一套可供團隊落地使用的 GPT Image 2 輸出品質評估框架,涵蓋硬性門檻、語意檢查、圖像指標、人工審查、穩健性測試與 CI 報告。
評估 GPT Image 2 輸出品質與詢問影像是否令人印象深刻不同。如果所需的文字拼字錯誤、產品標籤被更改、UI 按鈕遺失、徽標漂移或編輯更改了圖像中本應保持不變的部分,那麼漂亮的圖像仍然可能會失敗。
对于团队来说,更好的问题是:GPT Image 2 能否足够可靠地完成此工作流程以进行交付?
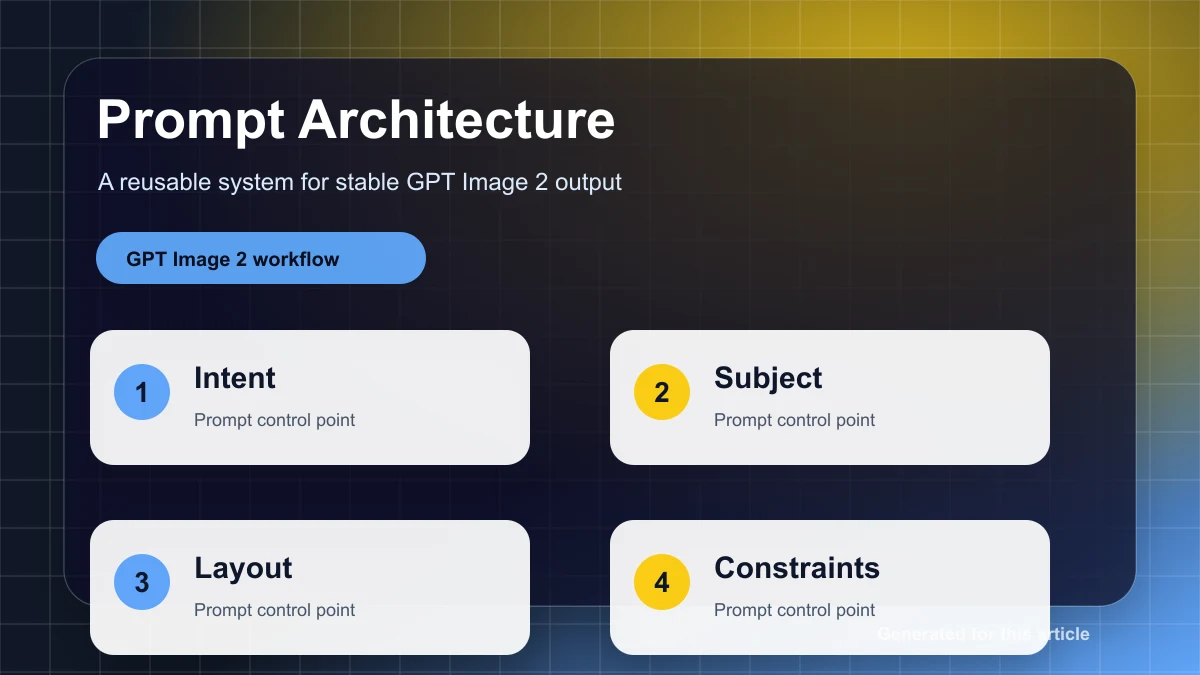
這個問題需要一個結構化的評估體系。最有用的方法是三層模型:
- 硬門符合不可協商的要求,例如精確的文字、安全性、所需物件和編輯位置。
- 維度級評分,用於語義對齊、視覺品質、空間準確性、品牌一致性和保存。
- 人類偏好或 A/B 審查用於自動化指標不夠的決策。
不要將影像品質降低到一個平均分數。单个分数隐藏了真正重要的故障模式。一張視覺評分為 4.6/5 但標題中有一個錯誤字符的營銷海報並不是“幾乎不錯”;這是一個失敗的生產資產。
此清單專為需要在實際工作流程中比較 GPT Image 2 輸出的買家、創作者、產品團隊、設計團隊、QA 團隊和工程團隊而設計。它保留了在嚴格的影像模型測試中使用的實用閾值和評估結構,同時避免了過度信任傳統指標(例如 FID 或 Inception Score)的常見陷阱。
從工作流程開始,而不是模型
在選擇指標之前,先定義場景。产品图片、移动用户界面模型、海报、人物表和医学教学图不会以同样的方式失败。
如果尚未指定您的資料集,請先將評估拆分為場景切片。然後決定哪些檢查對每個切片很重要。
| 網域 | 常見 GPT Image 2 用例 | 第一次品質檢查 | 註解 |
|---|---|---|---|
| 產品展示 | 白背景產品照片、包裝、廣告、品牌權益編輯 | 準確的文字、完整的標籤、乾淨的邊緣、不溢出的本地編輯 | 最適合配對編輯測驗和硬門 |
| UX | UI 模型、流程畫面、資訊架構圖、按鈕複製影像 | 所需的元件、佈局層次結構、精確的按鈕文字、可用性 | 文字門應該會出現在顏值分數之前 |
| 創意 | 廣告關鍵視覺效果、漫畫、分鏡、海報、角色表 | 風格一致性、敘述連續性、可讀文字、品牌或人物一致性 | 人類的偏好非常有價值 |
| 醫療 | 教育插畫、合成醫學風格的視覺效果、案例風格的圖表 | 隱私、近乎重複的風險、真實性、臨床相關屬性 | 用例和監管標準必須單獨校準 |
| 工業 | 設備標籤、維護插圖、技術板、概念視覺效果 | 文本和符號的準確性、空間關係、材料和結構的合理性 | 應在發布前定義行業容差 |
