面向开发者的 GPT Image 2 详解:能力、API 选择、图像编辑、4K 输出、安全防护以及生产工作流决策。
我不断被问到关于 GPT Image 2 的同一个实际问题:"这只是一个更好的图像生成器,还是它能改变我能构建的东西?"
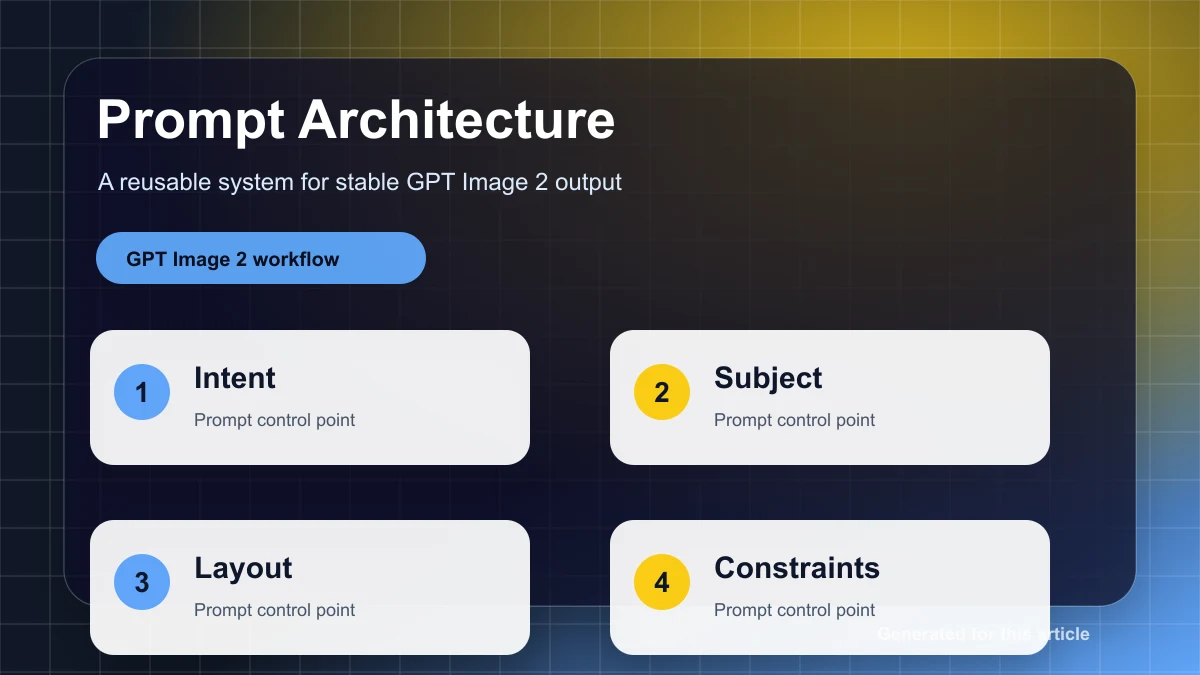
简短的回答:它改变的是工作流层面,而非提示框本身。
更详细的回答:GPT Image 2 之所以重要,是因为 OpenAI 不再将图像生成视为一次性玩具功能。当前的文档和平台资料指向一个支持直接图像生成、图像编辑、多轮视觉工作流、参考输入、局部图像流式传输,以及围绕审核和输出配置的生产控制能力的模型家族。这与让聊天机器人生成一张好看的图片完全是两回事。
注:我在撰写本文时没有运行新的图像基准测试。
这是一份面向开发者的全景图。我将区分哪些是文档已记录的、哪些是微软关于其 Foundry 部署的说法、哪些是第三方解读的主张,以及在将 GPT Image 2 部署到真正的产品按钮之前,我仍然会测试的内容。
什么是 GPT Image 2
截至 2026 年 6 月 7 日,GPT Image 2 是 OpenAI 当前用于图像生成和编辑工作流的 GPT Image 模型。在 OpenAI 开发者指南中,gpt-image-2 作为 Image API 中的可选模型出现,用于图像生成。同一指南还描述了 GPT Image 模型可通过两种方式使用:Image API 和 Responses API 图像生成工具。
这一区别很重要。
Image API 是直接路径。当产品需求简单明了时使用它:用户提供提示词,应用返回图像;或者用户提供图像、遮罩和指令,应用返回编辑结果。
Responses API 是对话路径。当图像生成嵌入多步骤交互中时使用它:用户请求生成图像、修改输出、引用先前的图像,或在同一流程中在文本推理和视觉输出之间切换。
两种方式,不同用途。这就是核心。
已确认的功能
以下是收集到的资料中最清晰的已确认功能。
| 功能 | 状态 | 重要性 |
|---|---|---|
OpenAI 图像生成示例中的 gpt-image-2 模型 ID | OpenAI 已记录 | 开发者可以在 Image API 中直接指定该模型。 |
| 图像生成端点 | OpenAI 已记录 | 适用于具有可预测请求结构的文本到图像工作负载。 |
| 图像编辑端点 | OpenAI 已记录 | 支持编辑现有图像和使用参考图像。 |
| Responses API 图像生成工具 | OpenAI 已记录 | 支持多轮和对话式图像工作流。 |
| 通过 URL、Base64 数据 URL 或文件 ID 输入参考图像 | OpenAI 已记录 | 支持围绕产品照片、品牌素材和视觉参考构建的工作流。 |
| 局部图像流式传输 | OpenAI 已记录 | 允许应用在较长的图像生成过程中显示进度。 |
| 组织验证要求 | OpenAI 已记录 | 团队在使用 GPT Image 模型前可能需要完成账户验证。 |
| 微软 Foundry 可用性 | 微软已声明 | 企业团队可以通过 Foundry 部署 GPT-image-2。 |
这些足以将 GPT Image 2 视为一个真正的集成平台,而非传闻。
