一套教程式选择框架,帮助你根据图像类型、提示词风险、文字准确性、成本、延迟和生产审核工作量,在 GPT Image 2 与 Gemini 之间做出选择。
GPT Image 2 vs Gemini:一步步选择图像模型的教程
一套教程式选择框架,帮助你根据图像类型、提示词风险、文字准确性、成本、延迟和生产审核工作量,在 GPT Image 2 与 Gemini 之间做出选择。
核心结论
- 选模型时不要凭感觉,按固定清单走:资产类型、失败模式、提示词约束、审核成本和规模。
- 当文字准确性和结构稳定性风险很高时,GPT Image 2 应该优先测试。
- 当速度、探索范围和成本比精确执行提示词更重要时,Gemini 值得优先测试。
- 最终决策要看“被接受资产”的总成本,而不是只看单张生成价格。
第 1 步:先给图像资产分类
在比较 GPT Image 2 和 Gemini 之前,先说清楚你要生成的是什么资产。它是产品图、海报、UI mockup、博客封面、广告创意、生活方式场景、角色概念图,还是一批粗略草稿?这一步能避免一个常见错误:用一个和实际工作不匹配的任务去判断模型好坏。
如果资产里包含嵌入文字、结构化版式、界面元素、产品标签,或者严格的品牌 brief,把它放进“精确型”类别。GPT Image 2 应该先测。如果资产是氛围图、通用背景、宽泛概念或低风险草稿,把它放进“探索型”类别。Gemini 可能是更快的第一轮测试选择。
这个分类故意保持简单。好的模型选择流程应该让市场、设计、开发和内容运营都能使用,而不是把每一次图片请求都变成研究项目。
第 2 步:写下失败模式
每个图像任务都有失败模式。海报的失败可能是标题不可读;UI mockup 的失败可能是层级结构崩掉;产品图的失败可能是标签漂移;生活方式场景的失败可能只是结果太普通。模型选择应该跟着失败模式走。
当失败模式是“精确性”时,GPT Image 2 更强。它更适合那些必须保留文字、对象关系、版式区域或多重约束的提示词。即使单次成本更高,它也可能更有价值,因为进入审核环节的失败输出会更少。
当失败模式是创意方向不足或迭代太慢时,Gemini 更强。如果主要风险是没有足够多方向可选,那么快速变体就很重要。一个能迅速产出很多可用概念的模型,在这个阶段可能是更好的工具。
第 3 步:按模型调整提示词
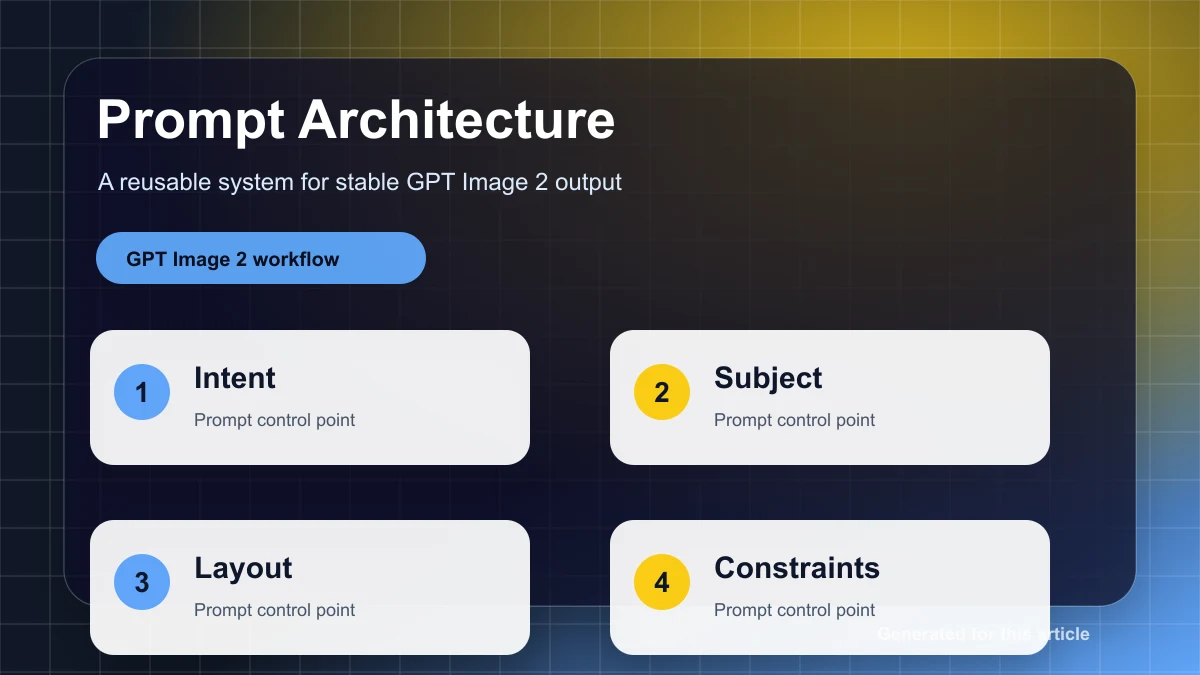
不要用偷懒的提示词去 benchmark 两个模型。公平测试应该用每个模型最擅长处理的指令格式。对 GPT Image 2,使用结构化提示词:画布、主体、版式、必需文字、风格、限制条件和需要避免的内容。目标是得到一个可控候选图。
对 Gemini,如果任务允许,可以使用更探索性的提示词。要求它给出氛围、场景、材质质感、光线方向,或者几个构图可能性。目标是扩展方向。如果某个方向有效,再把它转成下一阶段更严格的提示词。
单是这一步就能明显改善结果。很多所谓模型对比,其实只是提示词对比失败。同一组文字在一个模型里表现很差,在另一个模型里可能很好,因为两个模型期待的指令类型并不相同。
第 4 步:衡量被接受的输出
生成多个候选图,并统计被接受的输出数量。不要只保存最好看的那一张。记录结果达到 brief 要求之前,一共尝试了多少次。这个“被接受输出率”比截图对比有用得多。
对文字密集型提示词,即使单张价格更高,GPT Image 2 也可能减少重试次数。对宽松的写实类提示词,Gemini 可能用更低成本给出足够多可接受选项。胜者会随着资产类型变化,所以路由清单很重要。
还要记录审核时间。一个需要更少修正的模型,即使在 API 或工具界面里看起来更贵,在团队层面也可能更便宜。
第 5 步:决定默认路由
用十到二十个真实提示词测试之后,给任务分配默认路由。文字、UI、包装、图表、对比视觉和品牌敏感图形,默认使用 GPT Image 2。创意发散、高量草稿、情绪板、通用场景,以及最终文字会在设计工具里后加的情况,默认使用 Gemini。
保留例外。复杂的写实产品场景如果标签很重要,仍然可能需要 GPT Image 2。没有文字的简单视觉也未必需要最严格的模型。路由规则应该清晰到可以自动化,同时也要能处理边界情况。