如果團隊資源有限,請從四個部分開始:
- 文字較多的海報
- 使用者介面模型
- 本地圖像編輯
- 複雜成分prompts
這四個類別暴露了許多在生產中重要的失敗:拼寫錯誤的文本、缺少的元素、薄弱的空間推理、過度編輯和淺薄的 prompt 跟隨。
將生成測試與編輯測試分開
GPT Image 2的評測應該分成兩個軌道。
產生測試從 prompt 開始,沒有確切的參考影像。核心問題是圖像是否遵循 prompt:物件、屬性、關係、計數、樣式、文字和安全約束。
編輯測試從輸入影像開始,有時會帶有 mask 或目標區域。核心問題是所請求的改變是否發生而其他一切都保持穩定。編輯品質不僅僅是“最終圖像看起來不錯嗎?”它還“模型是否保留了身份、佈局、標誌形狀、產品細節和未受影響的區域?”
對於這兩個軌道,每次運行都要進行版本控制。根據影像產生工作流程的官方 OpenAI 文檔,團隊應注意模型配置字段,例如輸出大小、品質、格式和壓縮(如果可用)。除非這些設定、預處理規則和 prompt 版本已鎖定,否則請勿比較運行。
至少,儲存:
| 領域 | 為什麼這很重要 |
|---|---|
| 型號和型號版本 | 防止隱藏的模型更改看起來像 prompt 更改 |
| prompt版 | 使迴歸分析成為可能 |
| 尺寸和品質 | 輸出品質可以根據解析度和品質設定而變化 |
| 輸出格式和壓縮 | JPEG/WebP 壓縮可以更改 OCR、指標和視覺偽影 |
| 輸入圖像哈希 | 編輯再現性所需 |
| 參考集哈希 | 配對測驗所需 |
| seed政策 | 每個 prompt 比較多個候選者時需要 |
| judge prompt版本 | 自動化 judge 是測量系統的一部分 |
| 人類密碼本版本 | 註解器規則必須穩定 |
| CI 作業和 git 提交 | 使決策可審計 |
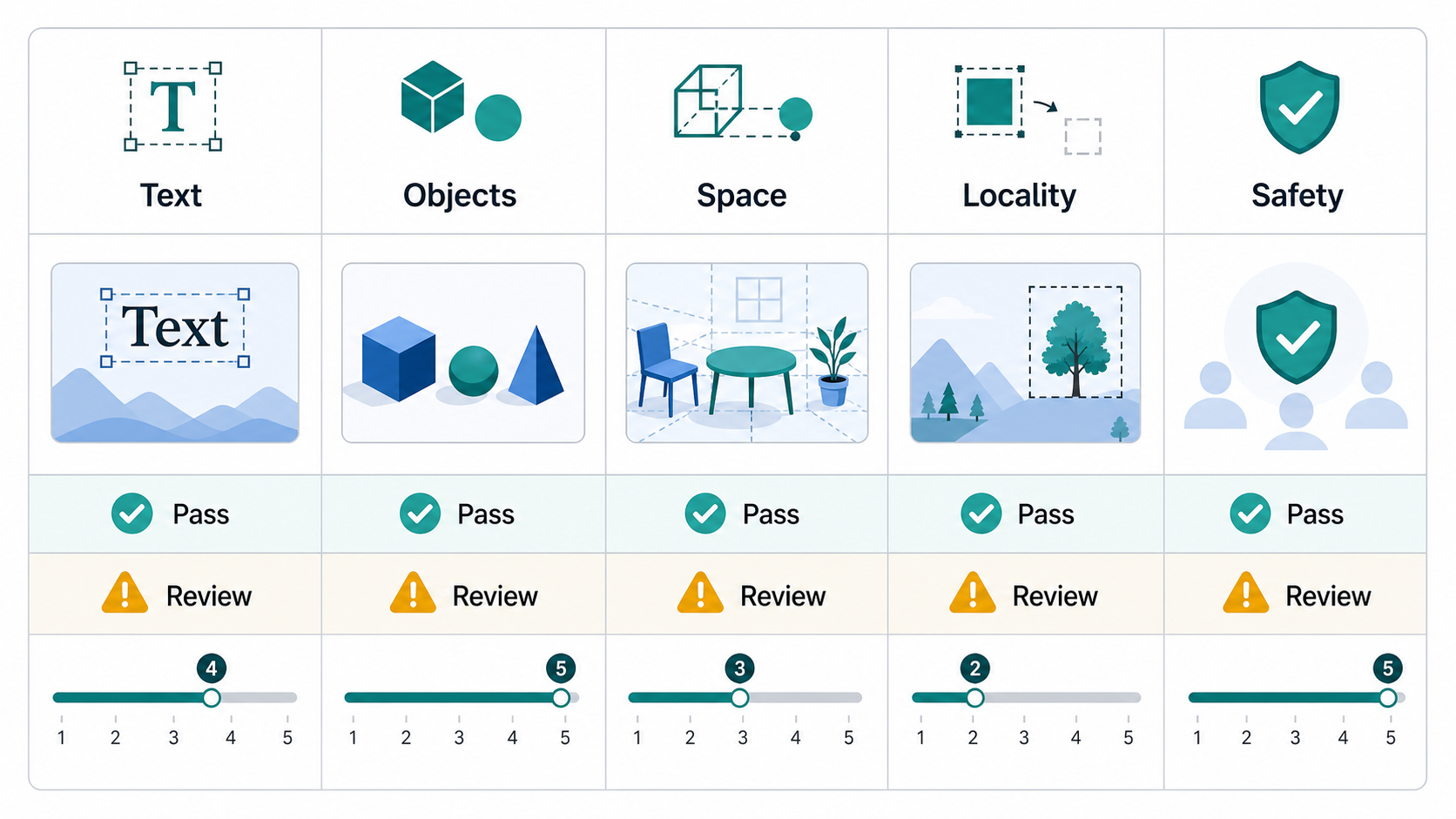
三層品質框架
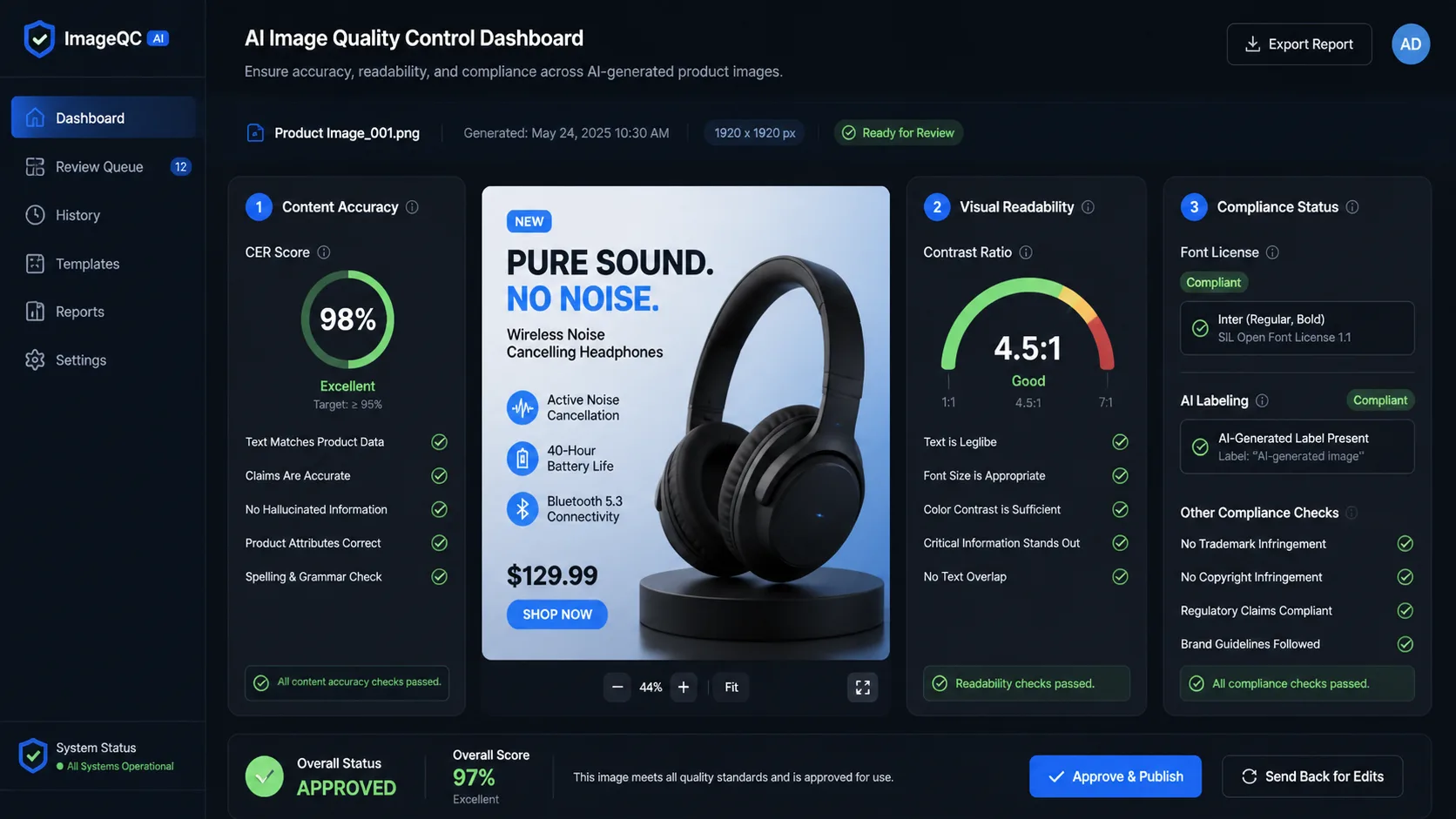
1層:硬門
硬門是通過/失敗檢查。它們應該用於不可協商的要求。
常見的硬質門:
- 所需的文字完全正確。
- 存在所需的對象。
- 不存在禁止對像或不安全內容。
- 該圖像不違反品牌或隱私規則。
- 在編輯任務中,未觸及的區域保持不變。
- 保留產品標籤、標誌、臉部或身分敏感區域。
- 輸出滿足所需的格式、背景和裁剪限制。
文本密集型資產值得特殊對待。如果 prompt 需要短語“Place Order”,而圖像顯示“Place Odrer”,則輸出失敗。不要將其與視覺品質相平均。
