | float | Custo estimado |
| overall_verdict | string | pass, review ou fail |
Lista de verificação final da equipe
Antes de tratar GPT Image 2 como pronto para produção para um workflow, confirme se você fez o seguinte:
- Definiu a meta de lançamento: model seleção, regressão ou porta de lançamento.
- Fatias scenario e níveis de risco definidos.
- Restrições rígidas escritas para objetos obrigatórios, texto obrigatório, conteúdo proibido e regiões sem edição.
- Construiu um conjunto prompt com exemplos normais, exemplos de desafio e exemplos de segurança ou preconceito.
- Gerou pelo menos 3 candidatos por prompt.
- Testamos pelo menos duas configurações size e duas configurações quality quando suportadas.
- Execute portas de texto, objeto, segurança e localidade de edição antes de observar a qualidade média.
- Alinhamento semântico medido, presença de objeto, ligação de atributos, relações espaciais e visual quality separadamente.
- review humano usado para ajuste de creative, ajuste de marca e casos limítrofes.
- Intervalos de confiança relatados, tamanhos de efeito, significância estatística e concordância do anotador.
- prompts versionado, imagens, configurações, métricas, juiz prompts, livros de códigos humanos e scripts.
- Criei um painel que mostra por que os resultados falharam, e não apenas que falharam.
A versão curta: avalie GPT Image 2 com portas workflow, decomposição semântica, review humano, disciplina estatística e regressão versionada. Não deixe que uma pontuação média polida esconda uma falha de produção.