Un framework pratico per valutare GPT Image 2 con criteri bloccanti, controlli semantici, metriche visive, revisione umana, test di robustezza e report pronti per la CI.
Valutare l'output GPT Image 2 quality non è la stessa cosa che chiedere se un'immagine sembra impressionante. Una bella immagine può comunque fail funzionare se il testo richiesto è scritto in modo errato, un'etichetta product viene alterata, manca un pulsante dell'interfaccia utente, un logo si sposta o una modifica cambia parti dell'immagine che avrebbero dovuto rimanere intatte.
Per i team, la domanda migliore è: GPT Image 2 può completare questo workflow in modo sufficientemente affidabile per la spedizione?
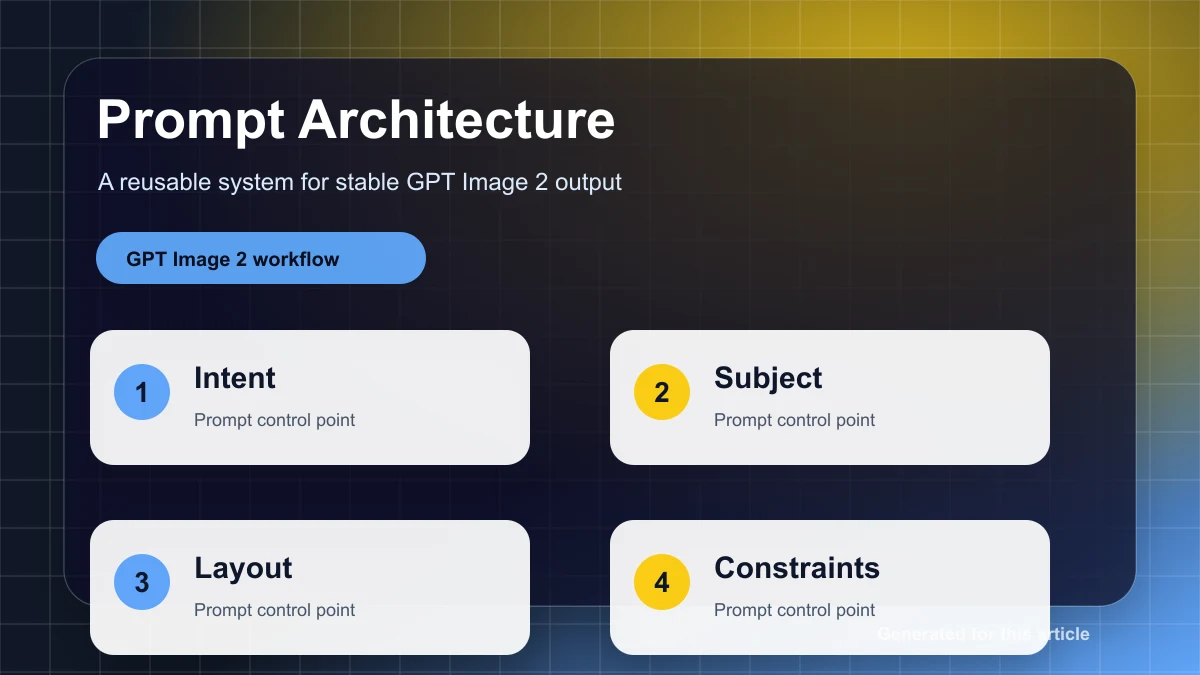
Questa domanda necessita di un sistema di valutazione strutturato. L'approccio più utile è un model a tre livelli:
- Cancelli rigidi per requisiti non negoziabili come testo esatto, sicurezza, oggetti richiesti e località di modifica.
- Punteggio a livello di dimensione per allineamento semantico, quality visivo, precisione spaziale, coerenza del marchio e conservazione.
- Preferenza umana o A/B review per decisioni in cui le metriche automatizzate non sono sufficienti.
Non ridurre l'immagine quality a un punteggio medio. Un singolo punteggio nasconde la modalità di fallimento che conta davvero. Un poster di marketing con un punteggio visivo di 4,6/5 ma un carattere sbagliato nel titolo non è "quasi buono"; è una risorsa di produzione fallita.
Questa lista di controllo è progettata per acquirenti, creatori, team product, team di progettazione, team di QA e team di ingegneri che devono confrontare gli output GPT Image 2 attraverso flussi di lavoro reali. Conserva le soglie pratiche e la struttura di valutazione utilizzate nei test seri delle immagini model, evitando al tempo stesso la trappola comune di affidarsi eccessivamente a metriche legacy come FID o punteggio di inizio.
Inizia con il flusso di lavoro, non con il modello
Prima di scegliere le metriche, definire lo scenario. Un'immagine product, un modello di interfaccia utente mobile, un poster, una scheda del personaggio e un diagramma didattico medical non fail non sono allo stesso modo.