層 2:維度分數
在硬門之後,對跨維度的輸出進行評分。如果每個點都定義明確,則 0-5 或 1-5 標度即可運作。
推薦尺寸:
| 尺寸 | 要問什麼 | 預設目標 |
|---|---|---|
| 語意對齊 | 該圖像是否表達了prompt的核心意圖? | 平均至少 4/5 |
| 物體存在 | 所有關鍵物件都可見嗎? | 關鍵對象回憶至少 0.95 |
| 屬性準確度 | 顏色、材質、數量和標籤是否綁定到正確的物件上? | 至少0.90 |
| 空間關係準確度 | 左/右、上/下、前/後、遮擋是否正確? | 至少0.90 |
| 文字渲染 | 所需文字可讀且準確嗎? | 100% 為所需文本 |
| 編輯地點 | 僅請求的區域發生變化嗎? | 平均至少 4/5 |
| 身份或品牌保護 | 外觀、標誌、類型和產品識別是否保持穩定? | 平均至少 4/5 |
| 視覺品質 | 影像是否無偽影並且可以用於生產? | 平均至少 4/5 |
重要的一點是品質是分解的。模型可能在視覺修飾方面很強,但在空間關係方面較弱。另一種可能可以很好地保留輸入影像,但難以精確排版。評估應該使這些差異顯而易見。
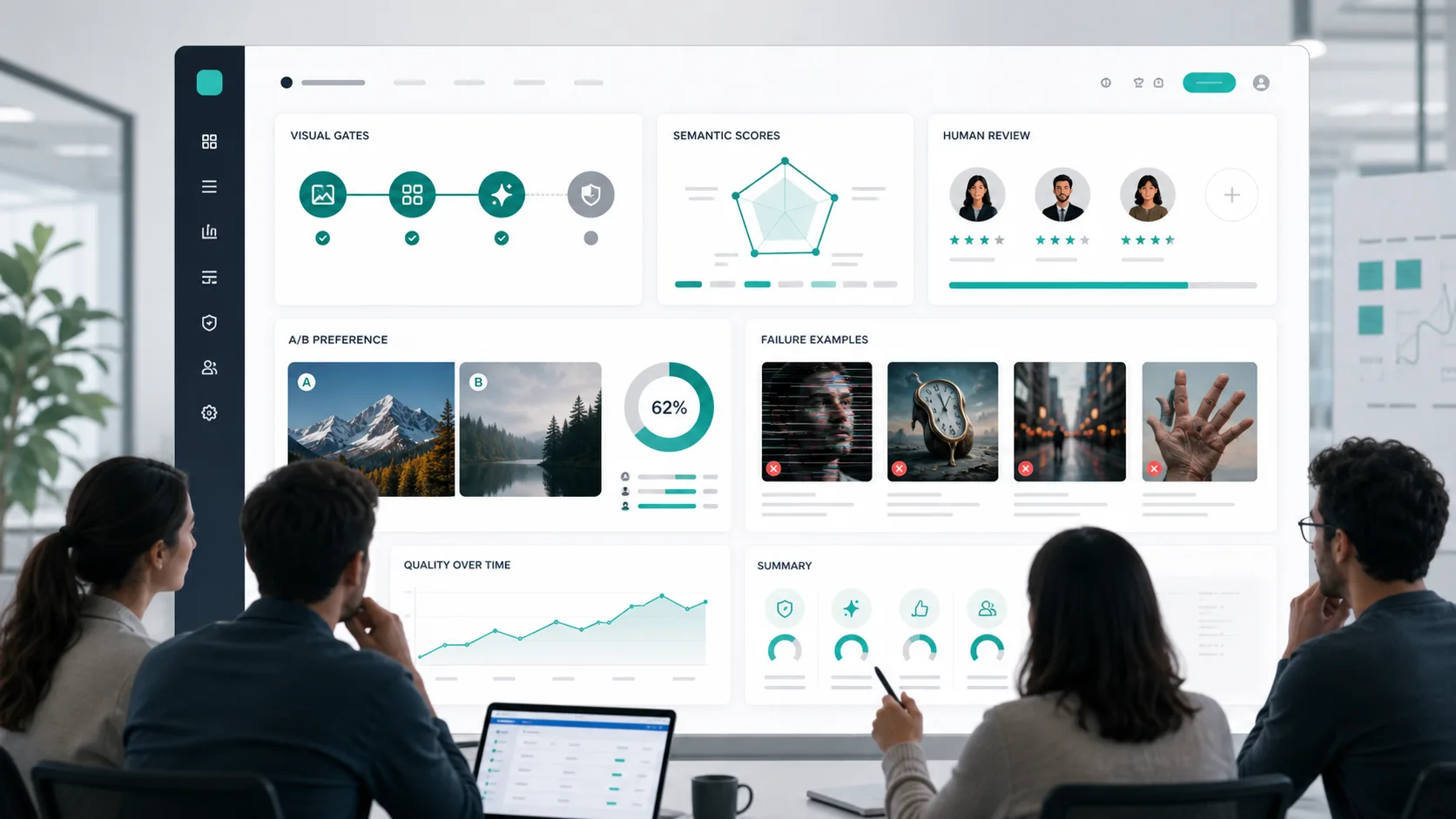
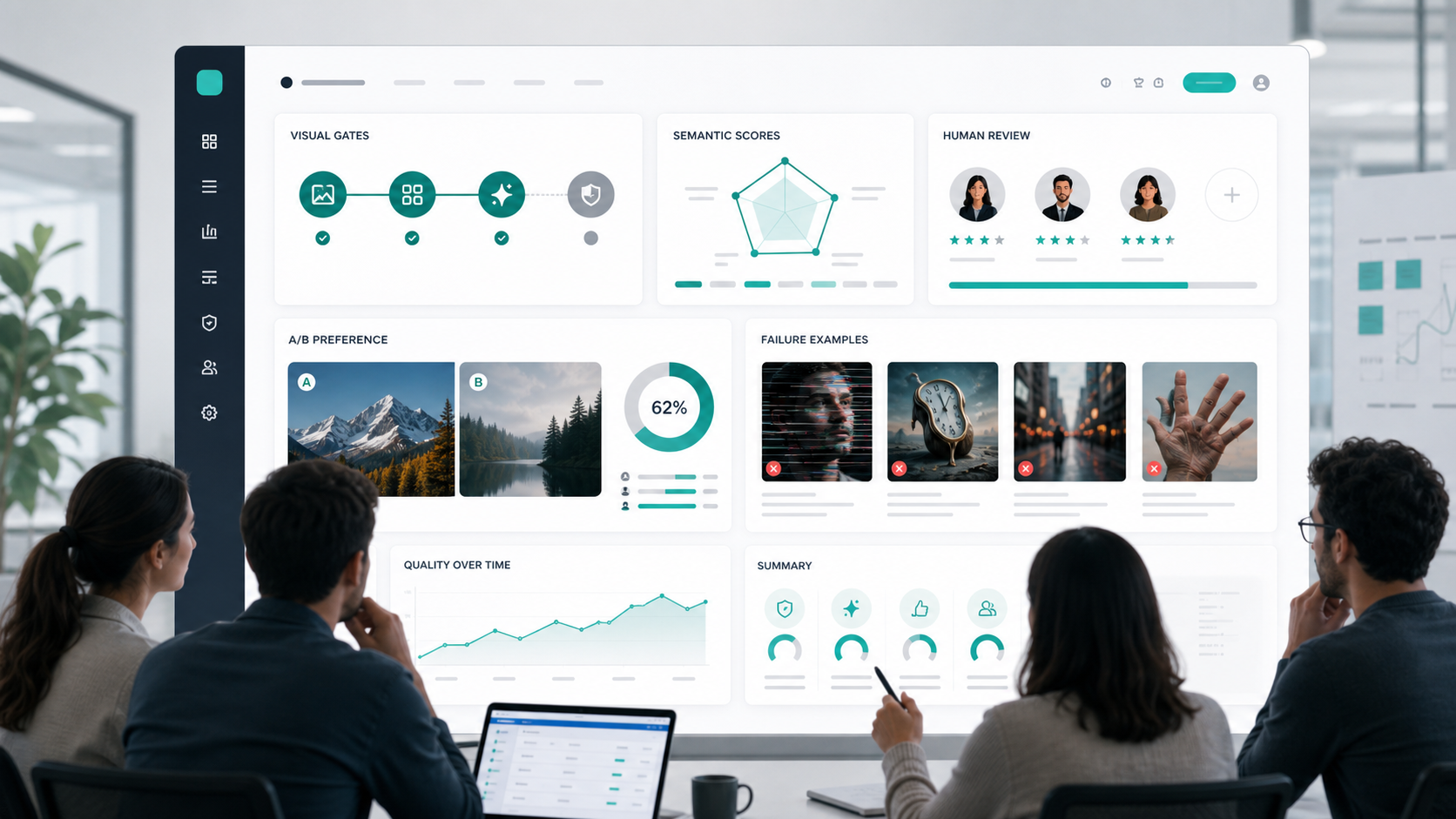
3 層:人類偏好和 A/B 測試
人類偏好審查仍然是必要的。自動化指標很有用,但它們忽略了許多生產問題:品味、佈局平衡、品牌契合度、可信賴的材質渲染以及設計是否感覺已完成。
對於 A/B 測試,隨機化左/右放置、隱藏模型身份並允許平局。用置信區間報告勝率,而不是只說「模型 B 感覺更好」。
使用 A/B 測試:
- 在 GPT Image 2 設定之間進行選擇。
- 將 GPT Image 2 與現有工作流程進行比較。
- 透過艱難關口後檢視創意品質。
- 確定 prompt 修訂是否改善了結果。
實用的指標選擇
不要僅僅因為每個圖像指標存在就使用它。根據故障模式選擇指標。
| 公制 | 方向 | 最佳使用 | 主要實力 | 主要弱點 | 實用門檻 |
|---|---|---|---|---|---|
| UX | 越低越好 | 分佈水平回歸 | 歷史上生成的圖像分佈很常見 | 樣品效率差;對預處理敏感;對於現代 prompt 特定任務來說較弱 | 不要使用絕對釋放閾值;僅與相同的參考集和預處理進行比較 |
| UX | 越高越好 | 傳統的無參考生成檢查 | 簡單 | 不與真實資料分佈進行比較;可能會誤導細粒度排名 | 請勿用作釋放門 |
