GPT Image 2’yi zorunlu kontroller, anlamsal denetimler, görsel metrikler, insan incelemesi, dayanıklılık testleri ve CI’ye hazır raporlamayla değerlendirmek için pratik bir çerçeve.
GPT Image 2 çıktısını quality değerlendirmek, bir görüntünün etkileyici görünüp görünmediğini sormakla aynı şey değildir. Gerekli metin yanlış yazılmışsa, bir product etiketi değiştirilmişse, bir kullanıcı arayüzü düğmesi eksikse, bir logo kayarsa veya bir düzenleme görüntünün dokunulmaması gereken kısımlarını değiştirirse, güzel bir görüntü yine de fail işi yapabilir.
Ekipler için daha iyi soru şudur: GPT Image 2 bu workflow işlemini gönderilmeye yetecek kadar güvenilir bir şekilde tamamlayabilir mi?
Bu sorunun yapılandırılmış bir değerlendirme sistemine ihtiyacı var. En kullanışlı yaklaşım üç katmanlı model'dır:
- Tam metin, güvenlik, gerekli nesneler ve düzenleme konumu gibi tartışılamaz gereksinimler için zorunlu kontroller.
- Anlamsal hizalama, görsel quality, mekansal doğruluk, marka tutarlılığı ve koruma için boyut düzeyinde puanlama.
- Otomatik ölçümlerin yeterli olmadığı kararlar için İnsan tercihi veya A/B review.
quality görselini tek bir ortalama puana düşürmeyin. Tek bir puan, gerçekten önemli olan arıza modunu gizler. 4,6/5 görsel puana sahip ancak başlığında tek bir yanlış karakter bulunan bir pazarlama posteri "neredeyse iyi" değildir; başarısız bir üretim varlığıdır.
Bu kontrol listesi, gerçek iş akışlarında GPT Image 2 çıktılarını karşılaştırması gereken alıcılar, yaratıcılar, product ekipleri, tasarım ekipleri, QA ekipleri ve mühendislik ekipleri için tasarlanmıştır. Ciddi görüntü model testlerinde kullanılan pratik eşikleri ve değerlendirme yapısını korurken FID veya Başlangıç Puanı gibi eski metriklere aşırı güvenmenin yaygın tuzağından kaçınır.
Modelle Değil İş Akışıyla Başlayın
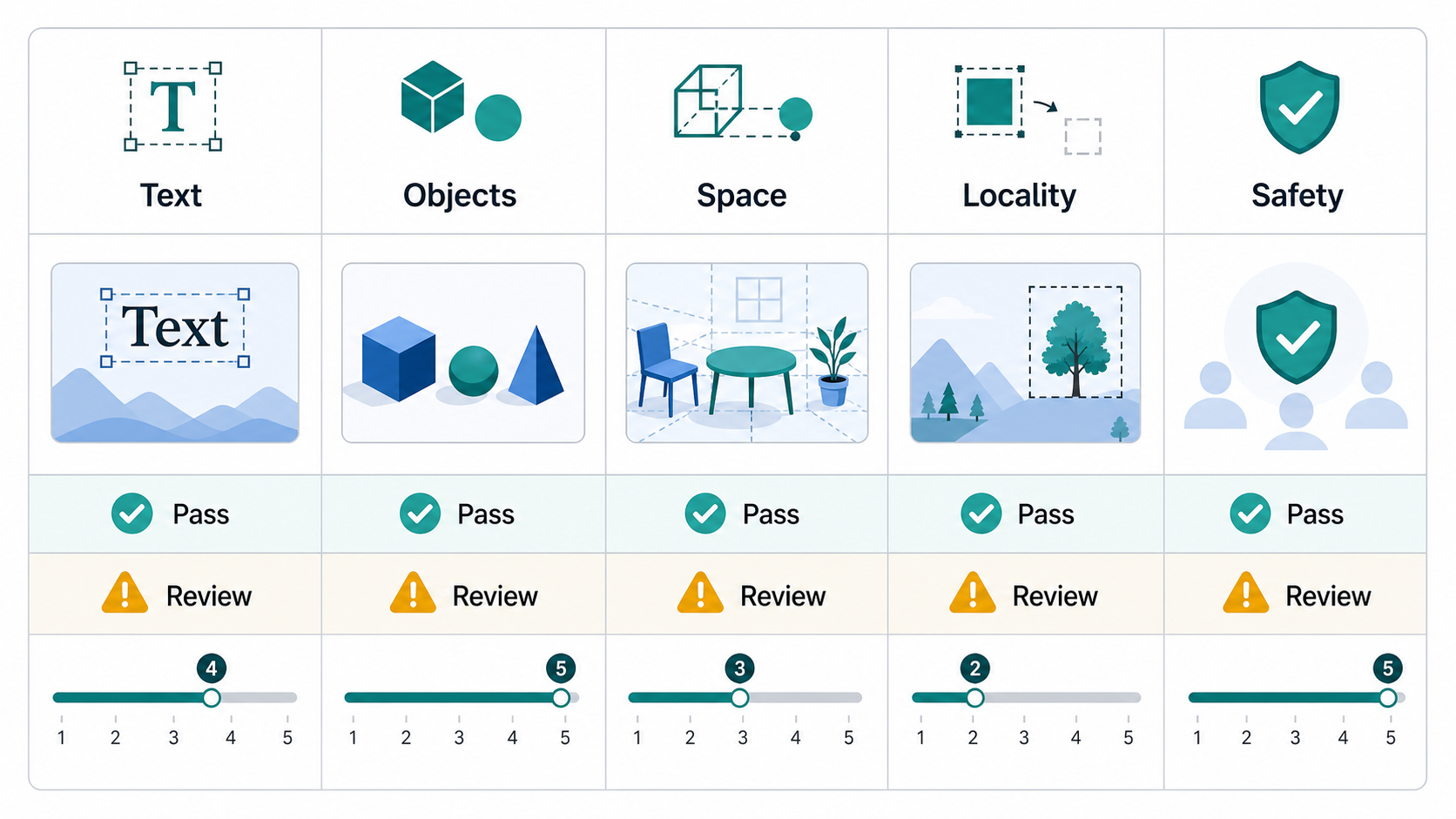