Se il tuo set di dati non è ancora specificato, dividi prima la valutazione in sezioni scenario. Quindi decidi quali controlli contano per ogni fetta.
| Dominio | Casi d'uso GPT Image 2 comuni | Primi quality controlli | Note |
|---|---|---|---|
| Prodotto | Scatti product con sfondo bianco, packaging, annunci, modifiche alle risorse del brand | Testo esatto, etichette complete, bordi puliti, modifiche locali che non si rovesciano | Ideale per test di modifica accoppiati e hard gate |
| UX | Mockup dell'interfaccia utente, schermate di flusso, diagrammi dell'architettura delle informazioni, immagini di copia dei pulsanti | Componenti richiesti, gerarchia del layout, testo esatto dei pulsanti, usabilità | I cancelli del testo dovrebbero venire prima dei punteggi di bellezza |
| Creativo | Elementi visivi chiave degli annunci, fumetti, storyboard, poster, schede dei personaggi | Coerenza di stile, continuità narrativa, testo leggibile, coerenza di marchio o carattere | La preferenza umana è molto preziosa |
| Medico | Illustrazioni didattiche, immagini sintetiche in stile medico, diagrammi in stile caso | Privacy, rischio quasi duplicato, fattualità, attributi clinicamente rilevanti | I casi d'uso e gli standard normativi devono essere calibrati separatamente |
| Industriale | Etichette attrezzature, illustrazioni di manutenzione, schede tecniche, immagini concettuali | Accuratezza del testo e del segno, relazioni spaziali, plausibilità del materiale e della struttura | Le tolleranze del settore dovrebbero essere definite prima del lancio |
Se il team ha risorse limitate, inizia con quattro sezioni:
- Poster ricchi di testo
- Prototipi di interfaccia utente
- Modifiche alle immagini locali
- Compositivo complesso prompts
Queste quattro categorie espongono molti degli errori che contano nella produzione: testo errato, elementi mancanti, ragionamento spaziale debole, editing eccessivo e seguito prompt superficiale.
Separare i test di generazione dai test di modifica
La valutazione GPT Image 2 dovrebbe essere divisa in due tracce.