用简单语言记录规则。一个好规则可以写成:“如果文字错误会让资产无法使用,就路由到 GPT Image 2。如果用户需要很多粗略选项且不需要嵌入文字,就先路由到 Gemini。”
第 6 步:模型变化后重新测试
图像模型变化很快。一次做出的选择不应该变成永久基础设施。保留 benchmark 提示词,在重大模型更新后重新运行,并再次比较被接受输出率。这样可以避免旧假设控制新的工作流。
现有对比把 GPT Image 2 显示为强质量领先者,尤其是在那些会惩罚弱提示词遵循能力的视觉任务上。这是一个有意义的起点,但不是停止衡量自己流程的理由。
真正耐用的做法是:一个小型 benchmark、一条清晰路由策略,以及为每个模型单独准备提示词。有了这个系统,GPT Image 2 vs Gemini 就会从反复争论变成可执行的运营选择。
教程决策现场清单
把这篇文章当成工作清单,而不是静态结论。对于 GPT Image 2 vs Gemini:一步步选择图像模型的教程,第一个检查点是图像是否有可衡量的接受条件。可衡量条件可以是一句可读文字、一个固定版式、一个可识别的产品细节、一个必需艺术方向,或者最大重试次数。如果接受条件很模糊,两个模型都可能看起来表现不错,但团队仍然没有可靠的发布规则。
第二个检查点是提示词能不能重复使用。保存精确提示词、模型路径、被接受输出,以及通过的原因。对 GPT Image 2 教程、Gemini 和 AI 图像工作流来说,这个习惯很重要,因为很小的提示词改动也可能造成很大的输出变化。可重复的提示词库能让团队持续改进,而不是每个资产都从直觉重新开始。
第三个检查点是输出能不能直接进入教程的下一步生产流程。如果负责 GPT Image 2 教程的人必须手动重建重要部分,那么这次生成只是草图。它仍然可能有用,但应该按探索任务来定价和路由。当图像只需要轻微编辑就能进入审核,它才属于这篇文章场景里的生产通道。
常见错误
不要拿一张最好的 GPT Image 2 结果和一张最好的 Gemini 结果对比。要比较完整尝试历史。一个需要更少重试的模型,往往是更好的运营选择,即使另一个模型偶尔能生成惊艳的离群结果。对教程类工作流尤其如此,因为团队需要的是可预测吞吐,而不是孤立的展示图。
不要忽略审核者在 GPT Image 2 vs Gemini:一步步选择图像模型的教程里的工作。审核者必须检查文字、主体准确性、版式、政策风险、品牌匹配,以及视觉是否适合发布渠道。能让这些检查更快完成的模型,才为教程创造业务价值。看起来很强但增加不确定性的模型,会制造隐藏成本。
最后,不要让 benchmark 取代教程里的判断。Benchmark 解释从哪里开始;真实提示词解释应该发布什么。把 GPT Image 2 和 Gemini 当成两种运行特征不同的工具,然后建立一条轻量路由,把每个 GPT Image 2 教程请求匹配到最不容易在该场景失败的模型。
发布决策前,针对真实渠道做最后一次 sanity check。博客封面、社交图、电商图片和 UI 概念图的判断环境都不同。对 GPT Image 2 vs Gemini:一步步选择图像模型的教程来说,胜出的模型是那个在图片被缩放、裁切、审核,并放到真实页面文案旁边之后仍然有用的模型。最终落位测试能抓住只看全尺寸生成图时容易漏掉的问题。
记录要短,短到团队真的愿意用。一个有用记录应该包含提示词、模型、尝试次数、被接受图片、拒绝原因和下一步动作。长期看,这些记录会说明 GPT Image 2 vs Gemini:一步步选择图像模型的教程是否指向稳定默认路由,或者团队是否需要为不同图像类别拆分规则。
常见问题
选择 GPT Image 2 和 Gemini 最快的方法是什么?
先给资产分类,写下失败模式,运行五到十个真实提示词,然后比较被接受输出率和审核时间。
什么时候应该默认使用 GPT Image 2?
当错误文字、破碎版式或弱提示词遵循能力会让图片无法使用时,默认使用 GPT Image 2。
什么时候应该默认使用 Gemini?
当任务是情绪板、宽泛创意、通用场景或高量草稿,并且不要求精确嵌入文字时,先使用 Gemini。
应该多久重新测试一次模型?
在重大模型更新后,或者你的工作负载变化时重新测试。保留一小组 benchmark 提示词,这样对比成本会很低。