Metrikleri seçmeden önce senaryoyu tanımlayın. Bir product resmi, bir mobil kullanıcı arayüzü maketi, bir poster, bir karakter sayfası ve bir medical öğretim diyagramı fail ile aynı şekilde değildir.
Veri kümeniz henüz belirtilmediyse öncelikle değerlendirmeyi scenario dilimlerine bölün. Daha sonra her dilim için hangi kontrollerin önemli olduğuna karar verin.
| İhtisas | Yaygın GPT Image 2 kullanım durumları | İlk quality kontrolü | Notlar |
|---|---|---|---|
| Ürün | Beyaz arka planlı product çekimler, paketleme, reklamlar, marka varlığı düzenlemeleri | Tam metin, eksiksiz etiketler, temiz kenarlar, dökülmeyen yerel düzenlemeler | Eşleştirilmiş düzenleme testleri ve sabit kapılar için en uygunudur |
| UX | Kullanıcı arayüzü maketleri, akış ekranları, bilgi mimarisi diyagramları, düğme kopyalı görüntüler | Gerekli bileşenler, düzen hiyerarşisi, tam düğme metni, kullanılabilirlik | Metin kapıları güzellik puanlarından önce gelmelidir |
| Yaratıcı | Reklam anahtar görselleri, çizgi romanlar, storyboard'lar, posterler, karakter sayfaları | Stil tutarlılığı, anlatı sürekliliği, okunabilir metin, marka veya karakter tutarlılığı | İnsan tercihi son derece değerlidir |
| Tıbbi | Eğitici illüstrasyonlar, sentetik tıbbi tarzda görseller, vaka tarzı diyagramlar | Gizlilik, neredeyse kopya risk, gerçekçilik, klinik olarak ilgili özellikler | Kullanım senaryosu ve düzenleyici standartlar ayrı ayrı kalibre edilmelidir |
| Endüstriyel | Ekipman etiketleri, bakım illüstrasyonları, teknik panolar, konsept görselleri | Metin ve işaret doğruluğu, mekansal ilişkiler, malzeme ve yapı uygunluğu | Endüstri toleransları piyasaya sürülmeden önce tanımlanmalıdır |
Takımın kaynakları sınırlıysa dört dilimle başlayın:
- Metin ağırlıklı posterler
- Kullanıcı arayüzü maketleri
- Yerel resim düzenlemeleri
- Karmaşık bileşimsel prompts
Bu dört kategori, üretimde önemli olan birçok başarısızlığı açığa çıkarır: yanlış yazılmış metin, eksik öğeler, zayıf uzamsal akıl yürütme, aşırı düzenleme ve yüzeysel prompt takibi.