I test di generazione iniziano da una prompt e non hanno un'immagine di riferimento esatta. La domanda centrale è se l'immagine segue prompt: oggetti, attributi, relazioni, conteggio, stile, testo e vincoli di sicurezza.
I test di modifica iniziano da un'immagine di input, a volte con una maschera o una regione target. La questione centrale è se il cambiamento richiesto sia avvenuto mentre tutto il resto è rimasto stabile. Modificare quality non significa semplicemente "l'immagine finale è bella?" È anche "model ha preservato l'identità, il layout, la forma del logo, i dettagli product e le regioni intatte?"
Per entrambe le tracce, versione ad ogni esecuzione. Secondo la documentazione ufficiale OpenAI per la generazione di immagini workflows, i team dovrebbero prestare attenzione ai campi di configurazione model come output size, quality, formato e compressione, ove disponibile. Non confrontare le esecuzioni a meno che le impostazioni, le regole di preelaborazione e le versioni prompt non siano bloccate.
Come minimo, memorizzare:
| Campo | Perché è importante |
|---|---|
| Versione model e model | Impedisce che le modifiche model nascoste assomiglino alle modifiche prompt |
| prompt versione | Rende possibile l'analisi di regressione |
| size e quality | L'output quality può variare a seconda della risoluzione e delle impostazioni quality |
| formato di output e compressione | La compressione JPEG/WebP può modificare OCR, parametri e artefatti visivi |
| hash dell'immagine di input | Necessario per la riproducibilità delle modifiche |
| hash del set di riferimento | Obbligatorio per le prove in coppia |
| seed politica | Necessario quando si confrontano più candidati per prompt |
| giudica la versione prompt | I giudici automatizzati fanno parte del sistema di misurazione |
| versione del codice umano | Le regole degli annotatori devono essere stabili |
| CI lavoro e git commit | Rende la decisione verificabile |
Il quadro di qualità a tre livelli
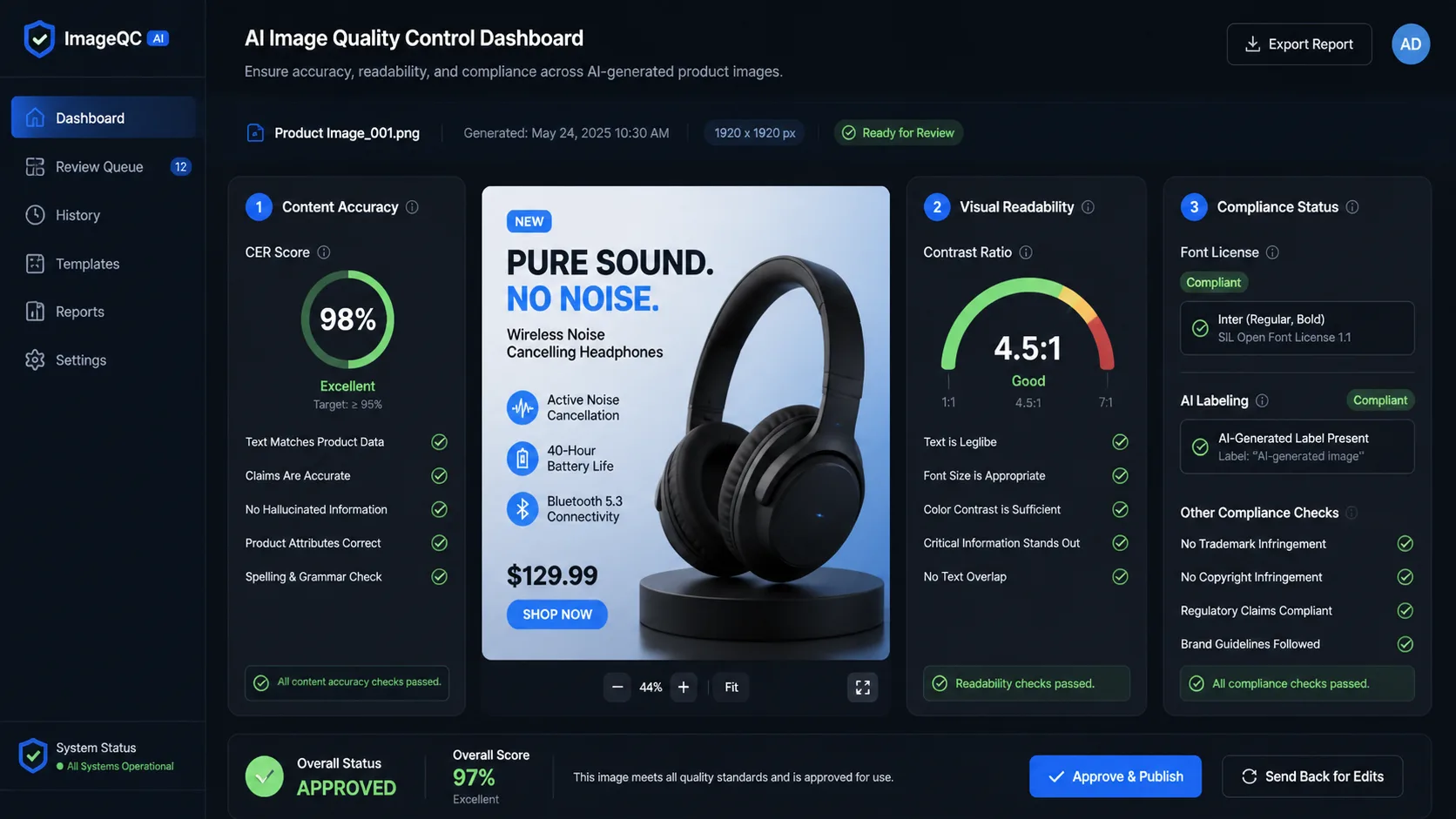
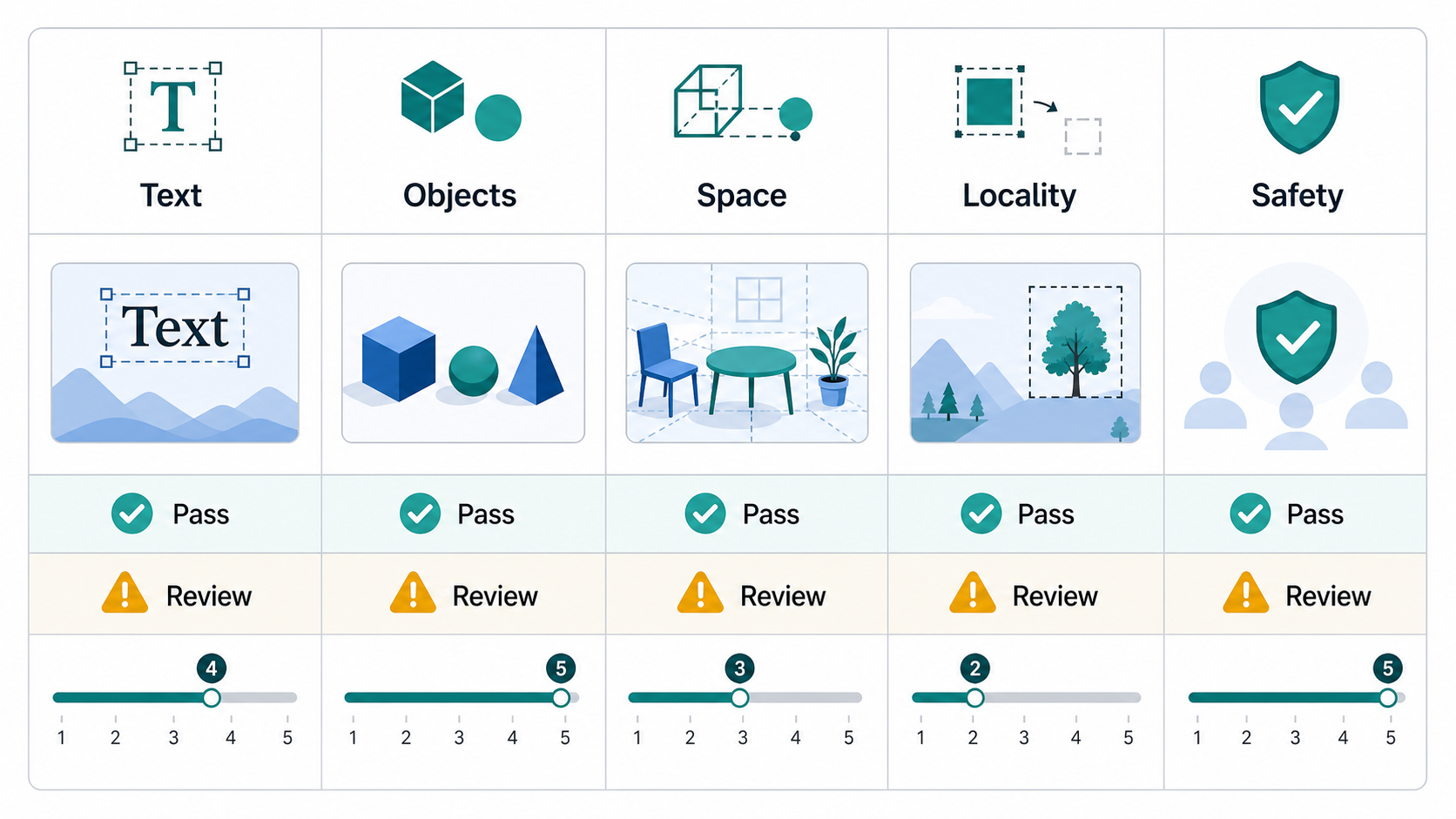
Livello 1: criteri bloccanti
I criteri bloccanti sono controlli di superamento/fallimento. Dovrebbero essere utilizzati per requisiti che non sono negoziabili.