但这不足以将所有关于它的主张都视为已验证。资料库中的第三方页面对其文本渲染、人脸一致性、思维模式或优于旧模型等方面提出了更广泛的说法。其中一些说法可能具有方向性参考价值;但在纳入生产决策之前,仍需要针对具体工作负载进行测试。
最重要的能力
文本提示生成
基本功能依然简单:发送提示词,接收图像。OpenAI 示例展示了通过图像生成请求使用 gpt-image-2,并将返回的 Base64 图像解码为文件。
对开发者来说,有用的细节不是"Hello World"级别的演示,而是围绕调用的输出控制:质量、尺寸、格式、压缩、流式传输以及请求的图像数量。
这就是产品默认值变成成本默认值的地方。如果你允许每个用户默认生成多张高分辨率图像,那你做的就不只是用户体验决策,更是定价决策。
编辑和参考图像
编辑端点是更有意思的生产级原语。
OpenAI 的指南将图像编辑描述为使用新提示词修改现有图像的方式,可以是部分修改或完全修改。它还描述了使用一张或多张图像作为参考来创建新图像。示例包括通过 URL、Base64 数据 URL 以及使用 Files API 创建的文件 ID 传递的参考图像。
这开启了真正的工作流模式:
- 从参考产品照片生成产品场景。
- 将多个参考对象组合为一个合成素材。
- 替换背景同时保留主体。
- 在一个视觉方向上迭代而不必从头开始。
- 围绕已批准的参考图像构建品牌素材工作流。
这就是 GPT Image 2 开始看起来更像视觉工作流自动化,而非仅仅是"图像生成"的地方。
多轮图像工作流
通过 Responses API,图像生成可以在对话中进行。指南描述了使用 previous_response_id 或将图像生成调用的输出传回上下文,然后请求后续修改。
当用户体验是迭代式的,这很重要:
- 生成第一版视觉效果。
- 要求生成写实版本。
- 修改其中一个元素。
- 保持其余部分不变。
- 导出最终素材。
你可以用无状态的图像调用来模拟这个过程,但最终需要自己重新构建上下文管理。如果产品体验是对话式的,Responses API 是更合适的选择。
4K 和自定义尺寸
微软的 Foundry 文章指出,GPT-image-2 引入了 4K 分辨率支持和自定义尺寸,最终图像像素预算在 655,360 到 8,294,400 像素之间,尺寸必须是 16 的倍数。文章还指出,超出预算范围的请求会被自动调整大小。
我标注了信息来源,因为这一细节来自微软 Foundry 部署材料,而非资料库中的所有内容。
对生产团队来说,影响很直接:你可以围绕平台特定尺寸设计工作流,而不是生成通用的正方形图像再事后修补。零售缩略图、宽幅社交媒体横幅、广告样稿和 UI 主图有不同的尺寸需求。自定义尺寸减少了下游的清理工作。
多语言和本地化图像
微软还指出,GPT-image-2 扩展了对日语、韩语、中文、印地语和孟加拉语的语言支持,并将此定位为对本地化文本和区域性营销素材有用的功能。
如果这在你的工作负载中经得起考验,那将是一个真正的业务突破。大多数图像模型可以创建一个"看起来像本地化"的场景。但能在图像中可靠地渲染有用的本地语言文字的模型就少得多了。对于全球营销活动,区别在于你手上的是一个草稿还是可以交给本地市场负责人的成品素材。
不过,请自行测试。文本渲染质量因文字系统、字体、图像尺寸和提示词复杂度而异。如果没有人工审核环节,我不会发布多语言广告创意。
Image API 与 Responses API
错误的问题是:"哪个 API 更新?"