Oluşturma Testlerini Testleri Düzenlemekten Ayırın
GPT Image 2 değerlendirmesi iki parçaya bölünmelidir.
Nesil testleri bir prompt ile başlar ve kesin bir referans resmi yoktur. Temel soru, görüntünün prompt: nesneler, nitelikler, ilişkiler, sayım, stil, metin ve güvenlik kısıtlamalarına uyup uymadığıdır.
Testleri düzenleme bazen bir maske veya hedef bölgeyle bir giriş görüntüsünden başlar. Asıl soru, her şey sabit kalırken istenen değişikliğin gerçekleşip gerçekleşmediğidir. quality dosyasını düzenlemek yalnızca "son görüntü iyi görünüyor mu?" değildir. Aynı zamanda "model kimliğini, düzenini, logo şeklini, product ayrıntılarını ve dokunulmamış bölgeleri korudu mu?"
Her iki parça için de her çalıştırmanın versiyonu. workflows görüntü oluşturmaya yönelik resmi OpenAI belgelerine göre, ekipler size çıktısı, quality, format ve mevcut olduğu yerde sıkıştırma gibi model yapılandırma alanlarına dikkat etmelidir. Bu ayarlar, ön işleme kuralları ve prompt sürümleri kilitlenmedikçe çalıştırmaları karşılaştırmayın.
En azından şunları saklayın:
| Alan | Neden önemli? |
|---|---|
| model ve model sürümü | Gizli model değişikliklerinin prompt değişiklikleri gibi görünmesini önler |
| prompt sürümü | Regresyon analizini mümkün kılar |
| size ve quality | quality çıkışı çözünürlük ve quality ayarları arasında geçiş yapabilir |
| çıktı formatı ve sıkıştırma | JPEG/WebP sıkıştırması OCR, ölçümleri ve görsel yapıları değiştirebilir |
| giriş resmi karması | Düzenlemenin tekrarlanabilirliği için gereklidir |
| referans seti karması | Eşleştirilmiş testler için gereklidir |
| seed politikası | prompt başına birden fazla adayı karşılaştırırken gereklidir |
| prompt sürümünü yargıla | Otomatik hakemler ölçüm sisteminin bir parçasıdır |
| insan kod kitabı versiyonu | Ek açıklama kuralları kararlı olmalıdır |
| CI iş ve git taahhüdü | Kararın denetlenebilir olmasını sağlar |
Üç Katmanlı Kalite Çerçevesi
Katman 1: Sert Kapılar
Zorunlu kontroller başarılı/başarısız kontrolleridir. Pazarlığa açık olmayan gereksinimler için kullanılmalıdırlar.
Ortak zorunlu kontroller:
- Gerekli metin tam olarak doğrudur.
- Gerekli nesneler mevcut.
- Yasak nesneler veya güvenli olmayan içerik yoktur.
- Görsel, marka veya gizlilik kurallarını ihlal etmemektedir.
- Düzenleme görevinde dokunulmayan alanlar değişmeden kalır.
- product etiketi, logosu, yüzü veya kimliğe duyarlı bölge korunur.
- Çıktı gerekli format, arka plan ve kırpma kısıtlamalarını karşılıyor.
Metin ağırlıklı varlıklar özel muameleyi hak eder. prompt, "Place Order" ifadesini gerektiriyorsa ve görüntüde "Place Odrer" yazıyorsa çıktı başarısız olur. Görsel kaliteyle bunu ortalamaya çıkarmayın.
Katman 2: Boyut Puanları
Zorunlu kontrollerdan sonra çıktıyı boyutlara göre puanlayın. Her nokta açıkça tanımlanmışsa 0-5 veya 1-5 ölçeği işe yarar.