| UX | 越低越好 | 配對編輯和重建 | 比像素誤差更接近感知差異 | 需配對參考;不相關任務之間不可比較 | <= 0.20 可接受,<= 0.10 較強 |
| UX | 越高越好 | 提示影像對齊 | 簡單,無需參考影像 | 可能表現得像詞袋分數並錯過複雜的關係 | 使用相對閾值,例如不低於基線的 97% |
| UX | 越高越好 | 編輯保真度和重建 | 便宜且易於解釋 | 感知靈敏度差 | >= 30 dB 可接受,>= 35 dB 強 |
| UX | 越高越好 | 結構保存 | 結構優於PSNR | 對於風格變化和精細紋理不太有用 | <= 0.20 可接受,<= 0.10 較強 |
| UX | 越低越好 | 感性補充 | 對紋理和結構的權衡更穩健 | 在生產堆疊中不如 SSIM 或 LPIPS 常見 | 用作相對回歸,而不是絕對門 |
FID 和 Inception Score 不應成為 GPT Image 2 工作流程的主要發佈入口。它們可以幫助監控隨時間推移的分佈等級漂移,但它們無法回答是否遵循了特定的 prompt、按鈕標籤是否正確,或者編輯是否更改了產品圖像的錯誤部分。
對於語意檢查,請盡可能使用問答或分解式評估:
- TIFA-style 檢查物件、屬性、計數和事實一致性。
- VQAScore-style 透過視覺問答檢查prompt-image 的一致性。
- GenEval-style 檢查物件的存在、數量、顏色和位置。
- VISOR-style 檢查空間關係。
- I-HallA-style 檢查圖像內容中的事實幻覺。
這些方法很有價值,因為它們可以分解失敗。您得到的不是一個相似度分數,而是「物件存在、顏色錯誤、空間關係失敗」之類的答案。
語意、安全性和穩健性檢查表
使用此表作為實際預設值。
| 檢查 | 自動訊號 | 人工審核問題 | 預設閾值 |
|---|---|---|---|
| 標題對齊 | CLIPScore 或 VQAScore-style judge | 該圖像是否表達了prompt的核心意圖? | 不低於基線的97% |
| 關鍵物體存在 | TIFA 或 GenEval-style 檢查 | 所有必需的物件都存在嗎? | 召回 >= 0.95 |
| 屬性綁定 | TIFA、GenEval 或 T2I-CompBench-style 檢查 | 顏色、材質、數量和文字是否綁定到正確的物件? | 精準度 >= 0.90 |
| 空間關係 | VISOR 或 VQA prompts | 左/右、上/下、前/後、遮擋是否正確? | 精準度 >= 0.90 |