正确的问题是:"产品在做什么事情?"
| 产品任务 | 更合适的选择 | 原因 |
|---|---|---|
| 一个提示词,生成一张图像 | Image API | 简单的请求结构和直接的模型选择。 |
| 使用提示词编辑已上传的图像 | Image API | 直接的编辑端点与任务匹配。 |
| 从多张参考图像生成 | Image API 或 Responses API | 直接任务选 Image API;对话流程选 Responses API。 |
| 用户跨多轮修改图像 | Responses API | 多轮上下文管理更清晰。 |
| 智能体决定何时生成或编辑 | Responses API | 图像工具可以成为更广泛推理流程的一部分。 |
| 生产环境批量生成 | Image API | 更容易理解和控制成本及请求行为。 |
如果你正在构建设计助手、创意智能体或营销活动工作流,Responses API 值得承受额外的复杂度。如果你正在构建一个按钮背后的生成端点,从 Image API 开始。
GPT Image 2 与旧图像模型的对比
资料库中有多个与 GPT Image 1、GPT Image 1.5、DALL-E 3、Midjourney、FLUX、Krea 和 Imagen 的旧版和第三方对比。在没有新的并排测试之前,我不会将所有这些合并为一个自信的排名。
可以确定的是:
- GPT Image 2 现在是评估 OpenAI 原生图像生成时应关注的模型名称。
- OpenAI 文档展示了它在生成和编辑示例中的使用。
- 微软的 Foundry 材料将其定位为面向更高分辨率、多语言、真实场景和生产工作流的用例。
- 第三方解读反复指出文本渲染、UI 风格图像生成、指令遵循和编辑一致性是用户最关心的能力。
未经测试我不会断言:
- GPT Image 2 在美学上始终优于 Midjourney。
- 它在每个提示词类别上都超越 FLUX 或 Imagen。
- 它的文本渲染在每种语言中都是完美的。
- 复杂场景中的人脸或角色一致性问题已解决。
- 高分辨率输出在任何情况下都值得其成本。
模型迭代很快。基准测试会过时。你的工作负载才是最重要的基准。
实际用例
如果你想在接入完整 API 工作流之前测试以下想法,GPT Image 2 AI 是一个简单的地方,可以用真实的提示词尝试文本到图像和编辑场景。
带真实文字的营销素材
如果 GPT Image 2 在你的用例中能可靠地渲染文字,营销工作流就会改变。团队不再需要在 Figma 中生成背景再添加文字,而是可以直接生成早期的社交媒体概念、营销活动样稿、邮件头图或包含文案的广告变体。
我仍然会保留设计审核环节。但从草稿到审核的周期会更短。
产品和电商视觉素材
参考图像工作流对产品团队很有用。一张产品照片可以成为生活场景、对比图、包装样稿或平台特定缩略图的锚点。
这里的规则很简单:保持产品不变,变换场景上下文。不要指望模型凭记忆猜测你的 SKU 细节。
UI 和应用概念样稿
多篇文章指出 GPT Image 2 在 UI 风格的视觉效果和截图方面很有用。将它视为原型工具,而非设计系统的替代品。
用它来探索方向、展示界面或为文档配图。不要将生成的 UI 文字、控件或数据视为生产环境的真实内容而不加审核。
教育和技术图表
更强的指令遵循、参考输入和文本渲染的结合,使得技术图表比早期图像模型更可行。但图表在看起来很权威却包含微妙错误时是很危险的。
如果你将 GPT Image 2 用于教育领域,请添加专业审核。一张漂亮但错误的图表比没有图表更糟糕。
多市场创意运营
多语言能力是最有趣的企业用例之一。全球团队可以针对不同市场、语言、尺寸和视觉风格请求相同的营销活动概念。
这并不能取代本地审核。它让本地审核更早发生,并且基于更具体的素材。
开发者不应跳过的生产注意事项
上线前有三件事很重要。
第一,审核。OpenAI 的图像生成栈包含安全控制,资料库中多次提醒生成的图像可能带来版权、伪造文件和冒充风险。对于用户提交的提示词,在生成前添加提示词审核,在将涉及政策敏感的输出发布到公开页面之前进行审查。