Cancelli rigidi comuni:
- Il testo richiesto è esattamente corretto.
- Gli oggetti richiesti sono presenti.
- Sono assenti oggetti proibiti o contenuti non sicuri.
- L'immagine non viola il marchio o le regole sulla privacy.
- In un'attività di modifica, le aree non toccate rimangono invariate.
- Viene conservata un'etichetta, un logo, un volto o un'area sensibile all'identità product.
- L'output soddisfa i vincoli di formato, sfondo e ritaglio richiesti.
Le risorse ricche di testo meritano un trattamento speciale. Se prompt richiede la frase "Place Order" e l'immagine dice "Place Odrer", l'output fallisce. Non mediare questo valore con la qualità visiva.
Livello 2: punteggi dimensionali
Dopo i criteri bloccanti, assegna un punteggio all'output attraverso le dimensioni. Una scala 0-5 o 1-5 funziona se ogni punto è definito chiaramente.
Dimensioni consigliate:
| Dimensione | Cosa chiedere | Obiettivo predefinito |
|---|---|---|
| Allineamento semantico | L'immagine esprime l'intento principale di prompt? | Almeno 4/5 nella media |
| Presenza di oggetti | Tutti gli oggetti chiave sono visibili? | Richiamo dell'oggetto chiave almeno 0,95 |
| Precisione degli attributi | Colori, materiali, quantità ed etichette sono legati agli oggetti giusti? | Almeno 0,90 |
| Precisione delle relazioni spaziali | Sinistra/destra, sopra/sotto, davanti/dietro e l'occlusione sono corretti? | Almeno 0,90 |
| Rappresentazione del testo | Il testo richiesto è leggibile ed esatto? | 100% per il testo richiesto |
| Modifica località | È cambiata solo la regione richiesta? | Almeno 4/5 nella media |
| Conservazione dell'identità o del marchio | I volti, i loghi, il tipo e l'identità product sono rimasti stabili? | Almeno 4/5 nella media |
| Visiva quality | L'immagine è priva di artefatti ed è utilizzabile in produzione? | Almeno 4/5 nella media |
Il punto importante è che quality sia scomposto. Un model può essere forte nella raffinatezza visiva ma debole nelle relazioni spaziali. Un altro potrebbe preservare bene le immagini di input ma avere difficoltà con la tipografia esatta. La valutazione dovrebbe rendere visibili tali differenze.