Önerilen boyutlar:
| Boyut | Ne sorulmalı | Varsayılan hedef |
|---|---|---|
| Anlamsal hizalama | Resim prompt'ın temel amacını ifade ediyor mu? | En az 4/5 ortalama |
| Nesne varlığı | Tüm önemli nesneler görünür durumda mı? | Anahtar nesne hatırlama en az 0,95 |
| Özellik doğruluğu | Renkler, malzemeler, miktarlar ve etiketler doğru nesnelere mi bağlanmış? | En az 0,90 |
| Uzamsal ilişki doğruluğu | Sol/sağ, üst/alt, ön/arka ve kapatma doğru mu? | En az 0,90 |
| Metin oluşturma | Gerekli metin okunabilir ve tam mı? | Gerekli metin için %100 |
| Konumu düzenle | Yalnızca istenen bölge mi değişti? | En az 4/5 ortalama |
| Kimlik veya markanın korunması | Yüzler, logolar, yazı tipi ve product kimliği sabit kaldı mı? | En az 4/5 ortalama |
| Görsel quality | Görüntüde yapaylık yok mu ve üretim kullanılabilir mi? | En az 4/5 ortalama |
Önemli olan quality'in ayrıştırılmış olmasıdır. Bir model görsel cilalamada güçlü olabilir ancak mekansal ilişkilerde zayıf olabilir. Bir diğeri girdi görsellerini iyi bir şekilde koruyabilir ancak tam tipografi konusunda zorluk yaşayabilir. Değerlendirme bu farklılıkları görünür hale getirmelidir.
Katman 3: İnsan Tercihi ve A/B Testleri
İnsan tercihi review hala gereklidir. Otomatik metrikler faydalıdır ancak üretimle ilgili pek çok kaygıyı gözden kaçırırlar: tat, düzen dengesi, marka uyumu, inandırıcı malzeme sunumu ve bir tasarımın bitmiş gibi görünüp görünmediği.
A/B testleri için sol/sağ yerleştirmeyi rastgele yapın, model kimliğini gizleyin ve bağlara izin verin. Yalnızca "Model B daha iyi hissettirdi" demek yerine win oranını güven aralıklarıyla bildirin.
A/B testlerini aşağıdakiler için kullanın:
- GPT Image 2 ayarları arasında seçim yapma.
- GPT Image 2'nin yerleşik bir iş akışıyla karşılaştırılması.
- Zor geçitler geçtikten sonra creative quality inceleniyor.
- prompt revizyonunun sonucu iyileştirip iyileştirmediğine karar verme.
Pratik Metrik Seçimi
Her görsel metriğini sırf var olduğu için kullanmayın. Başarısızlık moduna göre metrikleri seçin.
| Metrik | Yön | En iyi kullanım | Ana güç | Ana zayıflık | Pratik eşik |
|---|---|---|---|---|---|
| FID | Daha düşük daha iyidir | Dağıtım düzeyinde regresyon | Oluşturulan görüntü dağıtımları için tarihsel olarak yaygın olan | Zayıf numune verimliliği; ön işleme duyarlı; modern istemlere özgü görevler için zayıf | Mutlak bir salım eşiği kullanmayın; yalnızca aynı referans seti ve ön işleme ile karşılaştırın |
| Inception Score | Daha yüksek daha iyidir | Eski referanssız üretim kontrolleri | Basit | Gerçek veri dağılımıyla karşılaştırılamaz; ince taneli sıralamayı yanıltabilir | Serbest bırakma kapısı olarak kullanmayın |
| LPIPS | Daha düşük daha iyidir | Eşleştirilmiş düzenlemeler ve yeniden yapılandırma | Algısal farklılığa piksel hatasından daha yakın | Eşleştirilmiş bir referansa ihtiyaç vardır; ilgisiz görevlerle karşılaştırılamaz | <= 0,20 kabul edilebilir, <= 0,10 güçlü |
| CLIPScore | Daha yüksek daha iyidir | İstemi görüntü hizalama | Kolay, reference image gerekmez | Kelime çantası gibi davranabilir ve karmaşık ilişkileri kaçırabilir | Başlangıç değerinin %97'sinden daha kötü olmaması gibi göreceli eşikler kullanın |
| PSNR | Daha yüksek daha iyidir | Aslına uygunluğu ve yeniden yapılanmayı düzenleyin | Ucuz ve yorumlanması kolay | Zayıf algısal hassasiyet | >= 30 dB kabul edilebilir, >= 35 dB güçlü |
| SSIM | Daha yüksek daha iyidir | Yapısal koruma | Yapı olarak PSNR'dan daha iyi | Stil değişiklikleri ve ince doku için daha az kullanışlıdır | >= 0,90 kabul edilebilir, >= 0,95 güçlü |
| DISTS | Daha düşük daha iyidir | Algısal ek | Doku ve yapı değişimlerine karşı daha sağlam | Üretim yığınlarında SSIM veya LPIPS'ye göre daha az yaygındır | Mutlak bir kapı olarak değil, göreceli regresyon olarak kullanın |
FID ve Inception Score, GPT Image 2 iş akışları için birincil sürüm kapısı olmamalıdır. Zaman içinde dağıtım düzeyindeki sapmanın izlenmesine yardımcı olabilirler, ancak belirli bir prompt'nin takip edilip edilmediğine, bir düğme etiketinin doğru olup olmadığına veya bir düzenlemenin bir product görüntüsünün yanlış kısmını değiştirip değiştirmediğine yanıt vermezler.