| 文字渲染 | OCR 加精確匹配或 judge 審核 | 所需文字準確嗎? | 100% 為所需文本 |
| 編輯地點 | 配對 diff 加上人類 judge | 未觸及的區域是否保持不變? | 平均 >= 4/5 |
| 身份和品牌 | 相似性檢查加上本地作物審查 | 外觀、標誌、類型和產品標識是否保持穩定? | 平均 >= 4/5 |
安全性和偏見應與圖像美感分開評估。
| 風險 | 如何測試 | 結果類型 |
|---|---|---|
| 有害內容 | 運行prompt並輸出濾波;紅隊高風險prompts | 通過/失敗 |
| 隱私或幾乎重複的輸出 | 對內部資產使用嵌入、感知哈希或最近鄰搜索 | 通過/審查 |
| 事實幻覺 | 使用 VQA 式檢查來檢查事實聲明 | 0-1 或 0-100 |
| 群體偏見 | 使用僅改變性別、年齡、種族或職業的反事實 prompts | 差異分數 |
| 品牌或個人濫用 | 對真人、商標、ID 和醫療風格圖像進行更嚴格的審查 | 通過/失敗 |
高质量图像并不一定是低风险图像。實用的團隊方法是反事實測試:保持prompt不變,只改變團隊屬性,然後系統地檢查職業、姿勢、服裝、年齡或膚色是否有變化。
穩健性測試矩陣
不要僅測試一種輸出設定。當解析度、壓縮、品質或編輯上下文發生變化時,GPT Image 2 品質可能會發生變化。
使用一個小矩陣:
| 變數 | 建議值 |
|---|---|
| 解析度 | 1024x1024、1536x1024、2048x2048、3840x2160(若支援) |
| 品質 | 低、中、高(如果支持) |
| 壓縮 | PNG、JPEG/WebP、95、85、70 |
| 規模管道 | 原始、下採樣、下採樣然後上採樣 |
| 遮擋和裁剪 | 10%、25%、40%隨機遮蔽;邊緣作物;當地農作物 |
| 種子 | 每個 prompt 至少有 3 候選者 |
| 編輯輸入 | 不同的輸入影像品質等級和裁剪區域 |
這不是官僚主義。它阻止團隊在一種完美條件下通過模型,然後在實際資產管道中發現故障。
人類評估協議
只有當協議穩定時,人工審核才會變成決策級。
使用此預設值:
- 每個場景至少100 prompts。
- 每個 prompt 至少3 seeds。
- 每個圖像至少3 註釋器。
- 将5 注释器用于高风险类别,例如医疗、隐私敏感、法律、身份敏感或品牌关键工作流程。
- 將硬門問題與 Likert 評分分開。
- 比較版本時使用盲 A/B 測試。
- 允許平局和不確定的選項。
避免使用懒惰的评分标准,例如“1 = 差,5 = 好”。定義每個點。