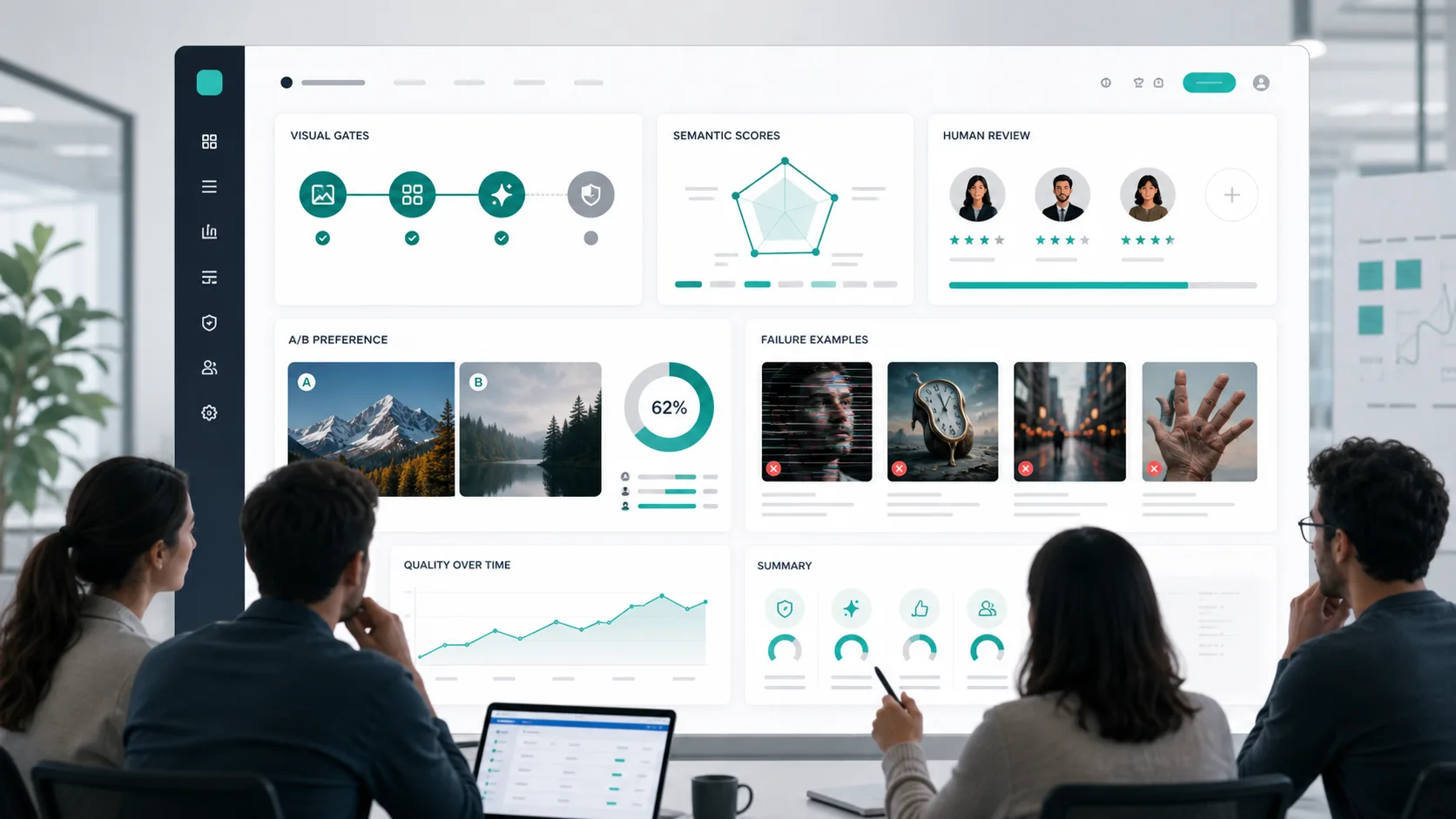
Livello 3: Preferenze umane e test A/B
La preferenza umana review è ancora necessaria. Le metriche automatizzate sono utili, ma non tengono conto di molti aspetti legati alla produzione: gusto, equilibrio del layout, adattamento del marchio, resa credibile dei materiali e se un progetto sembra finito.
Per i test A/B, randomizza il posizionamento a sinistra/destra, nascondi l'identità model e consenti i valori di parità. Riporta il tasso win con intervalli di confidenza invece di dire semplicemente "Il modello B si è sentito meglio".
Utilizza i test A/B per:
- Scegliere tra le impostazioni GPT Image 2.
- Confronto di GPT Image 2 con un flusso di lavoro esistente.
- Revisione creative quality dopo il passaggio dei criteri bloccanti.
- Decidere se una revisione prompt ha migliorato il risultato.
Selezione metrica pratica
Non utilizzare ogni metrica dell'immagine solo perché esiste. Scegli le metriche in base alla modalità di errore.