Anlamsal kontroller için mümkünse soru-cevap veya ayrıştırma tarzı değerlendirmeyi kullanın:
- Nesne, nitelik, sayı ve olgusal tutarlılık için TIFA tarzı kontroller.
- Görsel soru yanıtlama yoluyla anlık görüntü tutarlılığı için VQAScore tarzı kontroller.
- Nesne varlığı, sayısı, rengi ve konumu için GenEval tarzı kontroller.
- Mekansal ilişkiler için VISOR tarzı kontroller.
- I-HallA tarzı kontroller görüntü içeriğinde gerçek halüsinasyon olup olmadığını kontrol eder.
Bu yaklaşımlar değerlidir çünkü başarısızlıkları parçalara ayırırlar. Tek bir benzerlik puanı yerine "nesne var, renk yanlış, mekansal ilişki başarısız" gibi yanıtlar alıyorsunuz.
Anlamsal, Güvenlik ve Sağlamlık Kontrol Listesi
Bu tabloyu pratik bir varsayılan olarak kullanın.
| Kontrol etmek | Otomatik sinyal | İnsan review sorusu | Varsayılan eşik |
|---|---|---|---|
| Altyazı hizalaması | CLIPScore veya VQAScore tarzı jüri üyesi | Resim prompt'ın temel amacını ifade ediyor mu? | Başlangıç değerinin %97'sinden daha düşük değil |
| Anahtar nesne varlığı | TIFA veya GenEval tarzı kontroller | Gerekli tüm nesneler mevcut mu? | Hatırlama >= 0,95 |
| Özellik bağlama | TIFA, GenEval veya T2I-CompBench tarzı kontroller | Renk, malzeme, sayı ve metin doğru nesneye bağlı mı? | Doğruluk >= 0,90 |
| Mekansal ilişkiler | VISOR veya VQA prompts | Sol/sağ, üst/alt, ön/arka ve kapanma doğru mu? | Doğruluk >= 0,90 |
| Metin oluşturma | OCR artı tam eşleşme veya yargılama review | Gerekli metin tam mı? | Gerekli metin için %100 |
| Konumu düzenle | Eşleştirilmiş fark artı insan yargıç | El değmemiş bölgeler değişmeden mi kaldı? | Ortalama >= 4/5 |
| Kimlik ve marka | Benzerlik kontrolü ve yerel ürün review | Yüz, logo, yazı tipi ve product kimliği sabit kaldı mı? | Ortalama >= 4/5 |
Güvenlik ve önyargı, görüntü güzelliğinden ayrı değerlendirilmelidir.
| Risk | Nasıl test edilir | Sonuç türü |
|---|---|---|
| Zararlı içerik | prompt komutunu çalıştırın ve çıktı filtrelemeyi yapın; kırmızı takım yüksek riskli prompts | Başarılı/başarısız |
| Gizlilik veya neredeyse kopya çıktı | Dahili varlıklara yönelik yerleştirmeleri, algısal karmaları veya en yakın komşu aramasını kullanın | Başarılı/incele |
| Gerçek halüsinasyon | Gerçek iddialar için VQA tarzı kontroller kullanın | 0-1 veya 0-100 |
| Grup önyargısı | Yalnızca cinsiyeti, yaşı, etnik kökeni veya mesleği değiştiren karşı olgusal prompts kullanın | Fark puanı |
| Marka veya kişisel kötüye kullanım | Gerçek kişiler, ticari markalar, kimlikler ve tıbbi tarzdaki görüntüler için review kuralını daha sıkı uygulayın | Başarılı/başarısız |
Yüksek kaliteli bir görüntü otomatik olarak düşük riskli bir görüntü değildir. Pratik ekip yöntemi, karşı olgusal testtir: prompt değerini sabit tutun ve yalnızca grup özelliğini değiştirin, ardından meslek, duruş, giyim, yaş veya cilt tonunun sistematik olarak değişip değişmediğini kontrol edin.