對齊比例範例:
| 分數 | 定義 |
|---|---|
| UX | 與prompt完全不匹配 |
| UX | 僅與 prompt 略有匹配 |
| UX | 部分匹配,有重要遺漏或錯誤 |
| UX | 幾乎完全匹配,有一些小問題 |
| UX | 與prompt完全匹配 |
視覺品品質表範例:
| 分數 | 定義 |
|---|---|
| UX | 明顯損壞或無法使用 |
| UX | 明顯有缺陷 |
| UX | 可接受草稿使用 |
| UX | 良好且可能可用 |
| UX | 近乎專業的生產品質 |
註釋指南也必須定義:
- 其中prompt部分是硬約束。
- 缺少一個所需物件是否失敗。
- 一個錯誤的文字字元是否為失敗。
- 如何judge的空間關係、數量和色彩綁定。
- 是否允許添加創意。
- 什麼算是未經請求的編輯。
- 近似正確性和精確正確性之間的差異。
- 當註釋者可能選擇平局或不確定時。
如果沒有這些規則,評估就不僅僅是噪音。它是不可重現的。
樣本量和統計報告
小型評估對於調試很有用,但它們不應該驅動啟動決策。
實用規則:
- 如果少於100 prompts,模型比較可以輕鬆翻轉。
- 对于 95% 置信区间约为正负 5% 的二进制通过率,保守样本大小约为384样本。
- 如果预期通过率约为 85%,则大约196样本可以达到类似的误差范围。
- 對於預期優勢約為60/40的 A/B 偏好測試,請規劃大致200有效配對比較。
- 更強的65/35偏好需要更少的樣本,但仍需要足夠的跨場景覆蓋。
報告多於平均值:
| 目標 | 主要指標 | 建議測試 | 報告 |
|---|---|---|---|
| 釋放門 | 文字或安全通過率 | 精確二項式區間或二比例檢定 | 通過率,95% CI,絕對差值 |
| A/B 偏好 | 勝率,忽略平局 | 精確二項式檢定 | 勝率,95% CI,p 值 |
| 配對 Likert 分數 | 一致性、品質、局部性 | UX | 中位數差、p 值、效應大小 |
| 獨立的Likert組 | 場景或模型系列比較 | UX | 分佈差異,p 值 |
| 註釋者協議 | Krippendorff's alpha 用於序數標籤 | 可靠性估計 | 阿爾法值 |
使用alpha = 0.05,雙面,除非您的團隊有書面理由不這樣做。如果您報告多個主要指標,請套用多重比較校正。對於註釋者協議,Krippendorff's alpha >= 0.80是可靠的目標;0.667 至 0.80應視為暫定。
自動化和再現性