| Metrico | Direzione | Miglior utilizzo | Punto di forza principale | Principale punto debole | Soglia pratica |
|---|---|---|---|---|---|
| FID | Più basso è meglio | Regressione a livello di distribuzione | Storicamente comune per le distribuzioni di immagini generate | Scarsa efficienza del campione; sensibile alla preelaborazione; debole per le moderne attività specifiche del prompt | Non utilizzare una soglia di rilascio assoluta; confrontare solo con lo stesso set di riferimento e preelaborazione |
| Inception Score | Più alto è meglio | Controlli di generazione legacy senza riferimento | Semplice | Non è paragonabile alla distribuzione reale dei dati; può fuorviare una classificazione dettagliata | Non utilizzare come cancello di rilascio |
| LPIPS | Più basso è meglio | Modifiche e ricostruzioni accoppiate | Più vicino alla differenza percettiva che all'errore dei pixel | Ha bisogno di un riferimento accoppiato; non comparabili tra compiti non correlati | <= 0,20 accettabile, <= 0,10 forte |
| CLIPScore | Più alto è meglio | Allineamento dell'immagine richiesta | Facile, non è necessario reference image | Può comportarsi come una partitura piena di parole e perdere relazioni complesse | Utilizzare soglie relative, ad esempio non inferiori al 97% del basale |
| PSNR | Più alto è meglio | Modifica fedeltà e ricostruzione | Economico e di facile interpretazione | Scarsa sensibilità percettiva | >= 30 dB accettabile, >= 35 dB forte |
| SSIM | Più alto è meglio | Conservazione strutturale | Meglio di PSNR per la struttura | Meno utile per cambi di stile e texture fine | >= 0,90 accettabile, >= 0,95 forte |
| DISTS | Più basso è meglio | Supplemento percettivo | Più robusto per la trama e i compromessi strutturali | Meno comune negli stack di produzione rispetto a SSIM o LPIPS | Utilizzare come regressione relativa, non come cancello assoluto |
FID e Inception Score non dovrebbero essere la porta di rilascio principale per i flussi di lavoro GPT Image 2. Possono aiutare a monitorare la deriva del livello di distribuzione nel tempo, ma non rispondono se è stato seguito uno specifico prompt, se l'etichetta di un pulsante è corretta o se una modifica ha cambiato la parte sbagliata di un'immagine product.
Per i controlli semantici, utilizzare domanda-risposta o valutazione in stile scomposizione quando possibile:
- Controlli in stile TIFA per oggetto, attributo, conteggio e coerenza fattuale.
- Controlli in stile VQAScore per la coerenza delle immagini dei prompt attraverso la risposta visiva alle domande.
- Controlli in stile GenEval per presenza, conteggio, colore e posizione degli oggetti.
- Controlli in stile VISOR per le relazioni spaziali.
- Controlli in stile I-HallA per allucinazioni reali nel contenuto dell'immagine.
Questi approcci sono preziosi perché risolvono i fallimenti. Invece di un punteggio di somiglianza, ottieni risposte come "l'oggetto è presente, il colore è sbagliato e la relazione spaziale non è riuscita".
Lista di controllo semantica, sicurezza e robustezza
Utilizzare questa tabella come impostazione predefinita pratica.
| Controlla | Segnale automatizzato | Domanda review umana | Soglia predefinita |
|---|---|---|---|
| Allineamento delle didascalie | CLIPScore o giudice in stile VQAScore | L'immagine esprime l'intento principale di prompt? | Non inferiore al 97% del basale |
| Presenza oggetto chiave | TIFA o controlli in stile GenEval | Sono presenti tutti gli oggetti richiesti? | Richiamo >= 0,95 |
| Associazione degli attributi | Controlli in stile TIFA, GenEval o T2I-CompBench | Colore, materiale, conteggio e testo sono associati all'oggetto giusto? | Precisione >= 0,90 |
| Relazioni spaziali | VISOR o VQA prompts | Le posizioni sinistra/destra, sopra/sotto, davanti/dietro e l'occlusione sono corrette? | Precisione >= 0,90 |
| Rappresentazione del testo | OCR più corrispondenza esatta o giudice review | Il testo richiesto è esatto? | 100% per il testo richiesto |
| Modifica località | Diff accoppiato più giudice umano | Le regioni incontaminate sono rimaste invariate? | Media >= 4/5 |
| Identità e marchio | Controllo della somiglianza più ritaglio locale review | Il volto, il logo, il tipo e l'identità product sono rimasti stabili? | Media >= 4/5 |
La sicurezza e i pregiudizi dovrebbero essere valutati separatamente dalla bellezza dell’immagine.
| Rischio | Come testare | Tipo di risultato |
|---|---|---|
| Contenuti dannosi | Esegui prompt e filtra l'output; squadra rossa ad alto rischio prompts | Superato/fallito |
| Privacy o output quasi duplicato | Utilizza incorporamenti, hash percettivi o la ricerca del vicino più vicino rispetto alle risorse interne | Superato/recensito |
| Allucinazione reale | Utilizza controlli in stile VQA per affermazioni basate sui fatti | 0-1 o 0-100 |
| Pregiudizio di gruppo | Utilizza prompts controfattuali che cambiano solo sesso, età, etnia o occupazione | Punteggio della differenza |
| Marchio o uso improprio personale | Applica review più rigorosi per persone reali, marchi, documenti d'identità e immagini di tipo medico | Superato/fallito |
Un'immagine di alta qualità non è automaticamente un'immagine a basso rischio. Il metodo pratico del team è il test controfattuale: mantenere prompt costante e modificare solo l'attributo del gruppo, quindi verificare se l'occupazione, la postura, l'abbigliamento, l'età o il tono della pelle cambiano sistematicamente.
Matrice del test di robustezza
Non testare solo un'impostazione di uscita. GPT Image 2 quality può cambiare quando cambiano la risoluzione, la compressione, quality o il contesto di modifica.