Sağlamlık Test Matrisi
Yalnızca bir çıkış ayarını test etmeyin. GPT Image 2 quality çözünürlük, sıkıştırma, quality veya düzenleme bağlamı değiştiğinde değişebilir.
Küçük bir matris kullanın:
| Değişken | Önerilen değerler |
|---|---|
| Çözünürlük | Desteklendiği yerlerde 1024x1024, 1536x1024, 2048x2048, 3840x2160 |
| Kalite | Desteklendiği yerde low, medium, high |
| Sıkıştırma | PNG, JPEG/WebP 95, 85, 70 |
| Ölçek ardışık düzeni | Orijinal, alt örneklenmiş, alt örneklenmiş ve daha sonra üst örneklenmiş |
| Tıkanma ve kırpma | %10, %25, %40 rastgele tıkanma; kenar bitkileri; yerel ürünler |
| Tohumlar | prompt başına en az 3 aday |
| Girişleri düzenle | Farklı giriş görüntüsü quality seviyeleri ve kırpma bölgeleri |
Bu bürokrasi değil. Bir ekibin tek bir mükemmel koşulda model hatasını geçmesini ve ardından gerçek varlık hattındaki arızayı keşfetmesini engeller.
İnsan Değerlendirme Protokolü
İnsan review yalnızca protokol stabil olduğunda karar dereceli hale gelir.
Bu varsayılanı kullanın:
- scenario başına en az 100 prompts.
- prompt başına en az 3 tohum.
- Resim başına en az 3 ek açıklamalayıcı.
- medical, gizliliğe duyarlı, yasal, kimliğe duyarlı veya marka açısından kritik iş akışları gibi yüksek riskli kategoriler için 5 ek açıklamalayıcı kullanın.
- Zor kapı sorularını Likert puanlamasından ayırın.
- Sürümleri karşılaştırırken kör A/B testlerini kullanın.
- tie'ye izin ver ve emin olmadığın seçenekler.
"1 = kötü, 5 = iyi" gibi tembel derecelendirme ölçeklerinden kaçının. Her noktayı tanımlayın.
Örnek hizalama ölçeği:
| Gol | Tanım |
|---|---|
| 1 | prompt ile tamamen uyumsuz |
| 2 | prompt ile yalnızca biraz eşleşir |
| 3 | Önemli eksiklikler veya hatalar içeren kısmen eşleşiyor |
| 4 | Küçük sorunlar dışında neredeyse tamamen eşleşiyor |
| 5 | prompt ile tamamen eşleşir |
Örnek görsel quality ölçeği:
| Gol | Tanım |
|---|---|
| 1 | Açıkça kırık veya kullanılamaz durumda |
| 2 | Dikkat çekici derecede kusurlu |
| 3 | Taslak kullanım için kabul edilebilir |
| 4 | İyi ve muhtemelen kullanışlı |
| 5 | Profesyonel prodüksiyona yakın quality |
Ek açıklama kılavuzu ayrıca şunları tanımlamalıdır:
- Hangi prompt parçaları katı kısıtlamalardır.
- Gerekli bir nesnenin eksik olup olmadığı bir başarısızlıktır.
- Yanlış bir metin karakterinin başarısız olup olmadığı.
- Uzamsal ilişkilerin, niceliğin ve renk bağlamanın nasıl değerlendirileceği.
- creative eklemelere izin verilip verilmediği.
- İstenmeyen düzenleme olarak sayılanlar.
- Yaklaşık ve kesin doğruluk arasındaki fark.
- Ek açıklamalar yapanların tie seçebileceği veya emin olmadığı durumlar.
Bu kurallar olmadan değerlendirme sadece gürültülü olmaz. Tekrarlanamaz.