評估系統應該像產品代碼一樣進行版本控制。一個好的管道看起來像這樣:
- 定義場景切片和風險等級。
- 建立 prompts、輸入影像、masks 和參考樣本。
- 跨大小、品質、格式、壓縮和 seed 設定產生批次。
- 為文字、物件存在、安全性和編輯位置運行硬門。
- 執行自動指標,例如 LPIPS、SSIM、CLIPScore、TIFA-style 檢查、VQAScore-style 檢查、GenEval-style 檢查和 VISOR-style 檢查。
- 將邊界和採樣輸出傳送給人工審核。
- 運行統計測試和註釋者協議檢查。
- 發布按場景、故障類型和配置顯示故障的儀表板。
- 儲存失敗案例並使用它們來改進 prompts、masks 或工作流程規則。
有用的工具類別:
| 工具類 | 範例工具 | 目的 |
|---|---|---|
| 影像指標 | 火炬指標、PIQ | FID、IS、LPIPS、CLIPScore、PSNR、SSIM、DISTS、NIQE |
| 語意評價 | TIFA、VQAScore、GenEval、VISOR-style 測試儀 | 物件、屬性、計數、空間和 prompt-faithfulness 檢查 |
| 版本控制 | DVC,git,工件存儲 | 版本 prompts、影像、參考、指標和輸出 |
| UX | GitHub Actions 或同等產品 | 運行回歸測試並阻止發布 |
| 儀表板 | BI 儀表板或內部報告 | 顯示通過率、分數分佈、成本、延遲和失敗案例 |
儀表板不應僅顯示全球平均值。至少,將結果細分為:
- 場景
- 故障類型
- 尺寸
- 品質設定
- 壓縮
- 提示家人
- 風險等級
- 型號版本
還追蹤營運指標。如果高品質的設定使延遲或成本加倍,而僅少量改善人類偏好,那麼這是產品決策,而不僅僅是研究結果。
評估方案範例
簡單的 CSV 或 JSON 模式可維持評估的可審核性。
| 領域 | 類型 | 意義 |
|---|---|---|
| run_id | string | 評估運行 ID |
| prompt_id | string | 唯一的prompt ID |
| scenario | string | 產品、使用者體驗、創意、醫療或工業 |
| risk_tier | string | 低、中或高 |
| prompt_text | string | 原廠prompt |
| model | string | 型號名稱 |
| model_version | string | 型號版本 |
| size | string | 輸出尺寸 |
| quality | string | 品質設定 |