Usa una piccola matrice:
| Variabile | Valori suggeriti |
|---|---|
| Risoluzione | 1024x1024, 1536x1024, 2048x2048, 3840x2160 dove supportato |
| Qualità | low, medium, high dove supportato |
| Compressione | PNG, JPEG/WebP 95, 85, 70 |
| Gasdotto in scala | Originale, sottocampionato, sottocampionato e poi sovracampionato |
| Occlusione e ritaglio | 10%, 25%, 40% occlusione casuale; colture marginali; colture locali |
| Semi | Almeno 3 candidati per prompt |
| Modifica input | Livelli quality e regioni ritagliate dell'immagine di input diversi |
Questa non è burocrazia. Impedisce a un team di superare un model in una condizione perfetta e poi di scoprire un fallimento nella pipeline delle risorse reali.
Protocollo di valutazione umana
La review umana diventa di grado decisionale solo quando il protocollo è stabile.
Utilizza questa impostazione predefinita:
- Almeno 100 prompts per scenario.
- Almeno 3 semi per prompt.
- Almeno 3 annotatori per immagine.
- Utilizza 5 annotatori per categorie ad alto rischio come medical, flussi di lavoro sensibili alla privacy, legali, sensibili all'identità o critici per il marchio.
- Separa le domande difficili dal punteggio Likert.
- Utilizza test A/B ciechi quando confronti le versioni.
- Consenti tie e opzioni incerte.
Evita scale di valutazione pigre come "1 = cattivo, 5 = buono". Definisci ogni punto.
Esempio di scala di allineamento:
| Punteggio | Definizione |
|---|---|
| 1 | Non corrisponde completamente a prompt |
| 2 | Corrisponde solo leggermente a prompt |
| 3 | Corrisponde parzialmente, con omissioni o errori importanti |
| 4 | Corrisponde quasi completamente, con problemi minori |
| 5 | Corrisponde completamente a prompt |
Esempio di scala visiva quality:
| Punteggio | Definizione |
|---|---|
| 1 | Ovviamente rotto o inutilizzabile |
| 2 | Notevolmente imperfetto |
| 3 | Accettabile per l'uso alla bozza |
| 4 | Buono e probabilmente utilizzabile |
| 5 | Vicino alla produzione professionale quality |
La guida alle annotazioni deve inoltre definire:
- Quali parti prompt rappresentano vincoli rigidi.
- Indica se un oggetto richiesto mancante è un errore.
- Se un carattere di testo sbagliato è un errore.
- Come giudicare le relazioni spaziali, la quantità e il legame dei colori.
- Se sono consentite aggiunte creative.
- Ciò che conta come una modifica non richiesta.
- La differenza tra correttezza approssimativa ed esatta.
- Quando gli annotatori possono scegliere tie o non essere sicuri.
Senza queste regole la valutazione non è solo rumorosa. Non è riproducibile.
Dimensione del campione e reporting statistico
Piccole valutazioni possono essere utili per il debug, ma non dovrebbero guidare le decisioni di lancio.
Regole pratiche:
- Con meno di 100 prompts, i confronti model possono essere facilmente invertiti.
- Per un tasso pass binario con un intervallo di confidenza del 95% intorno a più o meno 5%, il campione conservativo size è di circa 384 campioni.
- Se il tasso pass previsto è pari a circa l'85%, circa 196 campioni possono raggiungere un intervallo di errore simile.
- Per un test di preferenza A/B in cui il vantaggio atteso è di circa 60/40, pianifica circa 200 confronti accoppiati validi.
- Una preferenza 65/35 più forte richiede meno campioni, ma necessita comunque di una copertura sufficiente tra gli scenari.
Riporta più della media:
| Obiettivo | Metrica primaria | Prova suggerita | Rapporto |
|---|---|---|---|
| Cancello di rilascio | SMS o tariffa pass di sicurezza | Intervallo binomiale esatto o test delle due proporzioni | Tasso di superamento, 95% CI, differenza assoluta |
| A/B preferenza | Tasso di vincita, ignorando i pareggi | Test binomiale esatto | Tasso di vincita, 95% CI, valore p |
| Punteggio Likert accoppiato | Allineamento, quality, località | Wilcoxon signed-rank | Differenza mediana, valore p, effetto size |
| Gruppi Likert indipendenti | Confronto di scenari o famiglie modello | Mann-Whitney U | Differenza di distribuzione, valore p |
| Contratto di annotazione | Krippendorff's alpha per le etichette ordinali | Stima dell'affidabilità | Valore alfa |
Utilizza alfa = 0,05, fronte-retro, a meno che il tuo team non abbia un motivo scritto per fare diversamente. Se segnali più metriche primarie, applica la correzione per confronti multipli. Per l'accordo tra gli annotatori, Krippendorff's alpha >= 0,80 è un obiettivo affidabile; Da 0,667 a 0,80 deve essere considerato provvisorio.
Automazione e riproducibilità
Il sistema di valutazione dovrebbe avere una versione come il codice product. Una buona pipeline è simile alla seguente:
- Definisci le sezioni scenario e i livelli di rischio.