Örneklem Büyüklüğü ve İstatistiksel Raporlama
Küçük değerlendirmeler hata ayıklama açısından yararlı olabilir ancak başlatma kararlarını etkilememelidir.
Pratik kurallar:
- 100'den az prompts ile model karşılaştırmaları kolaylıkla tersine dönebilir.
- Artı veya eksi %5 civarında %95 güven aralığına sahip bir ikili pass oranı için, konservatif örnek size yaklaşık 384 örnektir.
- Beklenen pass oranı %85 civarındaysa, yaklaşık 196 örnek benzer bir hata aralığına ulaşabilir.
- Beklenen avantajın yaklaşık 60/40 olduğu bir A/B tercih testi için, kabaca 200 geçerli ikili karşılaştırma planlayın.
- Daha güçlü bir 65/35 tercihi daha az örneğe ihtiyaç duyar ancak yine de senaryolar arasında yeterli kapsama ihtiyacı vardır.
Ortalamadan daha fazlasını rapor edin:
| Amaç | Birincil metrik | Önerilen test | Rapor |
|---|---|---|---|
| Serbest bırakma kapısı | Metin veya güvenlik pass oranı | Tam binom aralığı veya iki oran testi | Geçiş oranı, %95 CI, mutlak fark |
| A/B tercihi | Kazanma oranı, bağların göz ardı edilmesi | Tam binom testi | Kazanma oranı, %95 CI, p değeri |
| Eşleştirilmiş Likert puanı | Hizalama, quality, konum | Wilcoxon signed-rank | Medyan fark, p değeri, etki size |
| Bağımsız Likert grupları | Senaryo veya model ailesi karşılaştırması | Mann-Whitney U | Dağılım farkı, p değeri |
| Ek açıklamacı sözleşmesi | Krippendorff's alpha sıralı etiketler için | Güvenilirlik tahmini | Alfa değeri |
Ekibinizin yazılı bir nedeni olmadığı sürece alpha = 0,05, iki taraflı seçeneğini kullanın. Birden fazla birincil metriği raporluyorsanız çoklu karşılaştırma düzeltmesi uygulayın. Açıklayıcı anlaşması için Krippendorff's alpha >= 0,80 güvenilir bir hedeftir; 0,667 - 0,80 geçici olarak değerlendirilmelidir.
Otomasyon ve Tekrarlanabilirlik
Değerlendirme sistemi product kodu gibi versiyonlanmalıdır. İyi bir boru hattı şöyle görünür:
- scenario dilimlerini ve risk katmanlarını tanımlayın.
- prompts oluşturun, görüntüleri, maskeleri ve referans örneklerini girin.
- size, quality, format, sıkıştırma ve seed ayarları genelinde gruplar oluşturun.
- Metin, nesne varlığı, güvenlik ve düzenleme konumu için zorunlu kontrollerı çalıştırın.
- LPIPS, SSIM, CLIPScore, TIFA tarzı kontroller, VQAScore tarzı kontroller, GenEval tarzı kontroller ve VISOR tarzı kontroller gibi otomatik ölçümleri çalıştırın.
- Sınırda ve örneklenmiş çıktıları insan incelemesine gönderin.
- İstatistiksel testleri ve açıklayıcı-anlaşma kontrollerini çalıştırın.
- Hataları scenario, hata türü ve yapılandırmaya göre gösteren bir kontrol paneli yayınlayın.
- Arıza durumlarını saklayın ve bunları prompts, maskeler veya workflow kurallarını iyileştirmek için kullanın.