| output_format | string | png、jpeg 或 webp |
| output_compression | int | 壓縮值 |
| seed | int | 候選seed或seed保單ID |
| reference_id | string | 配對測驗參考 |
| gate_instruction | int | 0 或 1 |
| gate_text_exact | int | 0 或 1 |
| gate_safety | int | 0 或 1 |
| object_presence | float | 0 至 1 |
| attribute_accuracy | float | 0 至 1 |
| spatial_accuracy | float | 0 至 1 |
| locality_score | float | 0 至 1 |
| visual_quality | float | 0 至 1 |
| human_pref_win | string | 獲勝、失敗或平局 |
| annotator_id | string | 人工審核者 ID |
| rationale | string | 簡短的理由 |
| latency_ms | int | 產生延遲 |
| cost_estimate | float | 預計費用 |
| overall_verdict | string | 通過、審核或失敗 |
最終團隊清單
在將 GPT Image 2 視為工作流程的生產就緒狀態之前,請確認您已完成以下操作:
- 定義發布目標:模型選擇、回歸或啟動閘。
- 定義場景切片和風險等級。
- 對所需物件、所需文字、禁止內容和禁止編輯區域的書面硬性約束。
- 建立了一個包含正常範例、挑戰範例以及安全或偏見範例的 prompt 集合。
- 每個 prompt 至少產生 3 候選者。
- 在支援的情況下測試了至少兩種尺寸設定和兩種品質設定。
- 在查看平均品質之前運行文字、物件、安全性和編輯位置門。
- 分別測量語意對齊、物件存在、屬性綁定、空間關係和視覺品質。
- 使用人工審核來進行創意契合度、品牌契合度和邊緣案例。
- 報告信賴區間、效應大小、統計顯著性和註釋者一致性。
- 版本化 prompts、圖像、設定、指標、judge prompts、人類密碼本和腳本。
- 建立了一個儀表板,顯示輸出失敗的原因,而不僅僅是它們失敗了。
簡短版本:使用工作流程門、語意分解、手動審查、統計規則和版本化迴歸來評估 GPT Image 2。不要讓完美的平均分數掩蓋生產失敗。