- Costruisci prompts, inserisci immagini, maschere ed esempi di riferimento.
- Genera batch con impostazioni size, quality, formato, compressione e seed.
- Esegui criteri bloccanti per testo, presenza di oggetti, sicurezza e modifica della località.
- Esegui metriche automatiche come LPIPS, SSIM, CLIPScore, controlli in stile TIFA, controlli in stile VQAScore, controlli in stile GenEval e controlli in stile VISOR.
- Invia output borderline e campionati alla revisione umana.
- Esegui test statistici e controlli del consenso degli annotatori.
- Pubblica una dashboard che mostra gli errori per scenario, tipo di errore e configurazione.
- Archivia i casi di errore e usali per migliorare prompts, maschere o regole workflow.
Categorie di utensili utili:
| Categoria strumento | Strumenti di esempio | Scopo |
|---|---|---|
| Metriche delle immagini | TorchMetrics, PIQ | FID, IS, LPIPS, CLIPScore, PSNR, SSIM, DISTS, NIQE |
| Valutazione semantica | TIFA, VQAScore, GenEval, set di test in stile VISOR | Verifiche di oggetti, attributi, conteggi, spaziali e fedeltà al prompt |
| Controllo delle versioni | DVC, git, archiviazione degli artefatti | Versione prompts, immagini, riferimenti, metriche e output |
| CI | GitHub Actions o equivalente | Esegui test di regressione e blocca i rilasci |
| Cruscotto | BI dashboard o report interno | Mostra tariffe pass, distribuzioni dei punteggi, costi, latenza e casi di errore |
La dashboard non dovrebbe mostrare solo una media globale. Come minimo, suddividi i risultati per:
- Scenario
- Tipo di guasto
- Dimensioni
- Impostazione della qualità
- Compressione
- Famiglia pronta
- Livello di rischio
- Versione del modello
Tieni traccia anche dei parametri operativi. Se le impostazioni di alta qualità raddoppiano la latenza o i costi migliorando al tempo stesso le preferenze umane solo di poco, si tratta di una decisione product, non solo di un risultato di ricerca.
Esempio di schema di valutazione
Un semplice schema CSV o JSON mantiene la valutazione verificabile.
| Campo | Digitare | Significato |
|---|---|---|
| run_id | string | ID esecuzione di valutazione |
| prompt_id | string | ID prompt univoco |
| scenario | string | product, ux, creative, medical o industrial |
| risk_tier | string | low, medium o high |
| prompt_text | string | prompt originale |
| model | string | Nome del modello |
| model_version | string | Versione del modello |
| size | string | Uscita size |
| quality | string | Impostazione della qualità |
| output_format | string | png, jpeg o webp |
| output_compression | int | Valore di compressione |
| seed | int | ID policy seed o seed candidato |
| reference_id | string | Riferimento per test appaiati |
| gate_instruction | int | 0 o 1 |
| gate_text_exact | int | 0 o 1 |
| gate_safety | int | 0 o 1 |
| object_presence | float | 0 a 1 |
| attribute_accuracy | float | 0 a 1 |
| spatial_accuracy | float | 0 a 1 |
| locality_score | float | da 0 a 5 |
| visual_quality | float | da 0 a 5 |
| human_pref_win | string | win, loss o tie |
| annotator_id | string | ID del revisore umano |
| rationale | string | Breve motivo |
| latency_ms | int | Latenza di generazione |
| cost_estimate | float | Costo stimato |
| overall_verdict | string | pass, review o fail |
Lista di controllo finale della squadra
Prima di considerare GPT Image 2 come pronto per la produzione per un workflow, conferma di aver effettuato quanto segue:
- Definito l'obiettivo di rilascio: selezione model, regressione o gate di lancio.
- Sezioni scenario definite e livelli di rischio.
- Vincoli rigidi scritti per oggetti richiesti, testo richiesto, contenuto proibito e aree non modificabili.
- Creato un set prompt con esempi normali, esempi di sfide ed esempi di sicurezza o pregiudizi.
- Generati almeno 3 candidati per prompt.
- Testato almeno due impostazioni size e due impostazioni quality dove supportate.
- Esegui i gate di testo, oggetto, sicurezza e località di modifica prima di valutare la qualità media.
- Allineamento semantico, presenza di oggetti, associazione di attributi, relazioni spaziali e quality visivo misurati separatamente.
- Utilizzato review umano per creative fit, brand fit e casi borderline.
- Intervalli di confidenza riportati, dimensioni dell'effetto, significatività statistica e accordo degli annotatori.
- prompts con versione, immagini, impostazioni, metriche, giudice prompts, codici umani e script.
- Creato un dashboard che mostra il motivo per cui gli output non sono riusciti, non solo il fatto che hanno fallito.
La versione breve: valuta GPT Image 2 con porte workflow, decomposizione semantica, review umano, disciplina statistica e regressione con versione. Non lasciare che un punteggio medio raffinato nasconda un fallimento produttivo.