第二,日志记录。记录模型 ID、请求 ID、提示词、尺寸、质量、延迟、审核结果、可用时的 token 或成本字段,以及图像是生成的、编辑的、重试的还是被拒绝的。如果成本或安全成为问题,这些就是你需要的数据。
第三,默认值。尺寸、质量、输出数量和重试策略都是产品决策。一个随意的默认值可能变成昂贵的生产习惯。
我的开发建议
从窄处开始。
选择一个 GPT Image 2 应该明显有用的工作流:产品主图、本地化社交媒体视觉素材、UI 概念图、文档图表或基于参考的编辑。定义一个小型验收测试。包含文本渲染、编辑稳定性、成本、延迟和人工审核时间。
然后将它与你已经在用的工作流进行比较。不是与排行榜比较,而是与你当前的流程比较。
在以下情况下选择 GPT Image 2:
- 你需要在 API 工作流中使用 OpenAI 原生图像生成。
- 提示词准确性和视觉指令遵循很重要。
- 你需要在同一产品界面中实现生成和编辑。
- 你希望通过 Responses API 进行多轮图像迭代。
- 你的团队能够处理审核、日志记录和审查。
在以下情况下需要谨慎:
- 你需要在所有任务中保证透明背景输出。
- 你需要完美的人物或角色一致性且不经过审核。
- 你只针对艺术风格进行优化。
- 你无法容忍审核失败、重试或可变的生成延迟。
- 你尚未按预期的图像量建模成本。
从一个受控的试点开始:一个用例、一种输出尺寸、一个质量默认值、一份审核清单和一份成本日志。如果 GPT Image 2 在质量、编辑稳定性、审核时间和成本上优于你当前的工作流,再扩展集成。
要进行低成本的首次尝试,可以在 GPT Image 2 AI 上用相同的提示词或编辑简报进行测试,然后再投入工程时间构建完整的 API 工作流。
我无法从资料库中验证的内容
我没有为本文运行新的基准测试。
我没有独立验证第三方关于文本渲染、人脸一致性或与 Midjourney、FLUX、Imagen 或 Krea 各项对比的说法。
我也不建议将各平台的价格信息视为可互换的。OpenAI API 定价、微软 Foundry 定价和第三方平台定价在结构和时间上可能存在差异。在做出预算承诺之前,请使用当前提供商的文档。
常见问题
GPT Image 2 是否可通过 OpenAI API 使用?
是的。OpenAI 开发者指南展示了 gpt-image-2 在 Image API 中用于生成的用法。它还描述了通过 Responses API 图像生成工具使用 GPT Image 工作流的方式。
应该使用 Image API 还是 Responses API?
对于直接的生成和编辑任务,使用 Image API。当图像生成是多轮或智能体对话的一部分,用户可能在多个步骤中修改图像时,使用 Responses API。
GPT Image 2 是否支持 4K 输出?
微软的 Foundry 文章指出,GPT-image-2 支持 4K 分辨率和在定义的像素预算范围内的自定义尺寸。如果你的部署目标不是微软 Foundry,请在你当前提供商的文档中确认具体限制。
GPT Image 2 能在图像中渲染文字吗?
文本渲染是资料库中讨论最多的 GPT Image 2 能力之一,微软也强调了其多语言理解能力。我建议将可靠的文本渲染作为一个关键测试用例,而非普遍保证。请针对你计划发布的具体语言、字体样式和图像尺寸进行测试。
GPT Image 2 是否安全用于生产环境中的用户生成内容?
它可以成为生产系统的一部分,但必须配备防护措施:提示词审核、敏感页面的输出审查、日志记录、速率限制处理,以及围绕冒充、伪造文件、受版权保护的风格和品牌使用的明确政策。
最佳的首次 GPT Image 2 试点是什么?
选择一个有明确验收标准的工作流:产品图片变体、本地化社交媒体素材、基于参考的编辑或文档图表。在大规模推广之前,衡量质量、编辑稳定性、延迟、成本和人工审核时间。
总结
GPT Image 2 最好被理解为一个工作流模型,而不仅仅是一个更好看的图像生成器。
已确认的 API 层面已经支持生成、编辑、参考图像、多轮流程和流式传输。微软的 Foundry 材料补充了面向生产的 4K、多语言和路由能力图景。第三方解读指向更强的文本渲染和指令遵循能力,但这些说法仍值得你自己去验证。
先运行小型试点。那会比另一个模型排名告诉你更多。