Yararlı takım kategorileri:
| Araç kategorisi | Örnek araçlar | Amaç |
|---|---|---|
| Resim metrikleri | TorchMetrics, PIQ | FID, IS, LPIPS, CLIPScore, PSNR, SSIM, DISTS, NIQE |
| Anlamsal değerlendirme | TIFA, VQAScore, GenEval, VISOR tarzı test setleri | Nesne, nitelik, sayım, mekansal ve anlık doğruluk kontrolleri |
| Sürüm oluşturma | DVC, git, yapı depolama | Sürüm prompts, resimler, referanslar, ölçümler ve çıktılar |
| CI | GitHub Actions veya eşdeğeri | Regresyon testlerini çalıştırın ve sürümleri engelleyin |
| Kontrol Paneli | BI kontrol paneli veya dahili rapor | pass oranlarını, puan dağılımlarını, maliyetleri, gecikmeyi ve başarısızlık durumlarını göster |
Kontrol panelinde yalnızca küresel ortalama gösterilmemelidir. Sonuçları en azından şu şekilde ayırın:
- Senaryo
- Arıza türü
- Boyut
- Kalite ayarı
- Sıkıştırma
- Hızlı aile
- Risk katmanı
- Modeli sürümü
Ayrıca operasyon ölçümlerini de izleyin. Yüksek kaliteli ayarlar gecikmeyi veya maliyeti iki katına çıkarırken insan tercihini yalnızca küçük bir miktar iyileştiriyorsa bu yalnızca bir araştırma sonucu değil, product kararıdır.
Örnek Değerlendirme Şeması
Basit bir CSV veya JSON şeması, değerlendirmenin denetlenebilir olmasını sağlar.
| Alan | Tip | Anlam |
|---|---|---|
| run_id | string | Değerlendirme çalıştırması kimliği |
| prompt_id | string | Benzersiz prompt kimliği |
| scenario | string | product, ux, creative, medical veya industrial |
| risk_tier | string | low, medium veya high |
| prompt_text | string | Orijinal prompt |
| model | string | Model adı |
| model_version | string | Modeli sürümü |
| size | string | Çıkış size |
| quality | string | Kalite ayarı |
| output_format | string | png, jpeg veya webp |
| output_compression | int | Sıkıştırma değeri |
| seed | int | Aday seed veya seed politika kimliği |
| reference_id | string | Eşleştirilmiş testler için referans |
| gate_instruction | int | 0 veya 1 |
| gate_text_exact | int | 0 veya 1 |
| gate_safety | int | 0 veya 1 |
| object_presence | float | 0'dan 1'e |
| attribute_accuracy | float | 0'dan 1'e |
| spatial_accuracy | float | 0'dan 1'e |
| locality_score | float | 0'dan 5'e |
| visual_quality | float | 0'dan 5'e |
| human_pref_win | string | win, loss veya tie |
| annotator_id | string | Gerçek kişi incelemeci kimliği |
| rationale | string | Kısa sebep |
| latency_ms | int | Oluşturma gecikmesi |
| cost_estimate | float | Tahmini maliyet |
| overall_verdict | string | pass, review veya fail |
Nihai Takım Kontrol Listesi
GPT Image 2 öğesini workflow için üretime hazır olarak değerlendirmeden önce aşağıdakileri yaptığınızdan emin olun:
- Sürüm hedefini tanımladı: model seçimi, gerileme veya başlatma kapısı.
- Tanımlanmış scenario dilimler ve risk katmanları.
- Gerekli nesneler, gerekli metin, yasak içerik ve düzenleme yapılmayan bölgeler için yazılı katı kısıtlamalar.
- Normal örnekler, zorluk örnekleri ve güvenlik veya önyargı örneklerinden oluşan bir prompt seti oluşturduk.
- İstem başına en az 3 aday oluşturuldu.
- En az iki size ayarı ve desteklendiği yerlerde iki quality ayarı test edildi.
- Ortalama kaliteye bakmadan önce metin, nesne, güvenlik ve düzenleme konumu kapılarını çalıştırın.
- Anlamsal hizalama, nesne varlığı, öznitelik bağlama, mekansal ilişkiler ve görsel quality ayrı ayrı ölçüldü.
- creative uyumu, marka uyumu ve sınırda durumlar için insan review kullanıldı.
- Raporlanan güven aralıkları, etki büyüklükleri, istatistiksel anlamlılık ve açıklayıcı anlaşma.
- Sürümlendirilmiş prompts, resimler, ayarlar, ölçümler, yargıç prompts, insan kod kitapları ve komut dosyaları.
- Çıktıların yalnızca başarısız olduğunu değil, neden başarısız olduğunu gösteren bir gösterge panosu oluşturuldu.
Kısa versiyon: GPT Image 2'yi workflow geçitleri, semantik ayrıştırma, insan review, istatistiksel disiplin ve versiyonlanmış regresyonla değerlendirin. Gösterişli bir ortalama puanın üretim hatasını gizlemesine izin vermeyin.